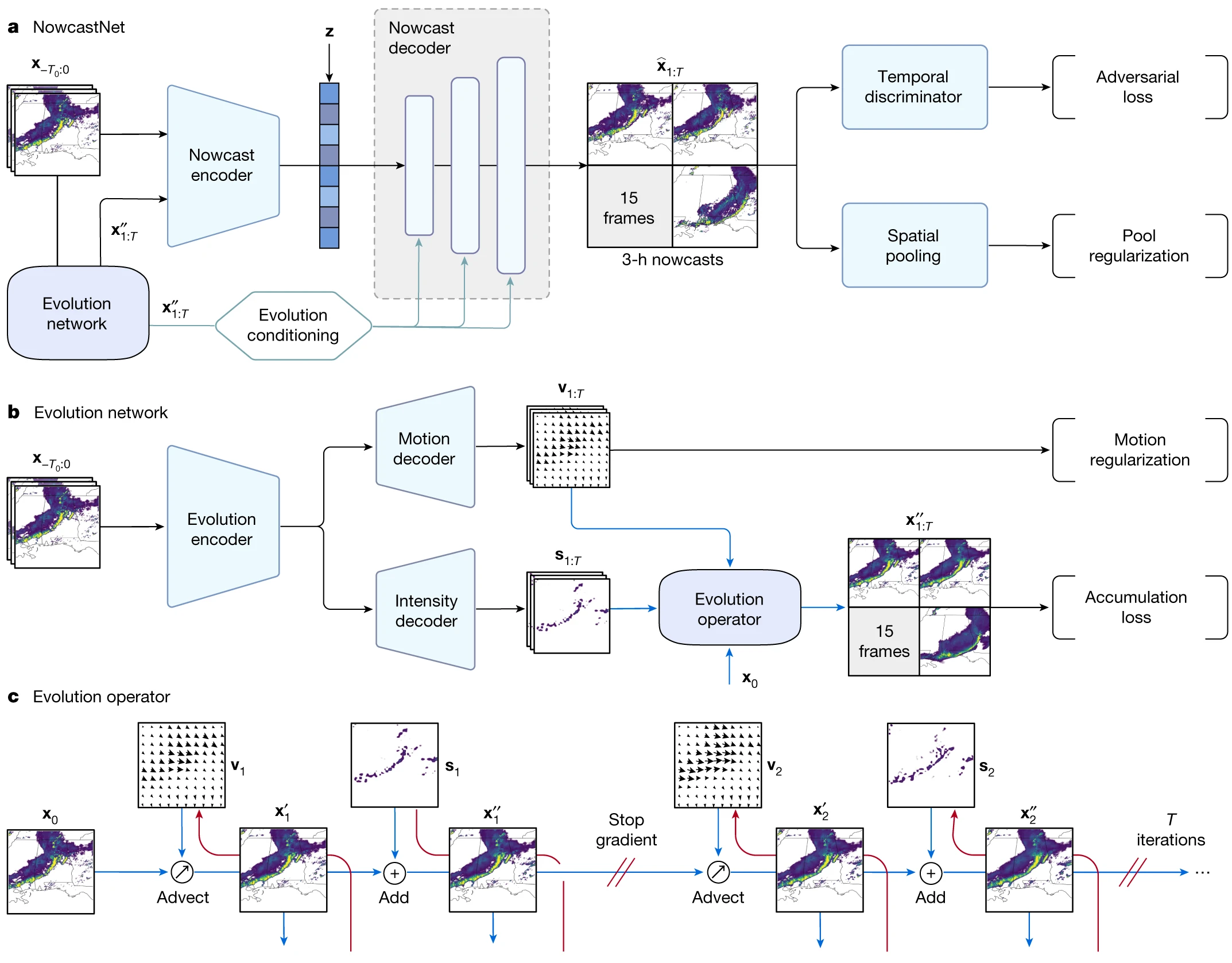
"""
Reference: https://codeocean.com/capsule/3935105/tree/v1
"""
from os import path as osp
import hydra
import paddle
from omegaconf import DictConfig
import ppsci
from ppsci.utils import logger
def train(cfg: DictConfig):
print("Not supported.")
def evaluate(cfg: DictConfig):
# set random seed for reproducibility
ppsci.utils.misc.set_random_seed(cfg.seed)
# initialize logger
logger.init_logger("ppsci", osp.join(cfg.output_dir, "train.log"), "info")
if cfg.CASE_TYPE == "large":
dataset_path = cfg.LARGE_DATASET_PATH
model_cfg = cfg.MODEL.large
output_dir = osp.join(cfg.output_dir, "large")
elif cfg.CASE_TYPE == "normal":
dataset_path = cfg.NORMAL_DATASET_PATH
model_cfg = cfg.MODEL.normal
output_dir = osp.join(cfg.output_dir, "normal")
else:
raise ValueError(
f"cfg.CASE_TYPE should in ['normal', 'large'], but got '{cfg.mode}'"
)
model = ppsci.arch.NowcastNet(**model_cfg)
input_keys = ("radar_frames",)
dataset_param = {
"input_keys": input_keys,
"label_keys": (),
"image_width": model_cfg.image_width,
"image_height": model_cfg.image_height,
"total_length": model_cfg.total_length,
"dataset_path": dataset_path,
"data_type": paddle.get_default_dtype(),
}
test_data_loader = paddle.io.DataLoader(
ppsci.data.dataset.RadarDataset(**dataset_param),
batch_size=1,
shuffle=False,
num_workers=cfg.CPU_WORKER,
drop_last=True,
)
# initialize solver
solver = ppsci.solver.Solver(
model,
output_dir=output_dir,
pretrained_model_path=cfg.EVAL.pretrained_model_path,
)
for batch_id, test_ims in enumerate(test_data_loader):
test_ims = test_ims[0][input_keys[0]].numpy()
frames_tensor = paddle.to_tensor(
data=test_ims, dtype=paddle.get_default_dtype()
)
if batch_id <= cfg.NUM_SAVE_SAMPLES:
visualizer = {
"v_nowcastnet": ppsci.visualize.VisualizerRadar(
{"input": frames_tensor},
{
"output": lambda out: out["output"],
},
prefix="v_nowcastnet",
case_type=cfg.CASE_TYPE,
total_length=model_cfg.total_length,
)
}
solver.visualizer = visualizer
# visualize prediction
solver.visualize(batch_id)
@hydra.main(version_base=None, config_path="./conf", config_name="nowcastnet.yaml")
def main(cfg: DictConfig):
if cfg.mode == "train":
train(cfg)
elif cfg.mode == "eval":
evaluate(cfg)
else:
raise ValueError(f"cfg.mode should in ['train', 'eval'], but got '{cfg.mode}'")
if __name__ == "__main__":
main()