Combining Differentiable PDE Solvers and Graph Neural Networks for Fluid Flow Prediction¶
1. 简介¶
本项目基于paddle框架复现,论文主要点如下:
- 作者构建了针对非均匀网格的GCN网络结构。
- 作者在模型中嵌入了可微分的CFD求解器。
关键技术要点:
- 转换torch_geometric为paddle的pgl图计算库,并实现Dataloader等方法的重新实现,可作为转换样例参考;
- 实现torch_geometric中的knn_interpolate方法。通过paddle api实现,无需再使用torch_geometric组件完成计算;
- 实现SU2项目和paddle的结合使用,通过MPI加速,加快计算速度,减少训练时间。
实验结果要点:
- 成功复现CFDGCN网络,并能够完成模型训练与预测;
- 模型精度均优于论文中报告结果。
论文信息:
- Filipe de Avila Belbute-Peres, Thomas D. Economon, and J. Zico Kolter. 2020. Combining differentiable PDE solvers and graph neural networks for fluid flow prediction. In Proceedings of the 37th International Conference on Machine Learning (ICML'20). JMLR.org, Article 224, 2402–2411.
1.1 模型结构¶
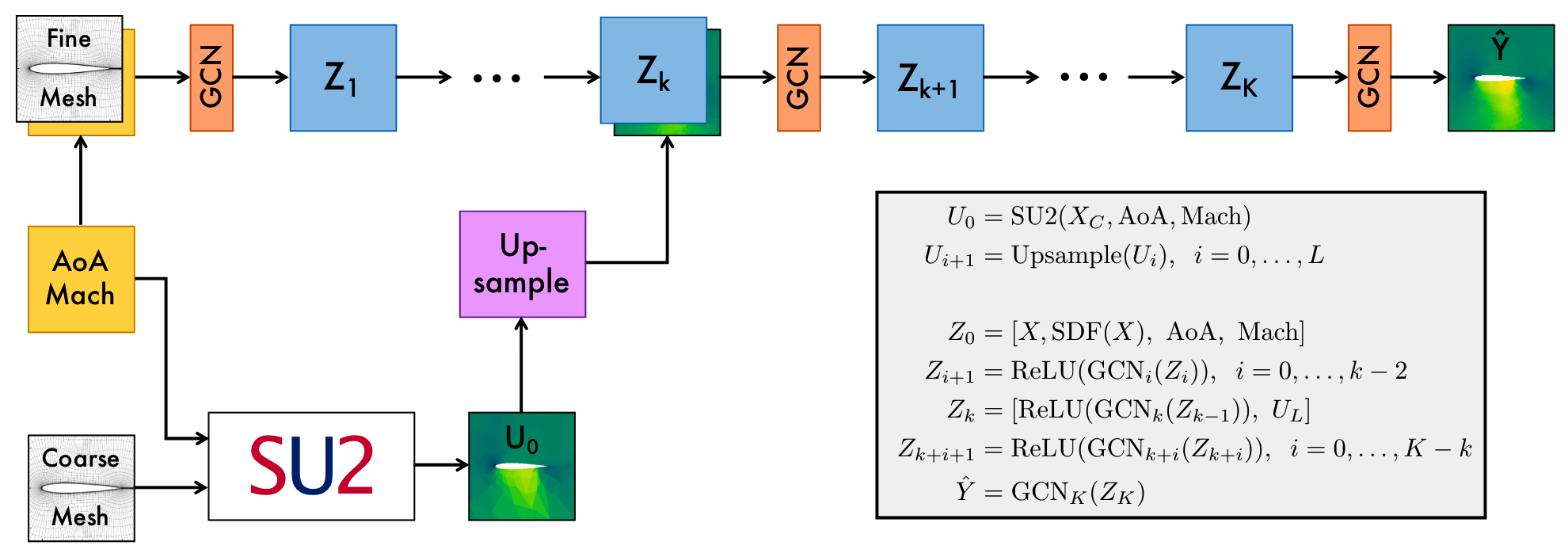
2. 数据集¶
2.1 数据下载使用¶
数据集为作者提供,可通过此处链接进行下载。
- 数据集aistudio地址: https://aistudio.baidu.com/aistudio/datasetdetail/184778
- mesh数据下载
3. 环境依赖¶
本项目实现了GCN模型和CFDGCN模型两种模型。
- GCN模型:仅需要GPU计算资源即可完整运行(轻微修改代码,后续会说明);
- CFDGCN模型:通过MPI调用SU2进行加速计算,需同时使用CPU和GPU资源。
3.1 硬件¶
- 模型:gpu memory >= 6GB
3.2 框架¶
- paddle == 2.4.1
- pgl == 2.2.4
- matplotlib
- h5py
- scipy
- scikit-learn
- mpi4py (使用pip安装)
3.3 本地安装¶
conda create -n paddle_env python=3.8
conda install paddlepaddle-gpu==2.4.1 cudatoolkit=11.6 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ -c conda-forge
conda install scipy h5py matplotlib scikit-learn
pip install mpi4py
4. 快速开始¶
4.1 GCN模型运行¶
在main.py中注释
# import su2paddle.su2_function_mpi as su2_function_mpi (line12)
# su2_function_mpi.activate_su2_mpi(remove_temp_files=True) (line368)
在models.py中注释
4.2 AIStudio上运行¶
-
从data中找到SU2Bin.tgz, 解压到本环境目录下,/home/aistudio/SU2Bin
-
从CFDGCN文件夹解压数据data.tzg,目录结构见5.代码结构与详细说明。
-
本项目推荐使用命令行进行运行。本项目代码同PaddlePaddle/PaddleScience中相同代码,可任选一处运行。
-
GCN模型推荐在aistudio中运行,仅需要GPU资源。
-
CFDGCN模型推荐在本地进行运行或者选择 v100 32g版本环境(可使用4个cpu core)
-
# 此处运行命令无需修改代码即可运行
export BATCH_SIZE=16 # batchsize大小和mpi调用cpu core数量相关,如需在aistudio运行,请调小
export SU2_RUN="/home/aistudio/SU2Bin"
export SU2_HOME="/home/aistudio/SU2Bin"
export PATH=$PATH:$SU2_RUN
export PYTHONPATH=$PYTHONPATH:$SU2_RUN
# Prediction experiments
# for CFDGCN
mpirun -np $((BATCH_SIZE+1)) --oversubscribe python main.py --batch-size $BATCH_SIZE --gpus 1 -dw 1 --su2-config coarse.cfg --model cfd_gcn --hidden-size 512 --num-layers 6 --num-end-convs 3 --optim adam -lr 5e-4 --data-dir data/NACA0012_interpolate --coarse-mesh meshes/mesh_NACA0012_xcoarse.su2 -e cfd_gcn_interp > /dev/null
#for GCN
mpirun -np $((BATCH_SIZE+1)) --oversubscribe python main.py --batch-size $BATCH_SIZE --gpus 1 -dw 1 --model gcn --hidden-size 512 --num-layers 6 --optim adam -lr 5e-4 --data-dir data/NACA0012_interpolate/ -e gcn_interp
# Generalization experiments
# for CFDGCN
mpirun -np $((BATCH_SIZE+1)) --oversubscribe python main.py --batch-size $BATCH_SIZE --gpus 1 -dw 1 --su2-config coarse.cfg --model cfd_gcn --hidden-size 512 --num-layers 6 --num-end-convs 3 --optim adam -lr 5e-4 --data-dir data/NACA0012_machsplit_noshock --coarse-mesh meshes/mesh_NACA0012_xcoarse.su2 -e cfd_gcn_gen > /dev/null
# for GCN
mpirun -np $((BATCH_SIZE+1)) --oversubscribe python main.py --batch-size $BATCH_SIZE --gpus 1 -dw 1 --model gcn --hidden-size 512 --num-layers 6 --optim adam -lr 5e-4 --data-dir data/NACA0012_machsplit_noshock/ -e gcn_gen
4.3 本地运行¶
- 下载数据集文件和预编译SU2Bin文件, 此部分参考aistudio部分
- 从github下载本项目代码,PaddlePaddle/PaddleScience
- 运行
cd CFDGCN-paddle # or cd 3D
export BATCH_SIZE=16 # batchsize大小和mpi调用cpu core数量相关,如需在aistudio运行,请调小
export SU2_RUN="/home/aistudio/SU2Bin"
export SU2_HOME="/home/aistudio/SU2Bin"
export PATH=$PATH:$SU2_RUN
export PYTHONPATH=$PYTHONPATH:$SU2_RUN
# Prediction experiments
# for CFDGCN
mpirun -np $((BATCH_SIZE+1)) --oversubscribe python main.py --batch-size $BATCH_SIZE --gpus 1 -dw 1 --su2-config coarse.cfg --model cfd_gcn --hidden-size 512 --num-layers 6 --num-end-convs 3 --optim adam -lr 5e-4 --data-dir data/NACA0012_interpolate --coarse-mesh meshes/mesh_NACA0012_xcoarse.su2 -e cfd_gcn_interp > /dev/null
# for GCN
mpirun -np $((BATCH_SIZE+1)) --oversubscribe python main.py --batch-size $BATCH_SIZE --gpus 1 -dw 1 --model gcn --hidden-size 512 --num-layers 6 --optim adam -lr 5e-4 --data-dir data/NACA0012_interpolate/ -e gcn_interp
# Generalization experiments
# for CFDGCN
mpirun -np $((BATCH_SIZE+1)) --oversubscribe python main.py --batch-size $BATCH_SIZE --gpus 1 -dw 1 --su2-config coarse.cfg --model cfd_gcn --hidden-size 512 --num-layers 6 --num-end-convs 3 --optim adam -lr 5e-4 --data-dir data/NACA0012_machsplit_noshock --coarse-mesh meshes/mesh_NACA0012_xcoarse.su2 -e cfd_gcn_gen > /dev/null
# for GCN
mpirun -np $((BATCH_SIZE+1)) --oversubscribe python main.py --batch-size $BATCH_SIZE --gpus 1 -dw 1 --model gcn --hidden-size 512 --num-layers 6 --optim adam -lr 5e-4 --data-dir data/NACA0012_machsplit_noshock/ -e gcn_gen
5. 项目结构与实现细节¶
├── coarse.cfg # SU2配置文件
├── common.py # paddle未实现api补充
├── data # 数据集
│ ├── generate_data
│ ├── NACA0012_interpolate
│ ├── NACA0012_machsplit_noshock
│ ├── NACA0012_noshock
│ ├── NACA0012_noshock_strong
│ ├── NACA4412_interpolate
│ ├── NACA4412_machsplit_noshock
│ ├── RAE2822_interpolate
│ └── RAE2822_machsplit_noshock
├── data.py # dataset和dataloader
├── fine.cfg # SU2配置文件
├── main.py # 训练文件
├── meshes # 基础mesh数据,su2格式
│ ├── mesh_NACA0012_coarse.su2
│ ├── mesh_NACA0012_fine.su2
│ ├── mesh_NACA0012_xcoarse.su2
│ ├── mesh_NACA4412_fine.su2
│ ├── mesh_NACA4412_lessfine.su2
│ ├── mesh_NACA4412_xcoarse.su2
│ ├── mesh_RAE2822_fine.su2
│ └── mesh_RAE2822_xcoarse.su2
├── mesh_utils.py # mesh数据处理
├── models.py # 模型文件
├── run.sh
└── su2paddle # su2与paddle相关联文件
├── __init__.py
├── __pycache__
├── su2_function_mpi.py
├── su2_function.py
└── su2_numpy.py
5.1 使用pgl替换torch_geometric¶
5.1.1 Dataset与Dataloader修改¶
# 此处来自pgl官方代码说明(Dataset和Dataloader使用)
from pgl.utils.data import Dataset
from pgl.utils.data.dataloader import Dataloader
class MyDataset(Dataset):
def __init__(self):
self.data = list(range(0, 40))
def __getitem__(self, idx):
return self.data[idx]
def __len__(self):
return len(self.data)
def collate_fn(batch_examples):
inputs = np.array(batch_examples, dtype="int64")
return inputs
dataset = MyDataset()
loader = Dataloader(dataset,
batch_size=3,
drop_last=False,
shuffle=True,
num_workers=4,
collate_fn=collate_fn) # collate_fn:当loader拿到所有batch smaples后的处理操作
for batch_data in loader:
print(batch_data)
缺点:此部分文档没有说明图数据的调用与处理方式,并且图数据构建后不存在.batch属性,与torch_geometric用法不一致,导致复现困难。
此处给出torch_geometric对GCN实现的说明:
- 构建大图数据,即多图合一。
- 通过batch属性确定大图数据的其中一个图,进行GCN计算
- 将每个batch数据计算后数据合并输出
因为pgl的dataloader返回的batch_data为[g1, g2, g3, ...]的list,由此我们不再需要batch属性进行图数据标识,只需要将单个图输入后得到输出即可,本模型中使用for循环进行处理,如下:
for graph in graphs:
x = graph.node_feat["feature"]
......
for i, conv in enumerate(self.convs[:-1]):
x = conv(graph, x)
x = F.relu(x)
, 最后的x即为输出结果。
5.1.2 knn_interpolate方法实现¶
计算方法如下(计算方式与torch_geometric相同):
\(\mathbf{f}(y) = \frac{\sum_{i=1}^k w(x_i) \mathbf{f}(x_i)}{\sum_{i=1}^k w(x_i)} \textrm{, where } w(x_i) = \frac{1}{d(\mathbf{p}(y), \mathbf{p}(x_i))^2}\)
#param features: [353,3]
#param coarse_nodes: [353, 2]
#param fine_nodes: [6684, 2]
coarse_nodes_input = paddle.repeat_interleave(coarse_nodes.unsqueeze(0), fine_nodes.shape[0], 0) # [6684,352,2]
fine_nodes_input = paddle.repeat_interleave(fine_nodes.unsqueeze(1), coarse_nodes.shape[0], 1) # [6684,352,2]
dist_w = 1.0 / (paddle.norm(x=coarse_nodes_input - fine_nodes_input, p=2, axis=-1) + 1e-9) # [6684,352]
knn_value, knn_index = paddle.topk(dist_w, k=3, largest=True) # [6684,3],[6684,3]
weight = knn_value.unsqueeze(-2)
features_input = features[knn_index]
output = paddle.bmm(weight, features_input).squeeze(-2) / paddle.sum(knn_value, axis=-1, keepdim=True)
5.2 SU2项目和paddle的结合使用¶
SU2模型为预编译模型,具体编译过程参考:https://github.com/locuslab/cfd-gcn/Dockerfile
本项目提供预编译可使用版本,目录为/home/aistudio/SU2Bin,CFDGCN/su2paddle为SU2预编译版本与paddle连接文件,其中构建了MPI多线程计算方式,将batch_data的每个item分布式计算,加快计算速度。
使用方式如下: 模型引用:
模型构建:
模型调用:
batch_y = self.su2(nodes_input[..., 0], nodes_input[..., 1],
aoa_input[..., None], mach_or_reynolds_input[..., None])
# nodes_input[..., 0] =>[batch_size, node_number] 起始点
# nodes_input[..., 1] =>[batch_size, node_number] 终止点
# aoa_input[..., None] =>[batch_size, 1]
# mach_or_reynolds_input[..., None] =>[batch_size, 1]
# batch_y =>list [batch_size, node_number] * 3
6. 复现结果¶
6.1 RMSE对比¶
| 模型/指标 | INTERPOLATION (RMSE) | GENERALIZATION (RMSE) |
|---|---|---|
| CFD-GCN (原论文) | 1.8 * 10^-2 | 5.4 * 10^-2 |
| CFD-GCN (复现) | 1.7 * 10^-2 | 5.3 * 10^-2 |
| GCN (原论文) | 1.4 * 10^-2 | 9.5 * 10^-2 |
| GCN (复现) | 1.1 * 10^-2 | 9.4 * 10^-2 |
6.2 可视化展示¶
Pred:
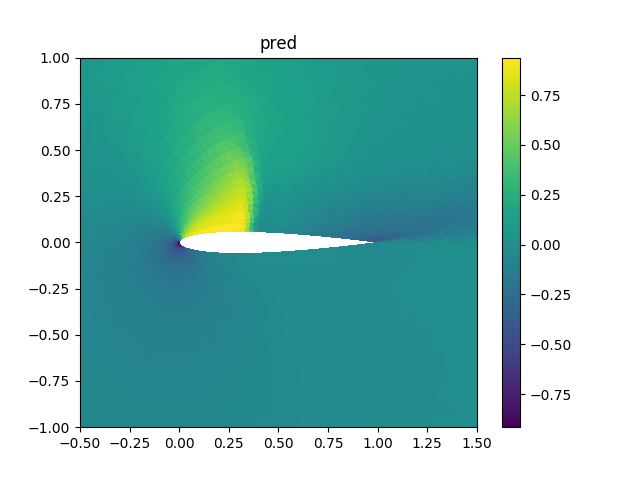
True:
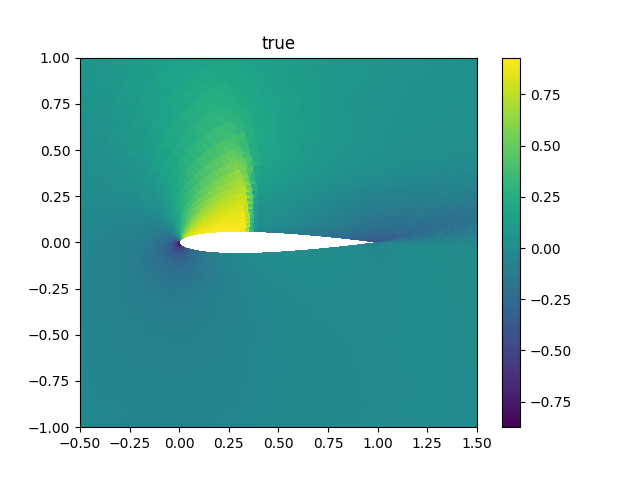
7. 模型信息¶
| 信息 | 说明 |
|---|---|
| 发布者 | 朱卫国 (DrownFish19) |
| 发布时间 | 2023.01 |
| 框架版本 | paddle 2.4.1 |
| 支持硬件 | GPU、CPU |
| 预训练模型训练时间 (V100) | GCN (1-2h) CFDGCN(3-6h) |
| aistudio | notebook |
8. 参考资料¶
创建日期: November 6, 2023