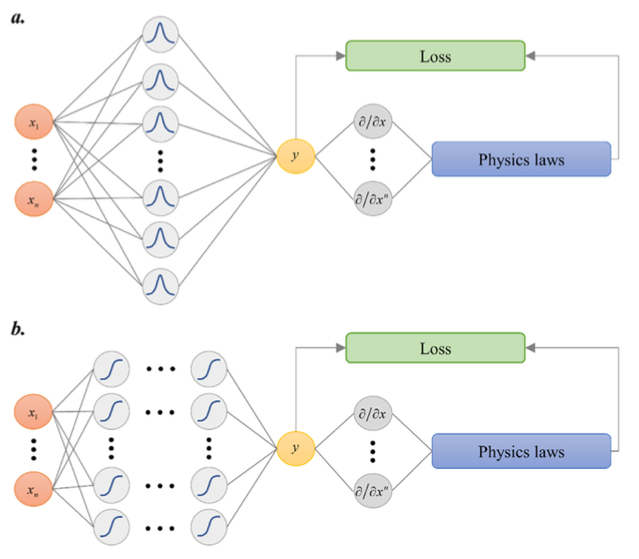
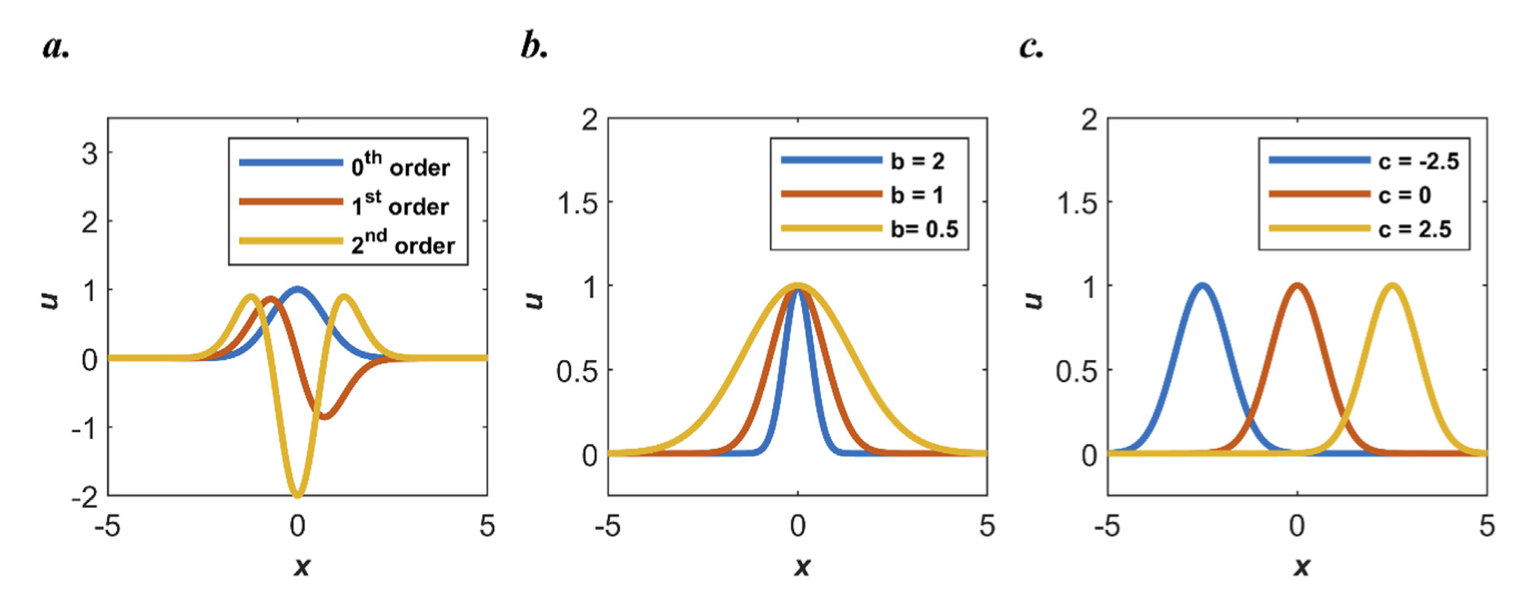
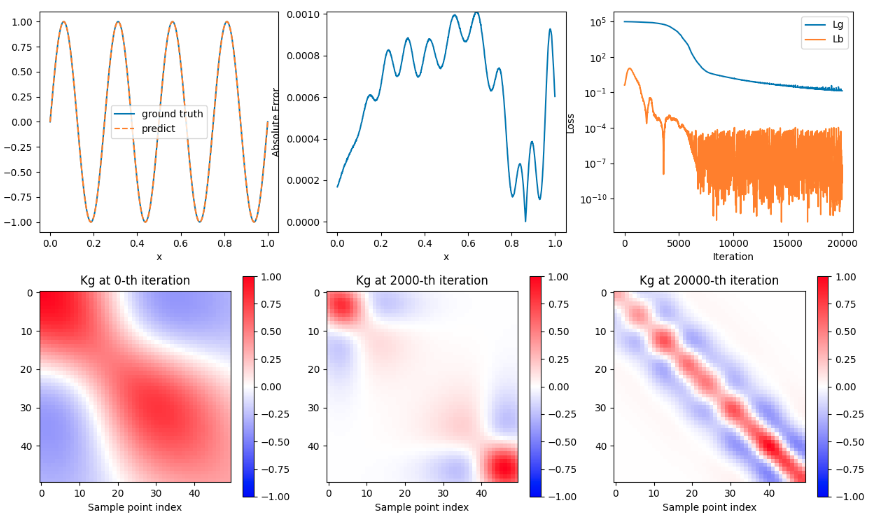
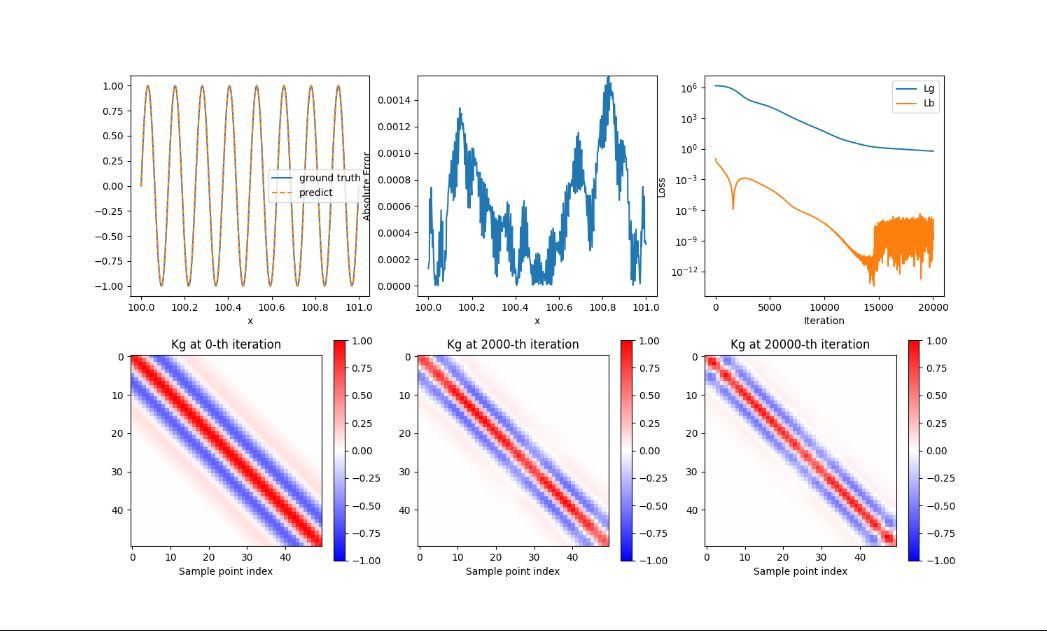
# Define the number of sample pointsns=50# Define the sample points' intervaldx=1.0/(ns-1)# Initialise sample points' coordinatesx_eq=np.linspace(0.0,1.0,ns)[:,None]foriinrange(0,ns):x_eq[i,0]=i*dx+right_byx_bc=np.array([[right_by+0.0],[right_by+1.0]])x=[x_eq,x_bc]y=-4*mu**2*np.pi**2*np.sin(2*mu*np.pi*x_eq)# Set up radial basis networkn_in=1n_out=1n_neu=61b=10.0c=[right_by-0.1,right_by+1.1]
importanalytical_solutionimportnumpyasnpimportpirbnimportrbn_netimporttrainimportppsci# set random seed for reproducibilitySEED=2023ppsci.utils.misc.set_random_seed(SEED)# mu, Fig.1, Page5# right_by, Formula (15) Page5defsine_function_main(mu,adaptive_weights=True,right_by=0,activation_function="gaussian"):# Define the number of sample pointsns=50# Define the sample points' intervaldx=1.0/(ns-1)# Initialise sample points' coordinatesx_eq=np.linspace(0.0,1.0,ns)[:,None]foriinrange(0,ns):x_eq[i,0]=i*dx+right_byx_bc=np.array([[right_by+0.0],[right_by+1.0]])x=[x_eq,x_bc]y=-4*mu**2*np.pi**2*np.sin(2*mu*np.pi*x_eq)# Set up radial basis networkn_in=1n_out=1n_neu=61b=10.0c=[right_by-0.1,right_by+1.1]# Set up PIRBNrbn=rbn_net.RBN_Net(n_in,n_out,n_neu,b,c,activation_function)rbn_loss=pirbn.PIRBN(rbn,activation_function)maxiter=20001output_Kgg=[0,int(0.1*maxiter),maxiter-1]train_obj=train.Trainer(rbn_loss,x,y,learning_rate=0.001,maxiter=maxiter,adaptive_weights=adaptive_weights,)train_obj.fit(output_Kgg)# Visualise resultsanalytical_solution.output_fig(train_obj,mu,b,right_by,activation_function,output_Kgg)# Fig.1sine_function_main(mu=4,right_by=0,activation_function="tanh")# Fig.2sine_function_main(mu=8,right_by=0,activation_function="tanh")# Fig.3sine_function_main(mu=4,right_by=100,activation_function="tanh")# Fig.6sine_function_main(mu=8,right_by=100,activation_function="gaussian")