Learning to regularize with a variational autoencoder for hydrologic inverse analysis¶
1.简介¶
本项目基于paddle框架复现。
论文主要点如下:
- 作者提出了一种基于变分自动编码器 (VAE)的正则化方法;
- 这种方法的优点1: 对来自VAE的潜在变量(此处指encoder的输出)执行正则化,可以简单地对其进行正则化;
- 这种方法的优点2: VAE减少了优化问题中的变量数量,从而在伴随方法不可用时使基于梯度的优化在计算上更加高效。
本项目关键技术要点:
- 实现paddle和julia混写代码梯度传递,避免大面积重写julia代码并能够调用优秀的julia代码;
- 发现paddle minimize_lbfgs存在问题, 待提交issue确认。
实验结果要点:
- 成功复现论文代码框架及全流程运行测试;
- 本次复现精度因无法使用相同样本,无法与论文中数据进行一一比较。本项目给出了采用paddle编写的框架结果。
论文信息: O'Malley D, Golden J K, Vesselinov V V. Learning to regularize with a variational autoencoder for hydrologic inverse analysis[J]. arXiv preprint arXiv:1906.02401, 2019.
参考GitHub地址: https://github.com/madsjulia/RegAE.jl
项目aistudio地址: https://aistudio.baidu.com/aistudio/projectdetail/5541961
模型结构
2.数据集¶
本项目数据集通过作者提供的julia代码生成,生成后保存为npz文件,已上传aistudio数据集并关联本项目。
以下为数据生成和数据保存代码的说明
(1)作者通过julia中的DPFEHM和GaussianRandomFields进行数据生成,代码可参考本项目/home/aistudio/RegAE.jl/examples/hydrology/ex_gaussian.jl,可根据其中参数进行修改;
(2)数据保存代码。在/home/aistudio/RegAE.jl/examples/hydrology/ex.jl代码中增加以下代码,可将数据通过转换为numpy数据并保存为npz。
using Distributed
using PyCall # 增加此处引用
@everywhere variablename = "allloghycos"
@everywhere datafilename = "$(results_dir)/trainingdata.jld2"
if !isfile(datafilename)
if nworkers() == 1
error("Please run in parallel: julia -p 32")
end
numsamples = 10^5
@time allloghycos = SharedArrays.SharedArray{Float32}(numsamples, ns[2], ns[1]; init=A -> samplehyco!(A; setseed=true))
# @time JLD2.@save datafilename allloghycos
########### 此处为增加部分 ###########
p_trues = SharedArrays.SharedArray{Float32}(3, ns[2], ns[1]; init=samplehyco!) # 计算p_true
np = pyimport("numpy")
training_data = np.asarray(allloghycos)
test_data = np.asarray(p_trues)
np_coords = np.asarray(coords)
np_neighbors = np.asarray(neighbors)
np_areasoverlengths = np.asarray(areasoverlengths)
np_dirichletnodes = np.asarray(dirichletnodes)
np_dirichletheads = np.asarray(dirichletheads)
np.savez("$(results_dir)/gaussian_train.npz",
data=training_data,
test_data=test_data,
coords=np_coords,
neighbors=np_neighbors,
areasoverlengths=np_areasoverlengths,
dirichletnodes=np_dirichletnodes,
dirichletheads=np_dirichletheads)
end
数据标准化¶
- 数据标准化方式: \(z = (x - \mu)/ \sigma\)
class ScalerStd(object):
"""
Desc: Normalization utilities with std mean
"""
def __init__(self):
self.mean = 0.
self.std = 1.
def fit(self, data):
self.mean = np.mean(data)
self.std = np.std(data)
def transform(self, data):
mean = paddle.to_tensor(self.mean).type_as(data).to(
data.device) if paddle.is_tensor(data) else self.mean
std = paddle.to_tensor(self.std).type_as(data).to(
data.device) if paddle.is_tensor(data) else self.std
return (data - mean) / std
def inverse_transform(self, data):
mean = paddle.to_tensor(self.mean) if paddle.is_tensor(data) else self.mean
std = paddle.to_tensor(self.std) if paddle.is_tensor(data) else self.std
return (data * std) + mean
定义Dataset¶
- 通过读取预保存npz加载数据,当前数据类型为 [data_nums, 100, 100], 此处100为数据生成过程中指定
- 数据reshape为 [data_nums, 10000]
- 数据划分为8:2用与train和test
- 通过对train数据得到标准化参数mean和std,并用此参数标准化train和test数据集
- 通过dataloader得到的数据形式为 [batch_size, 10000]
class CustomDataset(Dataset):
def __init__(self, file_path, data_type="train"):
"""
:param file_path:
:param data_type: train or test
"""
super().__init__()
all_data = np.load(file_path)
data = all_data["data"]
num, _, _ = data.shape
data = data.reshape(num, -1)
self.neighbors = all_data['neighbors']
self.areasoverlengths = all_data['areasoverlengths']
self.dirichletnodes = all_data['dirichletnodes']
self.dirichleths = all_data['dirichletheads']
self.Qs = np.zeros([all_data['coords'].shape[-1]])
self.val_data = all_data["test_data"]
self.data_type = data_type
self.train_len = int(num * 0.8)
self.test_len = num - self.train_len
self.train_data = data[:self.train_len]
self.test_data = data[self.train_len:]
self.scaler = ScalerStd()
self.scaler.fit(self.train_data)
self.train_data = self.scaler.transform(self.train_data)
self.test_data = self.scaler.transform(self.test_data)
def __getitem__(self, idx):
if self.data_type == "train":
return self.train_data[idx]
else:
return self.test_data[idx]
def __len__(self):
if self.data_type == "train":
return self.train_len
else:
return self.test_len
将数据转换为IterableNPZDataset的形式¶
3.环境依赖¶
本项目为julia和python混合项目。
julia依赖¶
- DPFEHM
- Zygote
python依赖¶
- paddle
- julia (pip安装)
- matplotlib
本项目已经提供安装后压缩文档,可fork本项目后执行以下代码进行解压安装。
# 解压预下载文件和预编译文件
!tar zxf /home/aistudio/opt/curl-7.88.1.tar.gz -C /home/aistudio/opt # curl 预下载文件
!tar zxf /home/aistudio/opt/curl-7.88.1-build.tgz -C /home/aistudio/opt # curl 预编译文件
!tar zxf /home/aistudio/opt/julia-1.8.5-linux-x86_64.tar.gz -C /home/aistudio/opt # julia 预下载文件
!tar zxf /home/aistudio/opt/julia_package.tgz -C /home/aistudio/opt # julia依赖库文件
!tar zxf /home/aistudio/opt/external-libraries.tgz -C /home/aistudio/opt # pip依赖库文件
####### 以下指令需要时可参考执行,上述压缩包已经完成以下内容 #######
# curl 编译指令,当解压后无效使用
!mkdir -p /home/aistudio/opt/curl-7.88.1-build
!/home/aistudio/opt/curl-7.88.1/configure --prefix=/home/aistudio/opt/curl-7.88.1-build --with-ssl --enable-tls-srp
!make install -j4
# 指定curl预编译文件
!export LD_LIBRARY_PATH=/home/aistudio/opt/curl-7.88.1-build/lib:$LD_LIBRARY_PATH
!export PATH=/home/aistudio/opt/curl-7.88.1-build/bin:$PATH
!export CPATH=/home/aistudio/opt/curl-7.88.1-build/include:$CPATH
!export LIBRARY_PATH=/home/aistudio/opt/curl-7.88.1-build/lib:$LIBRARY_PATH
# 指定已经安装的julia包
!export JULIA_DEPOT_PATH=/home/aistudio/opt/julia_package
# 指定julia使用清华源
!export JULIA_PKG_SERVER=https://mirrors.tuna.tsinghua.edu.cn/julia
# julia 安装依赖库
# 需要先export JULIA_DEPOT_PATH 环境变量,否则安装位置为~/.julia, aistudio无法保存
!/home/aistudio/opt/julia-1.8.5/bin/julia -e "using Pkg; Pkg.add(\"DPFEHM\")"
!/home/aistudio/opt/julia-1.8.5/bin/julia -e "using Pkg; Pkg.add(\"Zygote\")"
!/home/aistudio/opt/julia-1.8.5/bin/julia -e "using Pkg; Pkg.add(\"PyCall\")"
使用方法可以参考以下代码和julia导数传递测试.ipynb文件。
import paddle
import os
import sys
# julia 依赖
os.environ['JULIA_DEPOT_PATH'] = '/home/aistudio/opt/julia_package'
# pip 依赖
sys.path.append('/home/aistudio/opt/external-libraries')
# julieries
from julia.api import Julia
jl = Julia(compiled_modules=False,runtime="/home/aistudio/opt/julia-1.8.5/bin/julia")
# import julia
from julia import Main
4.快速开始¶
本项目运行分为两个步骤:
- (1)训练步骤。通过运行train.ipynb文件,可以得到训练后的模型参数,具体代码请参考train.ipynb文件及其中注释说明;
- (2)测试步骤。通过运行test.ipynb文件,应用训练后的模型参数,对latent domain进行优化。
5.代码结构与详细说明¶
├── data #预生成数据文件
│ └── data193595
├── main.ipynb #本说明文件
├── opt #环境配置文件,已压缩,解压即可使用
│ ├── curl-7.88.1
│ ├── curl-7.88.1-build
│ ├── curl-7.88.1-build.tgz
│ ├── curl-7.88.1.tar.gz
│ ├── external-libraries
│ ├── external-libraries.tgz
│ ├── julia-1.8.5
│ ├── julia-1.8.5-linux-x86_64.tar.gz
│ ├── julia_package
│ └── julia_package.tgz
├── params_vae_nz100 #模型参数文件
│ └── model.pdparams
├── params_vae_nz200
│ └── model.pdparams
├── params_vae_nz400
│ └── model.pdparams
├── test.ipynb #测试文件
├── train.ipynb #训练文件
├── julia导数传递测试.ipynb #julia和python混合测试文件
train文件和test文件关联性说明¶
我们依照论文作者的符号进行说明,\(p\)为数据输入,\(\hat{p}\)为数据输出,\(loss=mse(p,\hat{p}) + loss_{kl}(\hat{p},N(0,1))\)。
- (1)通过train能够得到训练后的Autoencoder(包含encoder和decoder);
- (2)通过test调用训练后的encoder针对testdata生成latent_test,并得到latent_mean;
- (3)针对新生成的样本\(p_{new}\),通过LBFGS方法不断优化latent_mean,直到obj_fun最小,其中obj_fun = mse(\(p_{new}\),\(\hat{p}_{new}\))+mse(sci_fun(\(p_{new}\)),sci_fun(\(\hat{p}_{new}\))),sci_fun为任何其他科学计算模拟方法。
paddle.incubate.optimizer.functional.minimize_lbfgs 问题¶
以下为paddle官方minimize_lbfgs API:
paddle.incubate.optimizer.functional.minimize_lbfgs(objective_func, initial_position, history_size=100, max_iters=50, tolerance_grad=1e-08, tolerance_change=1e-08, initial_inverse_hessian_estimate=None, line_search_fn='strong_wolfe', max_line_search_iters=50, initial_step_length=1.0, dtype='float32', name=None)
- (1)参数max_line_search_iters无效。虽然设置了此参数,但是内部没有传递对应参数;
- (2)中wolfe条件1错误。line256处应为
phi_2 >= phi_1,以下为paddle部分源码。
# 1. If phi(a2) > phi(0) + c_1 * a2 * phi'(0) or [phi(a2) >= phi(a1) and i > 1],
# a_star= zoom(a1, a2) and stop;
pred1 = ~done & ((phi_2 > phi_0 + c1 * a2 * derphi_0) |
((phi_2 >= phi_0) & (i > 1)))
6.复现结果¶
不同latent维度对比¶
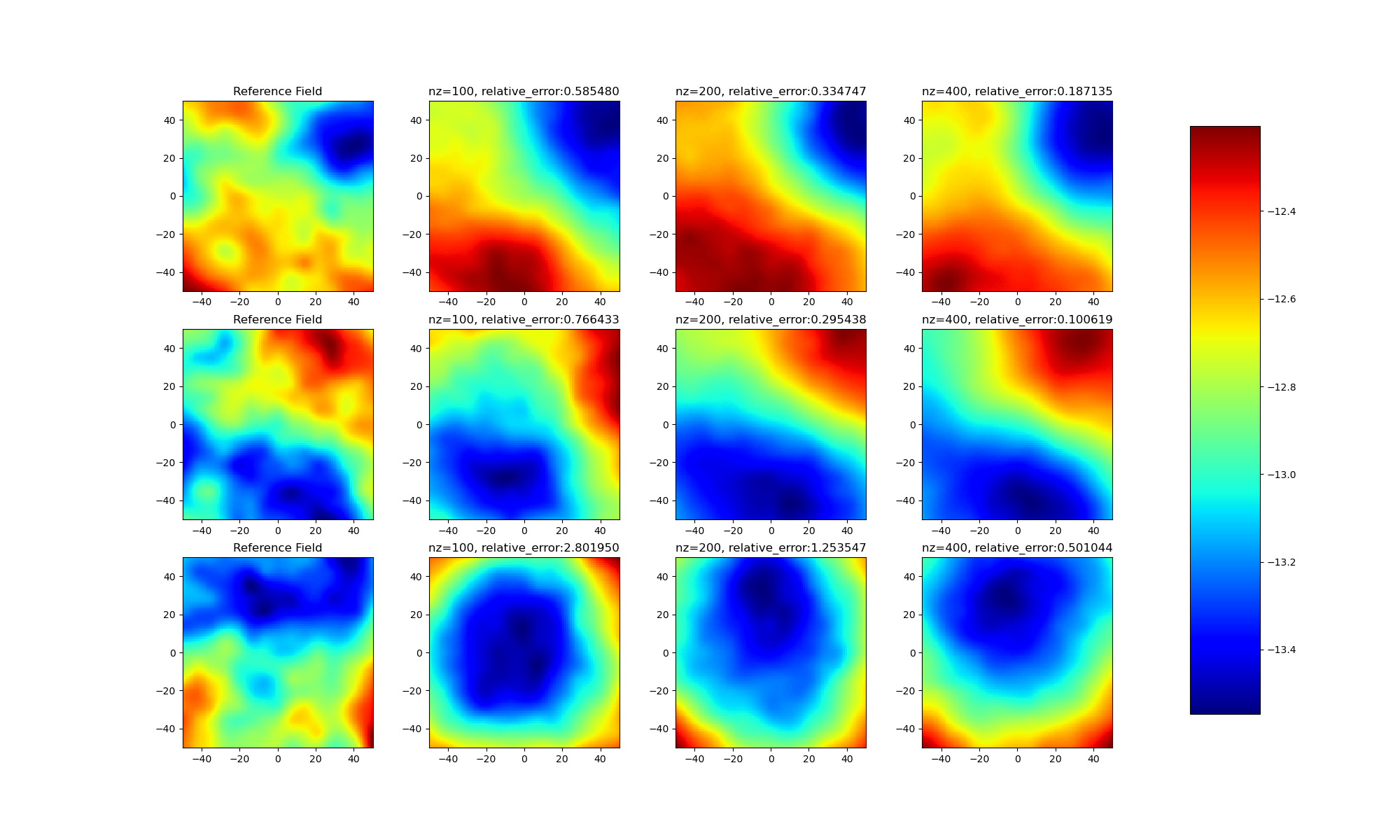
通过实验结果可以发现:
- (1)不同样本之间存在差距,并不是所有样本都能优化得到良好的latent变量;
- (2)随着模型latent维度的上升,模型效果逐渐提升。
latent_random和latent_mean对比¶
本项目还增加了latent_random和latent_mean对生成结果的对比。此处对latent_random和latent_mean再次说明:
- latent_random:通过paddle.randn生成的高斯噪声得到;
- latent_mean:通过对所有testdata进行encoder结果平均得到。
以下为通过latent_random得到的实验结果

通过对比,可以发现latent_mean对优化结果重要影响。近似正确的latent变量能够得到更优的生成结果。
LBFGS优化收敛情况¶
可以从如下图中看出,使用paddle minimize_lbfgs能够有效优化收敛。

7.延伸思考¶
如果深入思考本项目,会发现模型在test过程中是使用真实数据作为目标进行lbfgs优化,这种计算方式还有意义吗?
回答是肯定的!有意义!
以下为本人个人观点:
- (1)通过实验对比latent_random和latent_mean的最终生成结果差距,可以发现一个良好的初值对模型的影响是巨大的。当前diffusion模型在sample生成过程对生成的高斯噪声不断做denoise操作,这其中生成的噪声数据如果经过预先优化,不仅能够加速diffusion的生成速度,而且能够提升数据的生成质量。
- (2)在域迁移等研究领域,可以使用这种latent逐渐生成中间过渡变量,达到不同域数据的迁移生成。
7.模型信息¶
| 信息 | 说明 |
|---|---|
| 发布者 | 朱卫国 (DrownFish19) |
| 发布时间 | 2023.03 |
| 框架版本 | paddle 2.4.1 |
| 支持硬件 | GPU、CPU |
| aistudio | notebook |
请点击此处查看本环境基本用法. Please click here for more detailed instructions.