# Copyright (c) 2023 PaddlePaddle Authors. All Rights Reserved.
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from os import path as osp
import hydra
import matplotlib.pyplot as plt
import numpy as np
from omegaconf import DictConfig
import ppsci
from ppsci.utils import logger
def train(cfg: DictConfig):
# set random seed for reproducibility
ppsci.utils.misc.set_random_seed(cfg.seed)
# initialize logger
logger.init_logger("ppsci", osp.join(cfg.output_dir, f"{cfg.mode}.log"), "info")
# set model
model = ppsci.arch.HEDeepONets(**cfg.MODEL)
# set time-geometry
timestamps = np.linspace(0.0, 2, cfg.NTIME + 1, endpoint=True)
geom = {
"time_rect": ppsci.geometry.TimeXGeometry(
ppsci.geometry.TimeDomain(0.0, 1, timestamps=timestamps),
ppsci.geometry.Interval(0, cfg.DL),
)
}
# Generate train data and eval data
visu_input = geom["time_rect"].sample_interior(cfg.NPOINT * cfg.NTIME, evenly=True)
data_h = np.random.rand(cfg.NQM).reshape([-1, 1]) * 2
data_c = np.random.rand(cfg.NQM).reshape([-1, 1]) * 2
data_h = data_h.astype("float32")
data_c = data_c.astype("float32")
test_h = np.random.rand(1).reshape([-1, 1]).astype("float32")
test_c = np.random.rand(1).reshape([-1, 1]).astype("float32")
# rearrange train data and eval data
points = visu_input.copy()
points["t"] = np.repeat(points["t"], cfg.NQM, axis=0)
points["x"] = np.repeat(points["x"], cfg.NQM, axis=0)
points["qm_h"] = np.tile(data_h, (cfg.NPOINT * cfg.NTIME, 1))
points["t"] = np.repeat(points["t"], cfg.NQM, axis=0)
points["x"] = np.repeat(points["x"], cfg.NQM, axis=0)
points["qm_h"] = np.repeat(points["qm_h"], cfg.NQM, axis=0)
points["qm_c"] = np.tile(data_c, (cfg.NPOINT * cfg.NTIME * cfg.NQM, 1))
visu_input["qm_h"] = np.tile(test_h, (cfg.NPOINT * cfg.NTIME, 1))
visu_input["qm_c"] = np.tile(test_c, (cfg.NPOINT * cfg.NTIME, 1))
left_indices = visu_input["x"] == 0
right_indices = visu_input["x"] == cfg.DL
interior_indices = (visu_input["x"] != 0) & (visu_input["x"] != cfg.DL)
left_indices = np.where(left_indices)
right_indices = np.where(right_indices)
interior_indices = np.where(interior_indices)
left_indices1 = points["x"] == 0
right_indices1 = points["x"] == cfg.DL
interior_indices1 = (points["x"] != 0) & (points["x"] != cfg.DL)
initial_indices1 = points["t"] == points["t"][0]
left_indices1 = np.where(left_indices1)
right_indices1 = np.where(right_indices1)
interior_indices1 = np.where(interior_indices1)
initial_indices1 = np.where(initial_indices1)
# Classification train data
left_data = {
"x": points["x"][left_indices1[0]],
"t": points["t"][left_indices1[0]],
"qm_h": points["qm_h"][left_indices1[0]],
"qm_c": points["qm_c"][left_indices1[0]],
}
right_data = {
"x": points["x"][right_indices1[0]],
"t": points["t"][right_indices1[0]],
"qm_h": points["qm_h"][right_indices1[0]],
"qm_c": points["qm_c"][right_indices1[0]],
}
interior_data = {
"x": points["x"],
"t": points["t"],
"qm_h": points["qm_h"],
"qm_c": points["qm_c"],
}
initial_data = {
"x": points["x"][initial_indices1[0]],
"t": points["t"][initial_indices1[0]] * 0,
"qm_h": points["qm_h"][initial_indices1[0]],
"qm_c": points["qm_c"][initial_indices1[0]],
}
# Classification eval data
test_left_data = {
"x": visu_input["x"][left_indices[0]],
"t": visu_input["t"][left_indices[0]],
"qm_h": visu_input["qm_h"][left_indices[0]],
"qm_c": visu_input["qm_c"][left_indices[0]],
}
test_right_data = {
"x": visu_input["x"][right_indices[0]],
"t": visu_input["t"][right_indices[0]],
"qm_h": visu_input["qm_h"][right_indices[0]],
"qm_c": visu_input["qm_c"][right_indices[0]],
}
test_interior_data = {
"x": visu_input["x"],
"t": visu_input["t"],
"qm_h": visu_input["qm_h"],
"qm_c": visu_input["qm_c"],
}
# set equation
equation = {
"heat_exchanger": ppsci.equation.HeatExchanger(
cfg.alpha_h / (cfg.L * cfg.cp_h),
cfg.alpha_c / (cfg.L * cfg.cp_c),
cfg.v_h,
cfg.v_c,
cfg.alpha_h / (cfg.M * cfg.cp_w),
cfg.alpha_c / (cfg.M * cfg.cp_w),
)
}
# set constraint
bc_label = {
"T_h": np.zeros([left_data["x"].shape[0], 1], dtype="float32"),
}
interior_label = {
"heat_boundary": np.zeros([interior_data["x"].shape[0], 1], dtype="float32"),
"cold_boundary": np.zeros([interior_data["x"].shape[0], 1], dtype="float32"),
"wall": np.zeros([interior_data["x"].shape[0], 1], dtype="float32"),
}
initial_label = {
"T_h": np.zeros([initial_data["x"].shape[0], 1], dtype="float32"),
"T_c": np.zeros([initial_data["x"].shape[0], 1], dtype="float32"),
"T_w": np.zeros([initial_data["x"].shape[0], 1], dtype="float32"),
}
left_sup_constraint = ppsci.constraint.SupervisedConstraint(
{
"dataset": {
"name": "NamedArrayDataset",
"input": left_data,
"label": bc_label,
"weight": {
"T_h": np.full_like(
left_data["x"], cfg.TRAIN.weight.left_sup_constraint.T_h
)
},
},
"batch_size": cfg.TRAIN.batch_size,
"sampler": {
"name": "BatchSampler",
"drop_last": False,
"shuffle": True,
},
},
ppsci.loss.MSELoss("mean"),
output_expr={"T_h": lambda out: out["T_h"] - cfg.T_hin},
name="left_sup",
)
right_sup_constraint = ppsci.constraint.SupervisedConstraint(
{
"dataset": {
"name": "NamedArrayDataset",
"input": right_data,
"label": bc_label,
"weight": {
"T_h": np.full_like(
right_data["x"], cfg.TRAIN.weight.right_sup_constraint.T_h
)
},
},
"batch_size": cfg.TRAIN.batch_size,
"sampler": {
"name": "BatchSampler",
"drop_last": False,
"shuffle": True,
},
},
ppsci.loss.MSELoss("mean"),
output_expr={"T_h": lambda out: out["T_c"] - cfg.T_cin},
name="right_sup",
)
interior_sup_constraint = ppsci.constraint.SupervisedConstraint(
{
"dataset": {
"name": "NamedArrayDataset",
"input": interior_data,
"label": interior_label,
"weight": {
"heat_boundary": np.full_like(
interior_data["x"],
cfg.TRAIN.weight.interior_sup_constraint.heat_boundary,
),
"cold_boundary": np.full_like(
interior_data["x"],
cfg.TRAIN.weight.interior_sup_constraint.cold_boundary,
),
"wall": np.full_like(
interior_data["x"],
cfg.TRAIN.weight.interior_sup_constraint.wall,
),
},
},
"batch_size": cfg.TRAIN.batch_size,
"sampler": {
"name": "BatchSampler",
"drop_last": False,
"shuffle": True,
},
},
ppsci.loss.MSELoss("mean"),
output_expr=equation["heat_exchanger"].equations,
name="interior_sup",
)
initial_sup_constraint = ppsci.constraint.SupervisedConstraint(
{
"dataset": {
"name": "NamedArrayDataset",
"input": initial_data,
"label": initial_label,
"weight": {
"T_h": np.full_like(
initial_data["x"], cfg.TRAIN.weight.initial_sup_constraint.T_h
),
"T_c": np.full_like(
initial_data["x"], cfg.TRAIN.weight.initial_sup_constraint.T_c
),
"T_w": np.full_like(
initial_data["x"], cfg.TRAIN.weight.initial_sup_constraint.T_w
),
},
},
"batch_size": cfg.TRAIN.batch_size,
"sampler": {
"name": "BatchSampler",
"drop_last": False,
"shuffle": True,
},
},
ppsci.loss.MSELoss("mean"),
output_expr={
"T_h": lambda out: out["T_h"] - cfg.T_hin,
"T_c": lambda out: out["T_c"] - cfg.T_cin,
"T_w": lambda out: out["T_w"] - cfg.T_win,
},
name="initial_sup",
)
# wrap constraints together
constraint = {
left_sup_constraint.name: left_sup_constraint,
right_sup_constraint.name: right_sup_constraint,
interior_sup_constraint.name: interior_sup_constraint,
initial_sup_constraint.name: initial_sup_constraint,
}
# set optimizer
optimizer = ppsci.optimizer.Adam(cfg.TRAIN.learning_rate)(model)
# set validator
test_bc_label = {
"T_h": np.zeros([test_left_data["x"].shape[0], 1], dtype="float32"),
}
test_interior_label = {
"heat_boundary": np.zeros(
[test_interior_data["x"].shape[0], 1], dtype="float32"
),
"cold_boundary": np.zeros(
[test_interior_data["x"].shape[0], 1], dtype="float32"
),
"wall": np.zeros([test_interior_data["x"].shape[0], 1], dtype="float32"),
}
left_validator = ppsci.validate.SupervisedValidator(
{
"dataset": {
"name": "NamedArrayDataset",
"input": test_left_data,
"label": test_bc_label,
},
"batch_size": cfg.NTIME,
"sampler": {
"name": "BatchSampler",
"drop_last": False,
"shuffle": False,
},
},
ppsci.loss.MSELoss("mean"),
output_expr={"T_h": lambda out: out["T_h"] - cfg.T_hin},
metric={"MSE": ppsci.metric.MSE()},
name="left_mse",
)
right_validator = ppsci.validate.SupervisedValidator(
{
"dataset": {
"name": "NamedArrayDataset",
"input": test_right_data,
"label": test_bc_label,
},
"batch_size": cfg.NTIME,
"sampler": {
"name": "BatchSampler",
"drop_last": False,
"shuffle": False,
},
},
ppsci.loss.MSELoss("mean"),
output_expr={"T_h": lambda out: out["T_c"] - cfg.T_cin},
metric={"MSE": ppsci.metric.MSE()},
name="right_mse",
)
interior_validator = ppsci.validate.SupervisedValidator(
{
"dataset": {
"name": "NamedArrayDataset",
"input": test_interior_data,
"label": test_interior_label,
},
"batch_size": cfg.NTIME,
"sampler": {
"name": "BatchSampler",
"drop_last": False,
"shuffle": False,
},
},
ppsci.loss.MSELoss("mean"),
output_expr=equation["heat_exchanger"].equations,
metric={"MSE": ppsci.metric.MSE()},
name="interior_mse",
)
validator = {
left_validator.name: left_validator,
right_validator.name: right_validator,
interior_validator.name: interior_validator,
}
# initialize solver
solver = ppsci.solver.Solver(
model,
constraint,
cfg.output_dir,
optimizer,
None,
cfg.TRAIN.epochs,
cfg.TRAIN.iters_per_epoch,
eval_during_train=cfg.TRAIN.eval_during_train,
eval_freq=cfg.TRAIN.eval_freq,
equation=equation,
geom=geom,
validator=validator,
)
# train model
solver.train()
# evaluate after finished training
solver.eval()
# plotting iteration/epoch-loss curve.
solver.plot_loss_history()
# visualize prediction after finished training
visu_input["qm_c"] = np.full_like(visu_input["qm_c"], cfg.qm_h)
visu_input["qm_h"] = np.full_like(visu_input["qm_c"], cfg.qm_c)
pred = solver.predict(visu_input, return_numpy=True)
plot(visu_input, pred, cfg)
def evaluate(cfg: DictConfig):
# set random seed for reproducibility
ppsci.utils.misc.set_random_seed(cfg.seed)
# initialize logger
logger.init_logger("ppsci", osp.join(cfg.output_dir, f"{cfg.mode}.log"), "info")
# set model
model = ppsci.arch.HEDeepONets(**cfg.MODEL)
# set time-geometry
timestamps = np.linspace(0.0, 2, cfg.NTIME + 1, endpoint=True)
geom = {
"time_rect": ppsci.geometry.TimeXGeometry(
ppsci.geometry.TimeDomain(0.0, 1, timestamps=timestamps),
ppsci.geometry.Interval(0, cfg.DL),
)
}
# Generate eval data
visu_input = geom["time_rect"].sample_interior(cfg.NPOINT * cfg.NTIME, evenly=True)
test_h = np.random.rand(1).reshape([-1, 1]).astype("float32")
test_c = np.random.rand(1).reshape([-1, 1]).astype("float32")
# rearrange train data and eval data
visu_input["qm_h"] = np.tile(test_h, (cfg.NPOINT * cfg.NTIME, 1))
visu_input["qm_c"] = np.tile(test_c, (cfg.NPOINT * cfg.NTIME, 1))
left_indices = visu_input["x"] == 0
right_indices = visu_input["x"] == cfg.DL
interior_indices = (visu_input["x"] != 0) & (visu_input["x"] != cfg.DL)
left_indices = np.where(left_indices)
right_indices = np.where(right_indices)
interior_indices = np.where(interior_indices)
# Classification eval data
test_left_data = {
"x": visu_input["x"][left_indices[0]],
"t": visu_input["t"][left_indices[0]],
"qm_h": visu_input["qm_h"][left_indices[0]],
"qm_c": visu_input["qm_c"][left_indices[0]],
}
test_right_data = {
"x": visu_input["x"][right_indices[0]],
"t": visu_input["t"][right_indices[0]],
"qm_h": visu_input["qm_h"][right_indices[0]],
"qm_c": visu_input["qm_c"][right_indices[0]],
}
test_interior_data = {
"x": visu_input["x"],
"t": visu_input["t"],
"qm_h": visu_input["qm_h"],
"qm_c": visu_input["qm_c"],
}
# set equation
equation = {
"heat_exchanger": ppsci.equation.HeatExchanger(
cfg.alpha_h / (cfg.L * cfg.cp_h),
cfg.alpha_c / (cfg.L * cfg.cp_c),
cfg.v_h,
cfg.v_c,
cfg.alpha_h / (cfg.M * cfg.cp_w),
cfg.alpha_c / (cfg.M * cfg.cp_w),
)
}
# set validator
test_bc_label = {
"T_h": np.zeros([test_left_data["x"].shape[0], 1], dtype="float32"),
}
test_interior_label = {
"heat_boundary": np.zeros(
[test_interior_data["x"].shape[0], 1], dtype="float32"
),
"cold_boundary": np.zeros(
[test_interior_data["x"].shape[0], 1], dtype="float32"
),
"wall": np.zeros([test_interior_data["x"].shape[0], 1], dtype="float32"),
}
left_validator = ppsci.validate.SupervisedValidator(
{
"dataset": {
"name": "NamedArrayDataset",
"input": test_left_data,
"label": test_bc_label,
},
"batch_size": cfg.NTIME,
"sampler": {
"name": "BatchSampler",
"drop_last": False,
"shuffle": False,
},
},
ppsci.loss.MSELoss("mean"),
output_expr={
"T_h": lambda out: out["T_h"] - cfg.T_hin,
},
metric={"MSE": ppsci.metric.MSE()},
name="left_mse",
)
right_validator = ppsci.validate.SupervisedValidator(
{
"dataset": {
"name": "NamedArrayDataset",
"input": test_right_data,
"label": test_bc_label,
},
"batch_size": cfg.NTIME,
"sampler": {
"name": "BatchSampler",
"drop_last": False,
"shuffle": False,
},
},
ppsci.loss.MSELoss("mean"),
output_expr={
"T_h": lambda out: out["T_c"] - cfg.T_cin,
},
metric={"MSE": ppsci.metric.MSE()},
name="right_mse",
)
interior_validator = ppsci.validate.SupervisedValidator(
{
"dataset": {
"name": "NamedArrayDataset",
"input": test_interior_data,
"label": test_interior_label,
},
"batch_size": cfg.NTIME,
"sampler": {
"name": "BatchSampler",
"drop_last": False,
"shuffle": False,
},
},
ppsci.loss.MSELoss("mean"),
output_expr=equation["heat_exchanger"].equations,
metric={"MSE": ppsci.metric.MSE()},
name="interior_mse",
)
validator = {
left_validator.name: left_validator,
right_validator.name: right_validator,
interior_validator.name: interior_validator,
}
# directly evaluate pretrained model(optional)
solver = ppsci.solver.Solver(
model,
output_dir=cfg.output_dir,
equation=equation,
geom=geom,
validator=validator,
pretrained_model_path=cfg.EVAL.pretrained_model_path,
)
solver.eval()
# visualize prediction after finished training
visu_input["qm_c"] = np.full_like(visu_input["qm_c"], cfg.qm_h)
visu_input["qm_h"] = np.full_like(visu_input["qm_c"], cfg.qm_c)
pred = solver.predict(visu_input, return_numpy=True)
plot(visu_input, pred, cfg)
def export(cfg: DictConfig):
# set model
model = ppsci.arch.HEDeepONets(**cfg.MODEL)
# initialize solver
solver = ppsci.solver.Solver(
model,
pretrained_model_path=cfg.INFER.pretrained_model_path,
)
# export model
from paddle.static import InputSpec
input_spec = [
{key: InputSpec([None, 1], "float32", name=key) for key in model.input_keys},
]
solver.export(input_spec, cfg.INFER.export_path)
def inference(cfg: DictConfig):
from deploy.python_infer import pinn_predictor
predictor = pinn_predictor.PINNPredictor(cfg)
# set time-geometry
timestamps = np.linspace(0.0, 2, cfg.NTIME + 1, endpoint=True)
geom = {
"time_rect": ppsci.geometry.TimeXGeometry(
ppsci.geometry.TimeDomain(0.0, 1, timestamps=timestamps),
ppsci.geometry.Interval(0, cfg.DL),
)
}
input_dict = geom["time_rect"].sample_interior(cfg.NPOINT * cfg.NTIME, evenly=True)
test_h = np.random.rand(1).reshape([-1, 1]).astype("float32")
test_c = np.random.rand(1).reshape([-1, 1]).astype("float32")
# rearrange train data and eval data
input_dict["qm_h"] = np.tile(test_h, (cfg.NPOINT * cfg.NTIME, 1))
input_dict["qm_c"] = np.tile(test_c, (cfg.NPOINT * cfg.NTIME, 1))
input_dict["qm_c"] = np.full_like(input_dict["qm_c"], cfg.qm_h)
input_dict["qm_h"] = np.full_like(input_dict["qm_c"], cfg.qm_c)
output_dict = predictor.predict(
{key: input_dict[key] for key in cfg.INFER.input_keys}, cfg.INFER.batch_size
)
# mapping data to cfg.INFER.output_keys
output_dict = {
store_key: output_dict[infer_key]
for store_key, infer_key in zip(cfg.MODEL.output_keys, output_dict.keys())
}
plot(input_dict, output_dict, cfg)
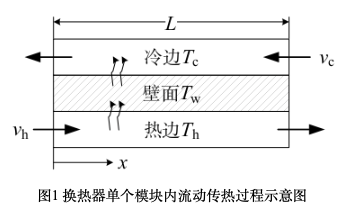
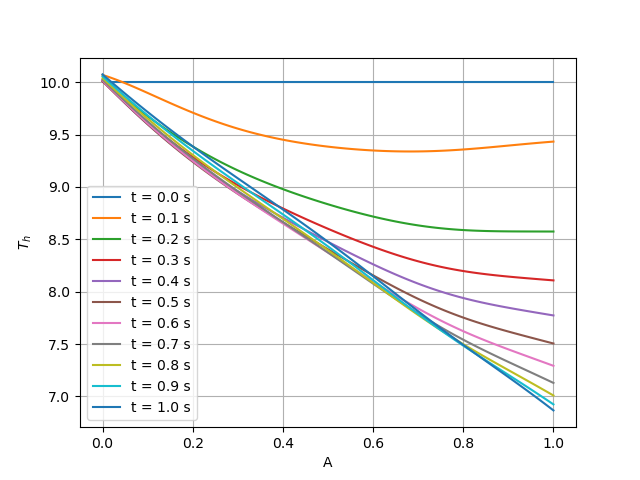
def plot(visu_input, pred, cfg: DictConfig):
x = visu_input["x"][: cfg.NPOINT]
# plot temperature of heat boundary
plt.figure()
y = np.full_like(pred["T_h"][: cfg.NPOINT], cfg.T_hin)
plt.plot(x, y, label="t = 0.0 s")
for i in range(10):
y = pred["T_h"][cfg.NPOINT * i * 2 : cfg.NPOINT * (i * 2 + 1)]
plt.plot(x, y, label=f"t = {(i+1)*0.1:,.1f} s")
plt.xlabel("A")
plt.ylabel(r"$T_h$")
plt.legend()
plt.grid()
plt.savefig("T_h.png")
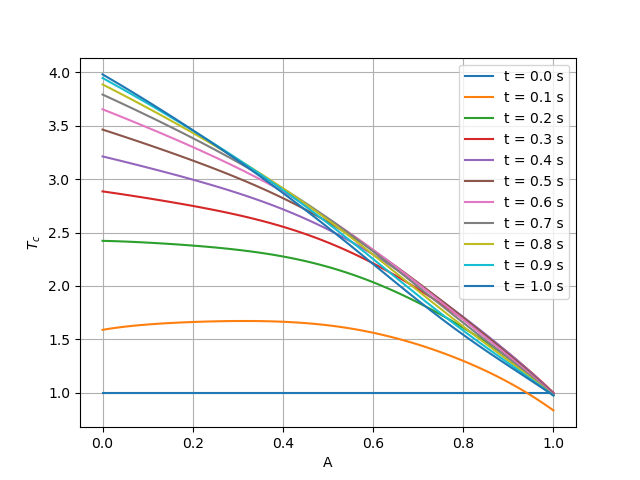
# plot temperature of cold boundary
plt.figure()
y = np.full_like(pred["T_c"][: cfg.NPOINT], cfg.T_cin)
plt.plot(x, y, label="t = 0.0 s")
for i in range(10):
y = pred["T_c"][cfg.NPOINT * i * 2 : cfg.NPOINT * (i * 2 + 1)]
plt.plot(x, y, label=f"t = {(i+1)*0.1:,.1f} s")
plt.xlabel("A")
plt.ylabel(r"$T_c$")
plt.legend()
plt.grid()
plt.savefig("T_c.png")
# plot temperature of wall
plt.figure()
y = np.full_like(pred["T_w"][: cfg.NPOINT], cfg.T_win)
plt.plot(x, y, label="t = 0.0 s")
for i in range(10):
y = pred["T_w"][cfg.NPOINT * i * 2 : cfg.NPOINT * (i * 2 + 1)]
plt.plot(x, y, label=f"t = {(i+1)*0.1:,.1f} s")
plt.xlabel("A")
plt.ylabel(r"$T_w$")
plt.legend()
plt.grid()
plt.savefig("T_w.png")
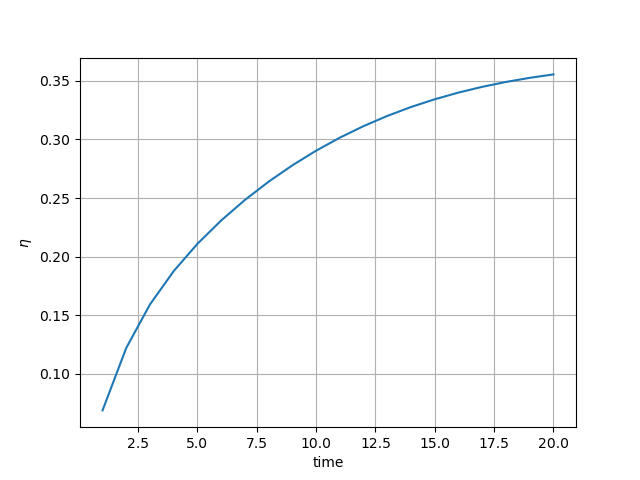
# plot the heat exchanger efficiency as a function of time.
plt.figure()
qm_min = np.min((visu_input["qm_h"][0], visu_input["qm_c"][0]))
eta = (
visu_input["qm_h"][0]
* (pred["T_h"][:: cfg.NPOINT] - pred["T_h"][cfg.NPOINT - 1 :: cfg.NPOINT])
/ (
qm_min
* (pred["T_h"][:: cfg.NPOINT] - pred["T_c"][cfg.NPOINT - 1 :: cfg.NPOINT])
)
)
x = list(range(1, cfg.NTIME + 1))
plt.plot(x, eta)
plt.xlabel("time")
plt.ylabel(r"$\eta$")
plt.grid()
plt.savefig("eta.png")
error = np.square(eta[-1] - cfg.eta_true)
logger.info(
f"The L2 norm error between the actual heat exchanger efficiency and the predicted heat exchanger efficiency is {error}"
)
@hydra.main(version_base=None, config_path="./conf", config_name="heat_exchanger.yaml")
def main(cfg: DictConfig):
if cfg.mode == "train":
train(cfg)
elif cfg.mode == "eval":
evaluate(cfg)
elif cfg.mode == "export":
export(cfg)
elif cfg.mode == "infer":
inference(cfg)
else:
raise ValueError(
f"cfg.mode should in ['train', 'eval', 'export', 'infer'], but got '{cfg.mode}'"
)
if __name__ == "__main__":
main()