3D-Brusselator¶
# linux
wget -P data -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/Brusselator3D/brusselator3d_dataset.npz
# windows
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/Brusselator3D/brusselator3d_dataset.npz --create-dirs -o data/brusselator3d_dataset.npz
python brusselator3d.py
# linux
wget -P data -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/Brusselator3D/brusselator3d_dataset.npz
# windows
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/Brusselator3D/brusselator3d_dataset.npz --create-dirs -o data/brusselator3d_dataset.npz
python brusselator3d.py mode=eval EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/Brusselator3D/brusselator3d_pretrained.pdparams
| Pretrained Model | Metrics |
|---|---|
| brusselator3d_pretrained.pdparams | loss(sup_validator): 14.51938 L2Rel.output(sup_validator): 0.07354 |
1. Background Introduction¶
This case introduces the Laplace Neural Operator (LNO) to build a deep learning network, which utilizes the Laplace transform to decompose the input space. Unlike the Fourier Neural Operator (FNO), LNO can handle non-periodic signals, consider transient responses, and exhibit exponential convergence. It combines the pole-residue relationship between input and output spaces, thereby achieving greater interpretability and improved generalization capabilities. A single Laplace layer in LNO approximates the accuracy of four Fourier modules in FNO, and for non-linear reaction-diffusion systems, the error of LNO is smaller than that of FNO.
This case studies the application of LNO network on the Brusselator reaction-diffusion system.
2. Problem Definition¶
Reaction-diffusion systems describe the changes in the concentration of chemical substances or particles over time and space, and are commonly used in chemistry, biology, geology, and physics. The diffusion-reaction equation can be expressed as:
Where \(y(x,t)\) represents the concentration of chemical substances or particles at position x and time t, \(f(x,t)\) is the source term, \(D\) is the diffusion coefficient, and \(k\) is the reaction rate.
3. Problem Solving¶
Next, we will explain how to convert the problem into PaddleScience code step by step and solve the problem using deep learning methods. In order to quickly understand PaddleScience, only key steps such as model construction, equation construction, and computational domain construction are described below, while other details please refer to API Documentation.
3.1 Dataset Introduction¶
The dataset is provided by the original code of the LNO paper, which contains training set input and label data, validation set input and label data. The data is stored in a .npz file and needs to be read before training.
Before running the code for this problem, please download the dataset and store it in the corresponding path:
3.2 Model Construction¶
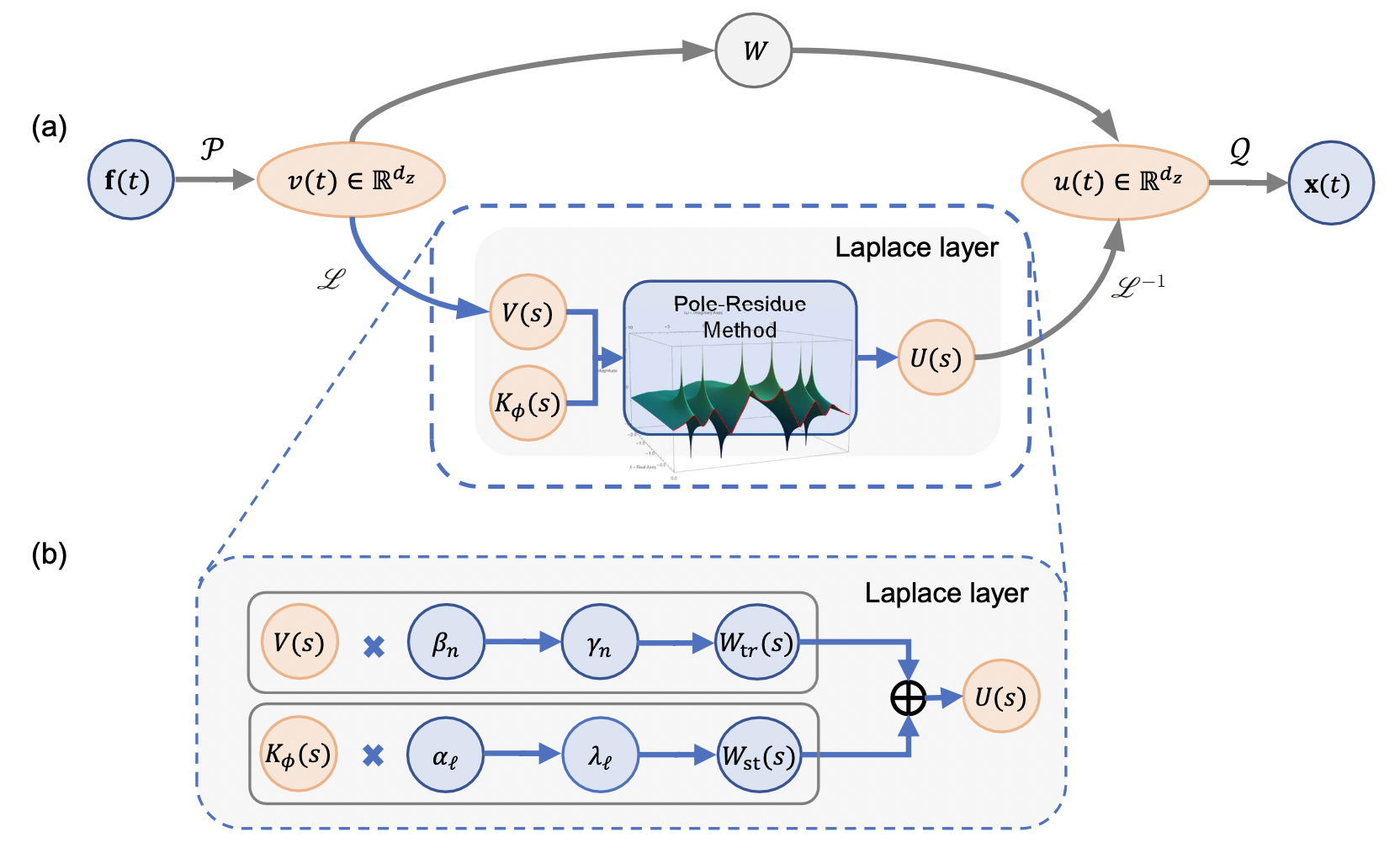
The above figure shows the overall LNO architecture and the schematic diagram of the Laplace layer. After the input data enters the network, it is first lifted to a higher dimension through a shallow neural network \(P\), then undergoes local linear transformation \(W\) on the one hand, and applies the Laplace layer on the other hand. The results of these two paths are then summed, and finally returned to the target dimension through a shallow neural network \(Q\).
In the Laplace layer, the top row represents applying the pole-residue method to calculate the transient response residue \(\gamma_{n}\) based on the system pole \(\mu_{n}\) and residue \(\beta_{n}\), representing the transient response in the Laplace domain. The bottom row represents applying the pole-residue method to calculate the steady-state response residue \(i\lambda_{l}\) based on the input pole \(i\omega_{l}\) and residue \(i\alpha_{l}\), representing the steady-state response in the Laplace domain.
For specific code, please refer to the lno.py file in Complete Code.
Before building the network, it is necessary to use linespace to clarify the length of each dimension according to the parameter settings, so that the LNO network can initialize \(\lambda\). Expressed in PaddleScience code as follows:
In addition, if use_grid in the model parameters is set to True, no preprocessing is required, and the model will automatically generate and add a grid. If it is False, the grid needs to be manually added to the data during data processing, and then input into the model:
3.3 Parameter and Hyperparameter Setting¶
We need to specify problem-related parameters, such as dataset path, length of each dimension, etc.
In addition, parameters such as training epochs and batch_size need to be specified in the configuration file.
3.4 Optimizer Construction¶
The training process will call the optimizer to update model parameters. Here, the AdamW optimizer is selected, and the StepDecay learning rate adjustment strategy commonly used in machine learning is used together.
The AdamW optimizer is an improvement based on the Adam optimizer, used to solve the problem of L2 regularization failure in the Adam optimizer.
3.5 Constraint Construction¶
This problem uses supervised learning for training, and there is only a supervised constraint SupervisedConstraint. The code is as follows:
The first parameter of SupervisedConstraint is the reading configuration of the supervised constraint, where the dataset field represents the training dataset information used, and each field represents:
name: Dataset type, hereNamedArrayDatasetmeans dataset read from Array;input: Input data of Array type;label: Label data of Array type;
The batch_size field represents the size of the batch;
The sampler field represents the sampling method, where each field represents:
name: Sampler type, hereBatchSamplermeans batch sampler;drop_last: Whether to discard the last samples that cannot make up a mini-batch, set to False;shuffle: Whether to shuffle the order when generating sample indices, set to True;
The num_workers field represents the number of threads when loading input;
The second parameter is the loss function. Here, the commonly used L2Rel loss function is selected, and reduction is set to "sum", that is, the loss terms generated by all data points involved in the calculation are summed;
The third parameter is the name of the constraint condition. We need to name each constraint condition for subsequent indexing.
3.6 Validator Construction¶
Usually during the training process, the training status of the current model is evaluated using the validation set (test set) at a certain epoch interval, so a validator needs to be built:
Most parameter meanings are similar to those in the constraint, with the following differences:
The third parameter is the output transcription formula output_expr, which specifies the key and value of the final input data;
The fourth parameter is the error evaluation function. Here, the L2Rel Error function is selected, and reduction is not set, which is the default value "mean", averaging the Error generated by all data points involved in the calculation.
3.7 Model Training and Evaluation¶
After completing the above settings, you only need to pass the instantiated objects to ppsci.solver.Solver in order, and then start training and evaluation.
4. Complete Code¶
| brusselator3d.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 | |
| lno.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 | |
5. Result Display¶
The following shows the prediction results and labels on the validation set.
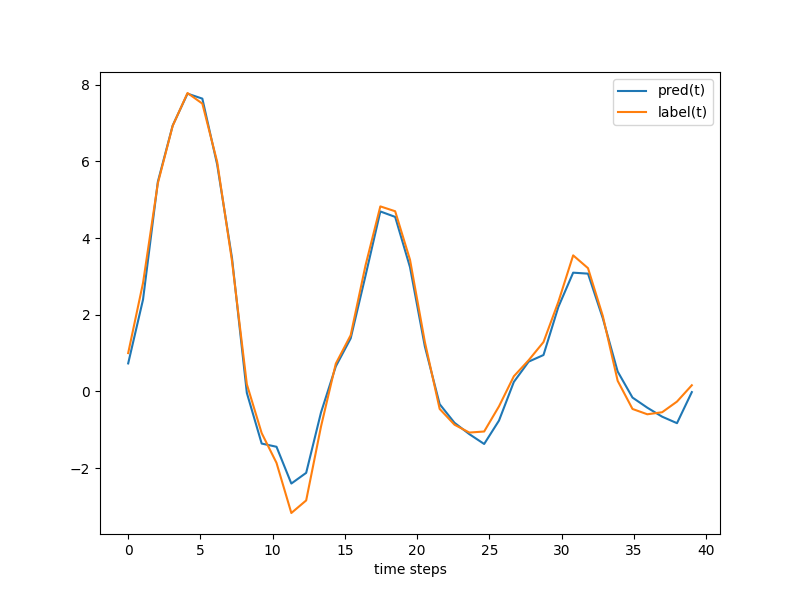
It can be seen that the model prediction results are basically consistent with the labels.