PIRBN¶
1. Background Introduction¶
We recently discovered that trained Physics-Informed Neural Networks (PINNs) tend to become local approximation functions. This observation prompted us to develop a new type of Physics-Informed Radial Basis Network (PIRBN) that maintains local approximation properties throughout the training process. Unlike deep neural networks, PIRBN contains only one hidden layer and a radial basis "activation" function. Under appropriate conditions, we prove that training PIRBN using gradient descent methods can converge to a Gaussian process. In addition, we investigate the training dynamics of PIRBN through Neural Tangent Kernel (NTK) theory. Furthermore, we conduct a comprehensive investigation on the initialization strategies of PIRBN. Based on numerical examples, we find that PIRBN is more effective than PINN in solving nonlinear partial differential equations with high-frequency features and ill-posed computational domains. Moreover, existing PINN numerical techniques such as adaptive learning, decomposition, and different types of loss functions are also applicable to PIRBN.
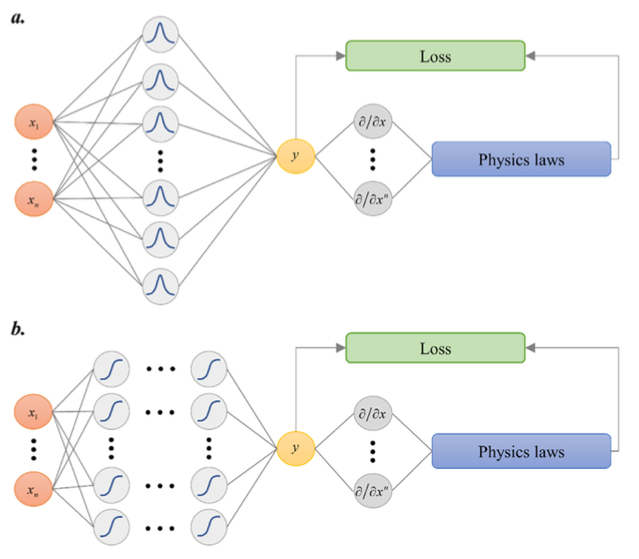
The left side of the picture shows the input layer, hidden layer, and output layer of a common neural network structure. The hidden layer contains an activation layer. (a) is a single hidden layer, and (b) is a multi-hidden layer. The right side of the picture shows the activation function of the PIRBN network, calculating the network's Loss and backpropagating. The picture illustrates that when using PIRBN, each RBF neuron is activated only when the input is close to the neuron center. Intuitively, PIRBN has local approximation properties. Training a PIRBN via gradient descent algorithm can also be analyzed through NTK theory.
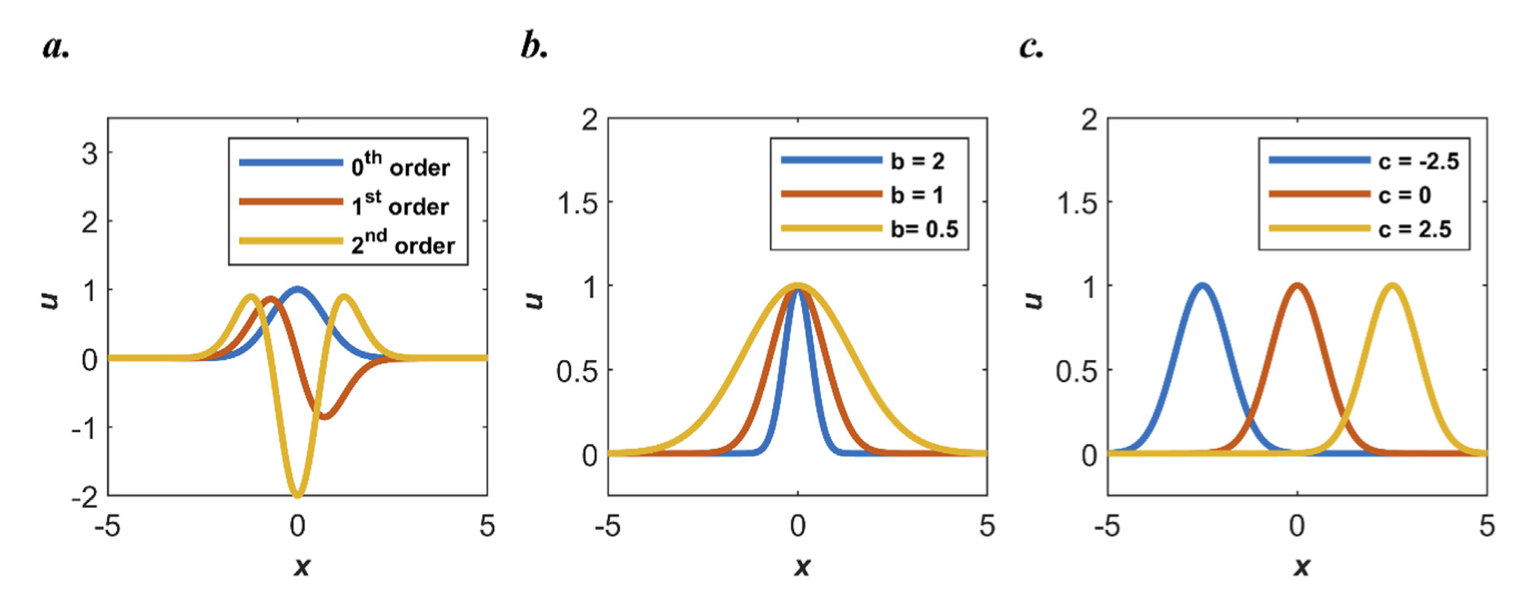
(a) 0, 1, 2 order Gaussian activation functions (b) Setting different b values (c) Setting different c values
When using a Gaussian function as an activation function, the mapping relationship between input and output can be mathematically represented as some form of Gaussian function. RBF network is a neural network commonly used for pattern recognition, data interpolation and function approximation. Its key feature is using radial basis functions as activation functions, giving the network better global approximation capabilities and flexibility.
2. Problem Definition¶
With the help of NTK and NTK-based adaptive training methods, the performance of PINN in handling problems with high-frequency features can be significantly improved. For example, consider a partial differential equation and its boundary conditions:
Where \(\mu\) is a constant that controls the frequency characteristics of the PDE solution.
3. Problem Solving¶
Next, we will explain how to convert the problem into PaddlePaddle code step by step and solve the problem using deep learning methods. In order to quickly understand PaddlePaddle, only key steps such as model construction, equation construction, and computational domain construction are described below, while other details please refer to API Documentation.
3.1 Model Construction¶
In the PIRBN problem, build the network, expressed in PaddlePaddle code as follows
3.2 Data Construction¶
This case involves reading data construction, as shown below
3.3 Training and Evaluation Construction¶
Training and evaluation construction, setting loss calculation function, return fields, code is shown below:
3.4 Hyperparameter Setting¶
Next we need to specify the number of training epochs. Here we use 20001 training epochs based on experimental experience.
3.5 Optimizer Construction¶
The training process will call the optimizer to update model parameters. Here, the Adam optimizer is selected and learning_rate is set to 1e-3.
3.6 Model Training and Evaluation¶
Model training and evaluation
4. Complete Code¶
5. Result Display¶
The PINN case was experimented with parameter configuration of epoch=20001 and learning_rate=1e-3, and the result returned Loss was 0.13567.
The PIRBN case was experimented with parameter configuration of epoch=20001 and learning_rate=1e-3, and the result returned Loss was 0.59471.
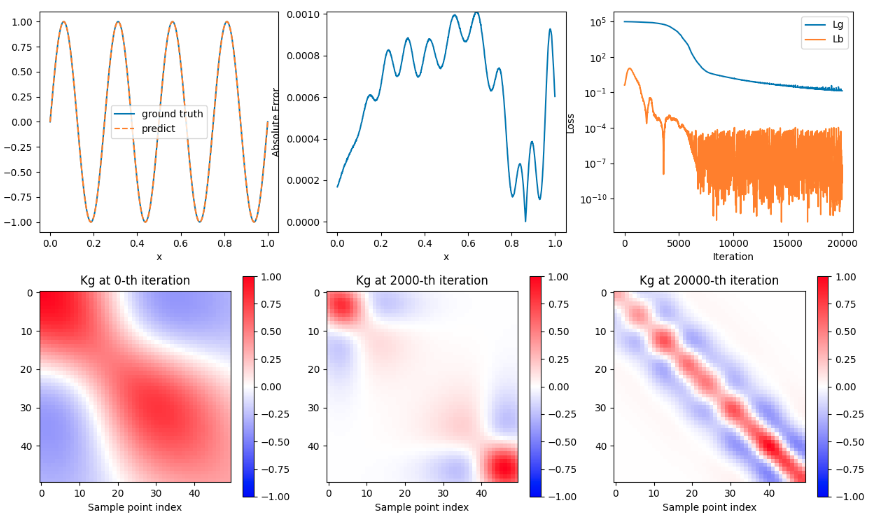
The figure uses hyperbolic tangent function (tanh) as activation function, and uses LuCun initialization method to initialize all parameters in the neural network.
- Subplot 1 shows the curve comparison of predicted value and true value
- Subplot 2 shows the error value
- Subplot 3 shows the loss value
- Subplot 4 shows the Kg graph for 1 training
- Subplot 5 shows the Kg graph for 2000 trainings
- Subplot 6 shows the Kg graph for 20000 trainings
It can be seen that the predicted value and the true value match, the error value gradually increases and then gradually decreases, the Loss history decreases and then fluctuates, and the Kg graph gradually converges as the number of trainings increases.
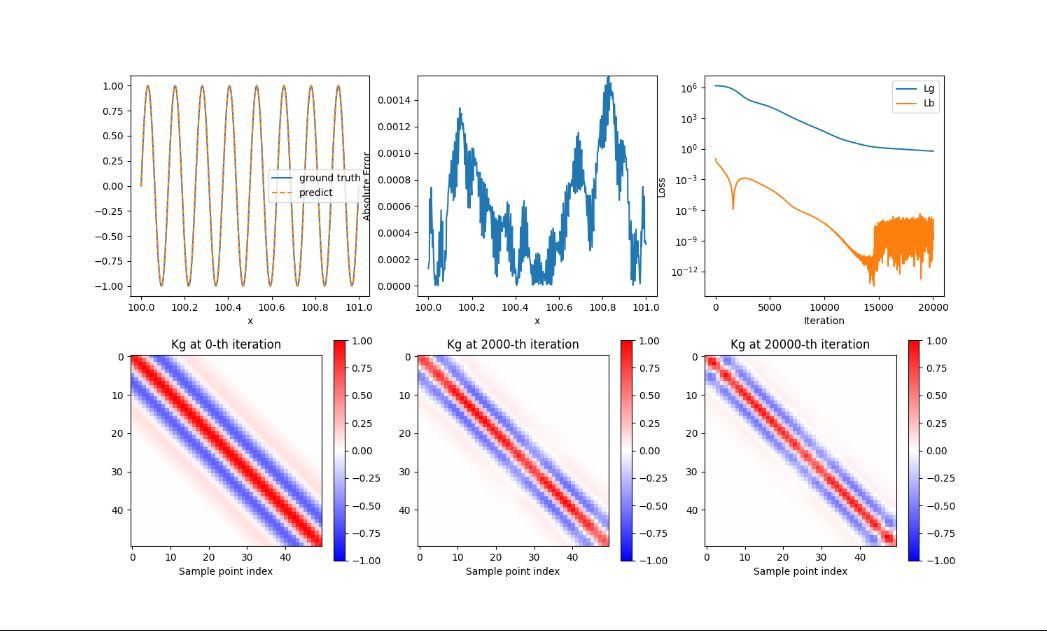
The figure uses data generated by Gaussian function as activation function, and uses LuCun initialization method to initialize all parameters in the neural network.
- Subplot 1 shows the curve comparison of predicted value and true value
- Subplot 2 shows the error value
- Subplot 3 shows the loss value
- Subplot 4 shows the Kg graph for 1 training
- Subplot 5 shows the Kg graph for 2000 trainings
- Subplot 6 shows the Kg graph for 20000 trainings
It can be seen that the predicted value and the true value match, the error value gradually increases and then gradually decreases and then increases again, the Loss history decreases and then fluctuates, and the Kg graph gradually converges as the number of trainings increases.