Mean ZSS distance(srsd-feynman_easy): 0.658 +- 0.390 Hit rate(srsd-feynman_easy): 8/30 Mean ZSS distance(srsd-feynman_medium): 0.674 +- 0.331 Hit rate(srsd-feynman_medium): 8/37 Mean ZSS distance(srsd-feynman_hard): 0.737 +- 0.188 Hit rate(srsd-feynman_hard): 1/39
Symbolic Regression (SR) searches for mathematical expressions that best describe numerical datasets. It is roughly divided into three categories: GP-based SR (Genetic Programming-based Symbolic Regression), ML-based SR (Machine Learning-based Symbolic Regression), and DL-based SR (Deep Learning-based Symbolic Regression). The computational cost of GP-based SR algorithms is usually high, so this case uses a new Transformer model for symbolic regression, and applies the best model to the SRSD dataset (Symbolic Regression for Scientific Discovery dataset) for inference and testing.
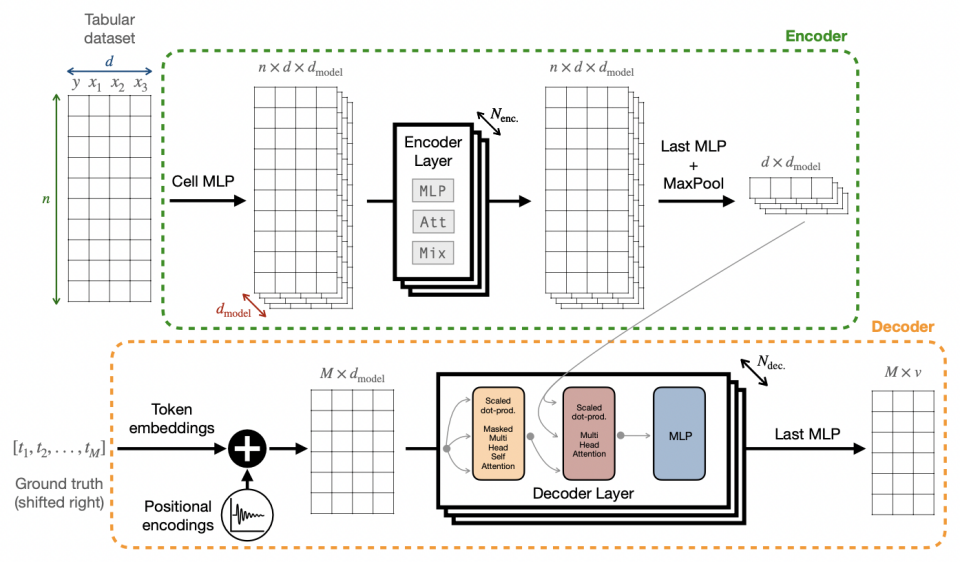
The authors propose a Transformer-based SR model, called Transformer4SR (A Transformer Model for Symbolic regression towards Scientific Discovery), which is used to deal with the closed library problem, converting the predefined vocabulary of symbolic regression into tokens using a specific method. In this case, the input data is generated by a program, the data passes through the model to obtain the output result, and then it is converted back to symbolic representation to finally obtain the symbolic regression result of the data.
The figure below is the network structure diagram of this method. The structure is based on Transformer and has two main parts: Encoder and Decoder.
The authors propose three encoder architectures: MLP, Att or Mix. In this case, the encoder structure under Mix is mainly implemented. The decoder is a standard Transformer decoder. During training, the encoder receives a tabular dataset, and the decoder receives a sequence of ground truth values of tokens, while during inference, the decoder is independent and predicts tokens in an autoregressive manner.
Next, we will explain how to convert the problem into PaddleScience code step by step and solve the problem using deep learning methods.
In order to quickly understand PaddleScience, only key steps such as model construction, equation construction, and computational domain construction are described below, while other details please refer to API Documentation.
The training data used in this case is data autonomously generated by the case: first use symbols in the symbol library to randomly generate a large number of formulas; then filter out invalid or non-compliant formulas through a certain screening mechanism; finally sample according to these formulas; finally obtain input datasets and label data.
The parameter information for generating data is as follows:
DATA_GENERATE:# output pathdata_path:"./data_generated/"# filtersnum_nodes:[2,15]# number of nodesnum_nested_max:6# multiple levels of nestingnum_consts:[1,1]# number of constants(C)num_vars:[1,6]# number of variables(x1,x2,...)seq_length_max:30order_of_mag_limit:1.0e+9# magnitude of value# othersnum_init_trials:100000# number of initial trialsnum_sampling_per_eq:25# number of times to evaluate constants for each unique equationsampling_times:50# the number of observationsvar_type:"normal"# variable representation, 'normal' is (y, x1, x2, ...), 'log' is log(abs(y, x1, x2, ...)), or 'both'num_zfill:8DATA:
Among them, num_init_trials is the number of randomly generated initial equations. The larger this value, the more data is generated. In the original paper, this value is 1000000.
After setting relevant parameters, you can use the following command to generate the dataset:
We also generated a dataset 10 times smaller than the original training data in advance (i.e., num_init_trials is 100000) for simple model training, and provided a download link:
This case validates the model on the open source symbolic regression dataset SRSD (Rethinking Symbolic Regression Datasets and Benchmarks for Scientific Discovery), so this dataset needs to be pre-downloaded. The dataset is stored on huggingface, and the addresses are srsd-feynman_easy, srsd-feynman_medium, srsd-feynman_hard. Can be downloaded from the corresponding webpage or using git:
Since data reading and conversion are relatively complicated, dataset-related functions are defined in the functions_data.py file and called during model training, validation, etc.
Reading autonomously generated datasets during training:
data_path_srsd:["./srsd-feynman_easy/"]ratio:[0.8,0.1,0.1]sampling_times:${DATA_GENERATE.sampling_times}seq_length_max:30# ${DATA_GENERATE.seq_length_max}response_variable:["y","x1","x2","x3","x4","x5","x6"]# maximum number of variables is len(response_variable)=7vocab_library:["add","mul","sin",
# set modelnum_var_max=len(cfg.DATA.response_variable)vocab_size=len(cfg.DATA.vocab_library)+2model=ppsci.arch.Transformer(**cfg.MODEL,num_var_max=num_var_max,vocab_size=vocab_size,seq_length=data_funcs.seq_length_max,)
In order to accurately and quickly access the value of specific variables during calculation, we specify here that the input variable name of the network model is ("input", "target_seq"), and the output variable name is ("output", ). These names are consistent with subsequent code.
This case uses a custom learning rate strategy LambdaDecay, which supports custom learning rate decay functions. The training process will call the optimizer to update model parameters. Here, the commonly used Adam optimizer is selected.
# set optimizerdeflr_lambda(step,d_model=cfg.MODEL.d_model,warmup=cfg.TRAIN.lr_warmup):ifstep==0:step=1lr=d_model**(-0.5)*min(step**(-0.5),step*warmup**(-1.5))returnlrlr_scheduler=ppsci.optimizer.lr_scheduler.LambdaDecay(**cfg.TRAIN.lr_scheduler,lr_lambda=lr_lambda,)()optimizer=ppsci.optimizer.Adam(lr_scheduler,**cfg.TRAIN.adam)(model)
# set constraintsup_constraint=ppsci.constraint.SupervisedConstraint({"dataset":{"name":"NamedArrayDataset","input":{"input":data_funcs.values_train.astype(paddle.get_default_dtype()),"target_seq":data_funcs.targets_train[:,:-1],},"label":{"output":data_funcs.targets_train[:,1:]},},"batch_size":cfg.TRAIN.batch_size,"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":True,},"num_workers":1,},ppsci.loss.FunctionalLoss(cross_entropy_loss_func),name="sup_constraint",)
The first parameter of SupervisedConstraint is the reading configuration of supervised constraint, where dataset field represents the training dataset information used, and each field respectively represents:
name: Dataset type, here NamedArrayDataset represents the dataset type is Array;
input: Input data;
label: Label data;
batch_size field represents the size of batch;
sampler field represents sampling method, where each field represents:
name: Sampler type, here BatchSampler represents batch sampler;
drop_last: Whether to discard the last samples that cannot make up a mini-batch;
shuffle: Whether to shuffle the order when generating sample subscripts;
The second parameter is the loss function. Here FunctionalLoss is a PaddleScience custom loss function class, which supports custom loss calculation method when writing code. The specific implementation of loss is its parameter cross_entropy_loss_func, which is a function defined in the functions_loss_metric.py file, as shown below:
Usually during the training process, the training status of the current model is evaluated using the validation set (test set) at a certain epoch interval, so ppsci.validate.SupervisedValidator is used to construct the validator. The construction process is similar to Constraint Construction.
defcompute_inaccuracy(output_dict:Dict[str,paddle.Tensor],label_dict:Dict[str,paddle.Tensor],*args,)->Dict[str,paddle.Tensor]:"""Calculate the ratio of incorrectly matched tokens to the total number."""preds=output_dict["output"]labels=label_dict["output"]padding_not_mask=labels!=0correct_bool=paddle.equal(paddle.argmax(preds,axis=-1),labels)correct_bool=paddle.logical_and(correct_bool,padding_not_mask,)inacc=1-paddle.sum(correct_bool)/paddle.sum(padding_not_mask)return{"inaccuracy_mean":inacc}
After completing the above settings, you only need to pass the instantiated objects to ppsci.solver.Solver in order, and then start training and evaluation.
This case validates the model on the open source symbolic regression dataset SRSD (Rethinking Symbolic Regression Datasets and Benchmarks for Scientific Discovery). During verification, the decoder is run in an autoregressive manner, and the encoder does not need to be run. The metric during verification is a normalized metric ZSS based on tree edit distance.
num_repeat=cfg.EVAL.num_repeatifisinstance(data_funcs,SRSDDataFuncs)else1num_samples=data_funcs.values_test.shape[0]zss_dist=np.zeros((num_repeat,num_samples))foriintqdm(range(num_repeat),desc="Evaluating"):encoder_input=paddle.to_tensor(data_funcs.values_test,dtype=paddle.get_default_dtype())preds=model.decode_process(encoder_input,is_tree_complete)labels=paddle.to_tensor(data_funcs.targets_test)forjinrange(num_samples):try:pred_simplify=simplify_output(preds[j],"tensor")zss_dist[i][j]=compute_norm_zss_dist(pred_simplify[0],labels[j])exceptException:zss_dist[i][j]=np.nanifi!=num_repeat-1:# reload data to increase randomnessdata_funcs.init_data("test")zss_dist_mean=np.nanmean(zss_dist,axis=0)zss_dist_std=np.nanstd(zss_dist,axis=0)zss_dist_min=np.nanmin(zss_dist,axis=0)zss_dist_max=np.nanmax(zss_dist,axis=0)try:
The visualization code is defined in the file functions_vis.py. In addition to visualizing the results in the validation set, a visualization result of a demo with the formula \(25*x1+x2*log(x1)\) is also provided:
# Copyright (c) 2024 PaddlePaddle Authors. All Rights Reserved.## Licensed under the Apache License, Version 2.0 (the "License");# you may not use this file except in compliance with the License.# You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License."""Reference: https://github.com/omron-sinicx/transformer4sr"""importhydraimportnumpyasnpimportpaddlefromfunctions_dataimportDataFuncsfromfunctions_dataimportSRSDDataFuncsfromfunctions_loss_metricimportcompute_inaccuracyfromfunctions_loss_metricimportcross_entropy_loss_funcfromfunctions_visimportVisualizeFuncsfromomegaconfimportDictConfigfromtqdmimporttqdmfromutilsimportcompute_norm_zss_distfromutilsimportis_tree_completefromutilsimportsimplify_outputimportppscideftrain(cfg:DictConfig):# datadata_funcs=DataFuncs(cfg.DATA.data_path,cfg.DATA.vocab_library,cfg.DATA.seq_length_max,cfg.DATA.ratio,shuffle=True,)# set modelnum_var_max=len(cfg.DATA.response_variable)vocab_size=len(cfg.DATA.vocab_library)+2model=ppsci.arch.Transformer(**cfg.MODEL,num_var_max=num_var_max,vocab_size=vocab_size,seq_length=data_funcs.seq_length_max,)# set optimizerdeflr_lambda(step,d_model=cfg.MODEL.d_model,warmup=cfg.TRAIN.lr_warmup):ifstep==0:step=1lr=d_model**(-0.5)*min(step**(-0.5),step*warmup**(-1.5))returnlrlr_scheduler=ppsci.optimizer.lr_scheduler.LambdaDecay(**cfg.TRAIN.lr_scheduler,lr_lambda=lr_lambda,)()optimizer=ppsci.optimizer.Adam(lr_scheduler,**cfg.TRAIN.adam)(model)# set constraintsup_constraint=ppsci.constraint.SupervisedConstraint({"dataset":{"name":"NamedArrayDataset","input":{"input":data_funcs.values_train.astype(paddle.get_default_dtype()),"target_seq":data_funcs.targets_train[:,:-1],},"label":{"output":data_funcs.targets_train[:,1:]},},"batch_size":cfg.TRAIN.batch_size,"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":True,},"num_workers":1,},ppsci.loss.FunctionalLoss(cross_entropy_loss_func),name="sup_constraint",)# wrap constraints togetherconstraint={sup_constraint.name:sup_constraint}# set validatorsup_validator=ppsci.validate.SupervisedValidator({"dataset":{"name":"NamedArrayDataset","input":{"input":data_funcs.values_val.astype(paddle.get_default_dtype()),"target_seq":data_funcs.targets_val[:,:-1],},"label":{"output":data_funcs.targets_val[:,1:]},},"batch_size":cfg.TRAIN.batch_size,"num_workers":1,},ppsci.loss.FunctionalLoss(cross_entropy_loss_func),metric={"metric":ppsci.metric.FunctionalMetric(compute_inaccuracy)},name="sup_validator",)# wrap validator togethervalidator={sup_validator.name:sup_validator}# initialize solversolver=ppsci.solver.Solver(model,constraint,optimizer=optimizer,validator=validator,cfg=cfg,)# train modelsolver.train()# evaluate after finished trainingsolver.eval()defevaluate(cfg:DictConfig):# datadata_funcs=SRSDDataFuncs(cfg.DATA.data_path_srsd,cfg.DATA.sampling_times,cfg.DATA.response_variable,cfg.DATA.vocab_library,cfg.DATA.seq_length_max,shuffle=True,)# set modelnum_var_max=len(cfg.DATA.response_variable)vocab_size=len(cfg.DATA.vocab_library)+2model=ppsci.arch.Transformer(**cfg.MODEL,num_var_max=num_var_max,vocab_size=vocab_size,seq_length=data_funcs.seq_length_max,)ppsci.utils.save_load.load_pretrain(model,path=cfg.EVAL.pretrained_model_path)model.eval()# evaluatenum_repeat=cfg.EVAL.num_repeatifisinstance(data_funcs,SRSDDataFuncs)else1num_samples=data_funcs.values_test.shape[0]zss_dist=np.zeros((num_repeat,num_samples))foriintqdm(range(num_repeat),desc="Evaluating"):encoder_input=paddle.to_tensor(data_funcs.values_test,dtype=paddle.get_default_dtype())preds=model.decode_process(encoder_input,is_tree_complete)labels=paddle.to_tensor(data_funcs.targets_test)forjinrange(num_samples):try:pred_simplify=simplify_output(preds[j],"tensor")zss_dist[i][j]=compute_norm_zss_dist(pred_simplify[0],labels[j])exceptException:zss_dist[i][j]=np.nanifi!=num_repeat-1:# reload data to increase randomnessdata_funcs.init_data("test")zss_dist_mean=np.nanmean(zss_dist,axis=0)zss_dist_std=np.nanstd(zss_dist,axis=0)zss_dist_min=np.nanmin(zss_dist,axis=0)zss_dist_max=np.nanmax(zss_dist,axis=0)try:keys=data_funcs.keys_testassertlen(keys)==num_samplesexceptException:keys=[f"sample_{i}"foriinrange(num_samples)]print(f"zss_distance and accuracy in {num_repeat} attempts of {num_samples} samples with format: name => mean +- std | min ~ max")foriinrange(num_samples):key=keys[i]print(f"{key} => {zss_dist_mean[i]:.3f} +- {zss_dist_std[i]:.3f} | {zss_dist_min[i]:.3f} ~ {zss_dist_max[i]:.3f}")print("-----------")print(f"=> Mean ZSS distance: {np.nanmean(zss_dist):.3f} +- {np.nanstd(zss_dist):.3f}")print(f"=> Hit rate: {np.sum(np.any(zss_dist==0,axis=0))}/{zss_dist.shape[1]}")# visualize predictionvisualizer=VisualizeFuncs(model)visualizer.visualize_valid_data(data_funcs.targets_test,data_funcs.values_test,10)visualizer.visualize_demo()defexport(cfg:DictConfig):deftemporary_complete_func(seq_indices):".utils.is_tree_complete is not work in static gragh now."arity=1forninseq_indices:n=n.item()ifn==0orn==1:continueprint("Predict padding or <SOS>, which is bad...")ifn==2orn==3:arity=arity+2-1elifninrange(4,13):arity=arity+1-1elifninrange(13,20):arity=arity+0-1ifarity==0:returnTrueelse:returnFalseclassWarppedModel(ppsci.arch.Transformer):def__init__(self,*args,complete_func,**kwargs):super().__init__(*args,**kwargs)self.complete_func=complete_funcdefforward(self,x):return{"output":self.decode_process(x["input"],self.complete_func)}# set modelnum_var_max=len(cfg.DATA.response_variable)vocab_size=len(cfg.DATA.vocab_library)+2warpped_model=WarppedModel(**cfg.MODEL,num_var_max=num_var_max,vocab_size=vocab_size,seq_length_max=cfg.DATA.seq_length_max,complete_func=temporary_complete_func,)warpped_model.eval()# initialize solversolver=ppsci.solver.Solver(warpped_model,pretrained_model_path=cfg.INFER.pretrained_model_path,)# export modelfrompaddle.staticimportInputSpecinput_spec=[{"input":InputSpec([None,cfg.DATA.sampling_times,len(cfg.DATA.response_variable),1],"float32",name="input",)}]solver.export(input_spec,cfg.INFER.export_path)definference(cfg:DictConfig):importsympyfromdeploy.python_inferimportpinn_predictorpredictor=pinn_predictor.PINNPredictor(cfg)C,y,x1,x2,x3,x4,x5,x6=sympy.symbols("C, y, x1, x2, x3, x4, x5, x6",real=True,positive=True)y=25*x1+x2*sympy.log(x1)print("The ground truth is:",y)x1_values=np.power(10.0,np.random.uniform(-1.0,1.0,size=50))x2_values=np.power(10.0,np.random.uniform(-1.0,1.0,size=50))f=sympy.lambdify([x1,x2],y)y_values=f(x1_values,x2_values)dataset=np.zeros((50,7))dataset[:,0]=y_valuesdataset[:,1]=x1_valuesdataset[:,2]=x2_valuesencoder_input=dataset[np.newaxis,:,:,np.newaxis].astype(np.float32)output_dict=predictor.predict({"input":encoder_input},cfg.INFER.batch_size)output_dict={store_key:output_dict[infer_key]forstore_key,infer_keyinzip(("output",),output_dict.keys())}sympy_pred=simplify_output(output_dict["output"][0],"sympy")print("The prediction is:",sympy_pred)@hydra.main(version_base=None,config_path="./conf",config_name="transformer4sr.yaml")defmain(cfg:DictConfig):ifcfg.mode=="train":train(cfg)elifcfg.mode=="eval":evaluate(cfg)elifcfg.mode=="export":export(cfg)elifcfg.mode=="infer":inference(cfg)else:raiseValueError(f"cfg.mode should in ['train', 'eval'], but got '{cfg.mode}'")if__name__=="__main__":main()
@inproceedings{lalande2023,
title = {A Transformer Model for Symbolic Regression towards Scientific Discovery},
author = {Florian Lalande and Yoshitomo Matsubara and Naoya Chiba and Tatsunori Taniai and Ryo Igarashi and Yoshitaka Ushiku},
booktitle = {NeurIPS 2023 AI for Science Workshop},
year = {2023},
url = {https://openreview.net/forum?id=AIfqWNHKjo},
}