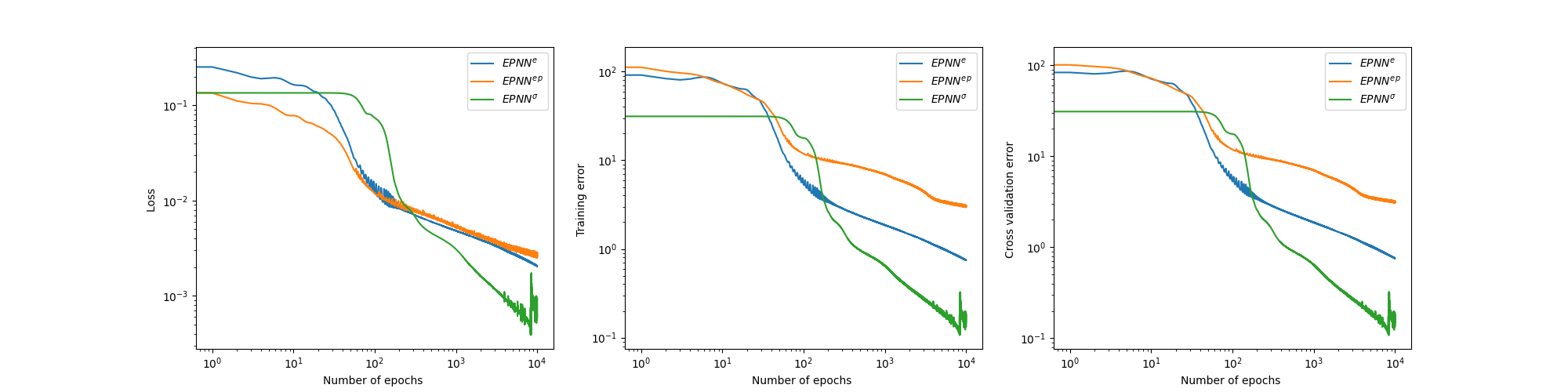
Here we mainly reproduce the Physics-Informed Neural Network (PINN) surrogate model of the Elasto-Plastic Neural Network (EPNN). Incorporating these physics into the architecture of neural networks can train the network more effectively while using less data for training, and at the same time enhance inference capabilities for loading regimes outside the training data. The architecture of EPNN is model and material agnostic, meaning it can adapt to various types of elastoplastic materials, including geomaterials and metals; and experimental data can be used directly to train the network. To demonstrate the robustness of the proposed architecture, we apply its general framework to the elastoplastic behavior of sand. EPNN outperforms conventional neural network architectures in predicting unobserved strain-controlled loading paths for sands of different initial densities.
Next, we will explain how to convert the problem into PaddleScience code step by step and solve the problem using deep learning methods.
In order to quickly understand PaddleScience, only key steps such as model construction, equation construction, and computational domain construction are described below, while other details please refer to API Documentation.
EPNN parameters input_keys are input field names, output_keys are output field names, node_sizes are node size lists, activations are activation function string lists, and drop_p is node dropout probability.
Here, Data is used to read files to construct the data class, then get_shuffled_data is used to shuffle the data, then the number of shuffled data itrain to be obtained is calculated, and finally get is used to obtain 10 groups of data with the quantity of itrain for each group.
The first parameter of SupervisedConstraint is the reading configuration of the supervised constraint. The "dataset" field in the configuration represents the training dataset information used, and its various fields represent:
name: Dataset type, here "NamedArrayDataset" means sequentially read dataset;
input: Input dataset;
label: Label dataset;
The second parameter is the loss function, here the custom function train_loss_func is used.
The third parameter is the equation expression, used to describe how to calculate the constraint target. The calculated value will be stored in the output list according to the specified name, so as to ensure that these values can be used when calculating loss.
The fourth parameter is the name of the constraint condition. We need to name each constraint condition for subsequent indexing.
After the constraint is constructed, encapsulate it into a dictionary with the name we just named as the key for subsequent access.
Similar to constraints, this problem uses ppsci.validate.SupervisedValidator to build a validator. The parameter meanings are also similar to Constraint Construction. The only difference is the evaluation metric metric. The code is as follows:
The training process will call the optimizer to update model parameters. Here, the more commonly used Adam optimizer is selected, and combined with the ExponentialDecay learning rate adjustment strategy commonly used in machine learning.
Since multiple models are used, multiple optimizers need to be set. For the EPNN network part, Adam optimizer needs to be set.
Since this problem includes unsupervised learning and there is no label data in the data, the loss is calculated based on the returned data of the model, so a custom loss is required. The method is to first define relevant functions, and then pass the function name as a parameter to FunctionalLoss and FunctionalMetric.
Note that the input and output parameters of the custom loss function need to be consistent with other functions such as MSE in PaddleScience, that is, the input is the model output output_dict and other dictionary variables, and the loss function output is the loss value paddle.Tensor.
The relevant custom loss function is calculated using MAELoss, code is
)}deftrain_loss_func(output_dict,*args)->paddle.Tensor:"""For model calculation of loss in model.train(). Args: output_dict (Dict[str, paddle.Tensor]): The output dict. Returns: paddle.Tensor: Loss value. """
# Copyright (c) 2023 PaddlePaddle Authors. All Rights Reserved.## Licensed under the Apache License, Version 2.0 (the "License");# you may not use this file except in compliance with the License.# You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License."""Reference: https://github.com/meghbali/ANNElastoplasticity"""fromosimportpathasospimportfunctionsimporthydrafromomegaconfimportDictConfigimportppscifromppsci.utilsimportloggerdeftrain(cfg:DictConfig):# set random seed for reproducibilityppsci.utils.misc.set_random_seed(cfg.seed)# initialize loggerlogger.init_logger("ppsci",osp.join(cfg.output_dir,f"{cfg.mode}.log"),"info")(input_dict_train,label_dict_train,input_dict_val,label_dict_val,)=functions.get_data(cfg.DATASET_STATE,cfg.DATASET_STRESS,cfg.NTRAIN_SIZE)model_list=functions.get_model_list(cfg.MODEL.ihlayers,cfg.MODEL.ineurons,input_dict_train["state_x"][0].shape[1],input_dict_train["state_y"][0].shape[1],input_dict_train["stress_x"][0].shape[1],)optimizer_list=functions.get_optimizer_list(model_list,cfg)model_state_elasto,model_state_plastic,model_stress=model_listmodel_list_obj=ppsci.arch.ModelList(model_list)def_transform_in_stress(_in):returnfunctions.transform_in_stress(_in,model_state_elasto,"out_state_elasto")model_state_elasto.register_input_transform(functions.transform_in)model_state_plastic.register_input_transform(functions.transform_in)model_stress.register_input_transform(_transform_in_stress)model_stress.register_output_transform(functions.transform_out)output_keys=["state_x","state_y","stress_x","stress_y","out_state_elasto","out_state_plastic","out_stress",]sup_constraint_pde=ppsci.constraint.SupervisedConstraint({"dataset":{"name":"NamedArrayDataset","input":input_dict_train,"label":label_dict_train,},"batch_size":1,"num_workers":0,},ppsci.loss.FunctionalLoss(functions.train_loss_func),{key:(lambdaout,k=key:out[k])forkeyinoutput_keys},name="sup_train",)constraint_pde={sup_constraint_pde.name:sup_constraint_pde}sup_validator_pde=ppsci.validate.SupervisedValidator({"dataset":{"name":"NamedArrayDataset","input":input_dict_val,"label":label_dict_val,},"batch_size":1,"num_workers":0,},ppsci.loss.FunctionalLoss(functions.eval_loss_func),{key:(lambdaout,k=key:out[k])forkeyinoutput_keys},metric={"metric":ppsci.metric.FunctionalMetric(functions.metric_expr)},name="sup_valid",)validator_pde={sup_validator_pde.name:sup_validator_pde}# initialize solversolver=ppsci.solver.Solver(model_list_obj,constraint_pde,cfg.output_dir,optimizer_list,None,cfg.TRAIN.epochs,cfg.TRAIN.iters_per_epoch,save_freq=cfg.TRAIN.save_freq,eval_during_train=cfg.TRAIN.eval_during_train,validator=validator_pde,eval_with_no_grad=cfg.EVAL.eval_with_no_grad,)# train modelsolver.train()functions.plotting(cfg.output_dir)defevaluate(cfg:DictConfig):# set random seed for reproducibilityppsci.utils.misc.set_random_seed(cfg.seed)# initialize loggerlogger.init_logger("ppsci",osp.join(cfg.output_dir,f"{cfg.mode}.log"),"info")(input_dict_train,_,input_dict_val,label_dict_val,)=functions.get_data(cfg.DATASET_STATE,cfg.DATASET_STRESS,cfg.NTRAIN_SIZE)model_list=functions.get_model_list(cfg.MODEL.ihlayers,cfg.MODEL.ineurons,input_dict_train["state_x"][0].shape[1],input_dict_train["state_y"][0].shape[1],input_dict_train["stress_x"][0].shape[1],)model_state_elasto,model_state_plastic,model_stress=model_listmodel_list_obj=ppsci.arch.ModelList(model_list)def_transform_in_stress(_in):returnfunctions.transform_in_stress(_in,model_state_elasto,"out_state_elasto")model_state_elasto.register_input_transform(functions.transform_in)model_state_plastic.register_input_transform(functions.transform_in)model_stress.register_input_transform(_transform_in_stress)model_stress.register_output_transform(functions.transform_out)output_keys=["state_x","state_y","stress_x","stress_y","out_state_elasto","out_state_plastic","out_stress",]sup_validator_pde=ppsci.validate.SupervisedValidator({"dataset":{"name":"NamedArrayDataset","input":input_dict_val,"label":label_dict_val,},"batch_size":1,"num_workers":0,},ppsci.loss.FunctionalLoss(functions.eval_loss_func),{key:(lambdaout,k=key:out[k])forkeyinoutput_keys},metric={"metric":ppsci.metric.FunctionalMetric(functions.metric_expr)},name="sup_valid",)validator_pde={sup_validator_pde.name:sup_validator_pde}functions.OUTPUT_DIR=cfg.output_dir# initialize solversolver=ppsci.solver.Solver(model_list_obj,output_dir=cfg.output_dir,validator=validator_pde,pretrained_model_path=cfg.EVAL.pretrained_model_path,eval_with_no_grad=cfg.EVAL.eval_with_no_grad,)# evaluatesolver.eval()@hydra.main(version_base=None,config_path="./conf",config_name="epnn.yaml")defmain(cfg:DictConfig):ifcfg.mode=="train":train(cfg)elifcfg.mode=="eval":evaluate(cfg)else:raiseValueError(f"cfg.mode should in ['train', 'eval'], but got '{cfg.mode}'")if__name__=="__main__":main()