# Wind speed pretrain model evaluationpythontrain_pretrain.pymode=evalEVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/fourcastnet/pretrain.pdparams
# Wind speed finetune model evaluationpythontrain_finetune.pymode=evalEVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/fourcastnet/finetune.pdparams
# Precipitation model evaluationpythontrain_precip.pymode=evalEVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/fourcastnet/precip.pdparamsWIND_MODEL_PATH=https://paddle-org.bj.bcebos.com/paddlescience/models/fourcastnet/finetune.pdparams
# Wind speed pretrain model exportpythontrain_pretrain.pymode=export# Wind speed finetune model exportpythontrain_finetune.pymode=export# Precipitation model exportpythontrain_precip.pymode=export
# Download wind speed prediction small sample datawget-chttps://paddle-org.bj.bcebos.com/paddlescience/datasets/FourcastNet/global_stds.npy-P./datasets/era5/stat/
wget-chttps://paddle-org.bj.bcebos.com/paddlescience/datasets/FourcastNet/global_means.npy-P./datasets/era5/stat/
wget-chttps://paddle-org.bj.bcebos.com/paddlescience/datasets/FourcastNet/2018-04-04_n6_precip.npy-P./datasets/era5/test/
wget-chttps://paddle-org.bj.bcebos.com/paddlescience/datasets/FourcastNet/2018-04-04_n6.npy-P./datasets/era5/test/
# Download precipitation prediction small sample datawget-chttps://paddle-org.bj.bcebos.com/paddlescience/datasets/FourcastNet/2018-09-08_n32.npy-P./datasets/era5/test/
# Wind speed pretrain model inferencepythontrain_pretrain.pymode=infer
# Wind speed finetune model inferencepythontrain_finetune.pymode=infer
# Precipitation model inferencepythontrain_precip.pymode=infer
Weather forecasting typically employs two approaches: physics-based and data-driven methods. Physics-based methods, such as the Integrated Forecasting System (IFS), rely on governing equations to model atmospheric variable relationships, often utilizing over 150 variables across 50+ vertical levels. In contrast, data-driven methods leverage large datasets to train neural networks, learning mappings from input to output without explicit physical equations.
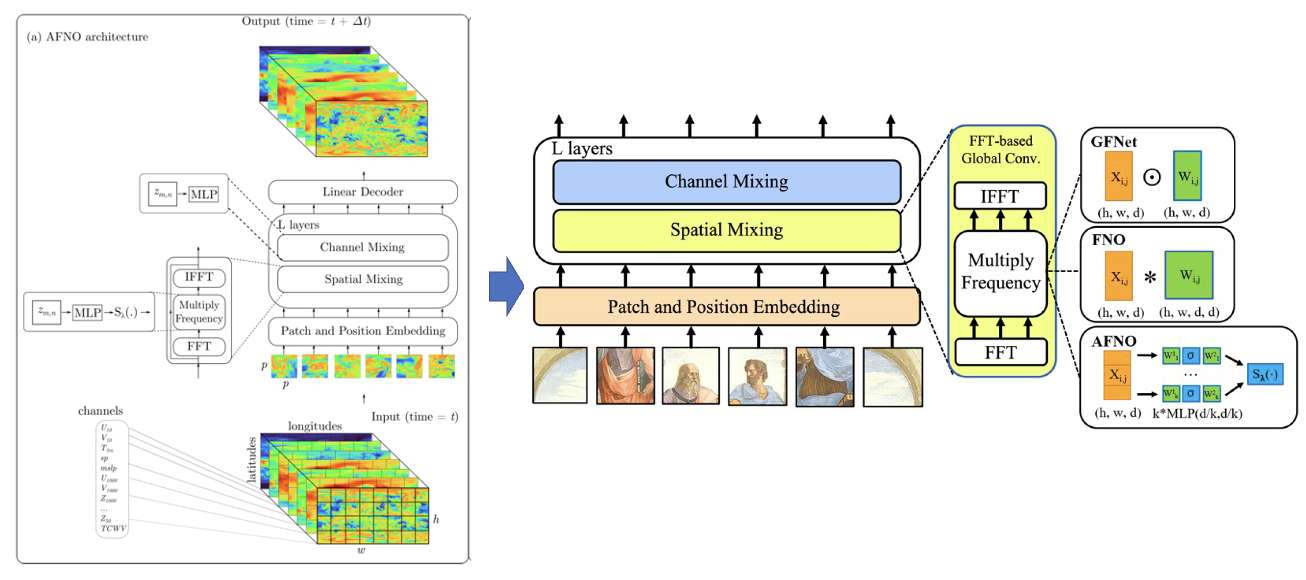
FourCastNet is a data-driven weather forecasting algorithm utilizing Adaptive Fourier Neural Operators (AFNO). It focuses on predicting 10-meter wind speed and 6-hour total precipitation, enabling early warnings for extreme weather. Compared to IFS, FourCastNet uses only 20 atmospheric variables at 5 vertical heights, offering significantly faster inference speeds with reduced input complexity.
FourCastNet employs the AFNO network, adapting an architecture previously used in image segmentation. AFNO addresses the limitations of Vision Transformers (ViT) by integrating Fourier Neural Operators (FNO). It utilizes Fourier transforms for token interaction, significantly reducing the computational cost of self-attention in high-resolution settings. For further details, refer to the AFNO, FNO, and ViT papers.
The overall structure of the model is shown in the figure:
FourCastNet Network Model
The FourCastNet paper trained a wind speed model and a precipitation model. Next, the training and inference processes of these two models will be introduced.
2.1 Training and Inference Process of Wind Speed Model¶
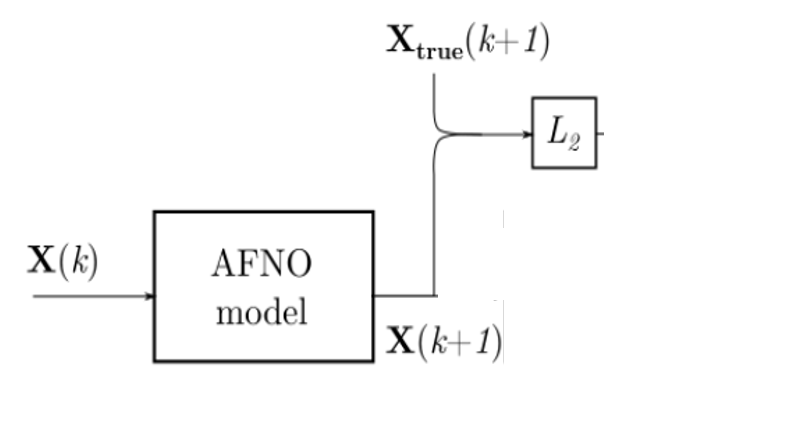
Model training involves two stages: pre-training and fine-tuning.
In the pre-training stage, the model is initialized with random weights. As shown below, \(X(k)\) represents atmospheric data at time \(k\), \(X(k+1)\) is the model's prediction for time \(k+1\), and \(X_{true}(k+1)\) is the ground truth. The model minimizes the L2 loss between the predicted output and the ground truth.
Wind speed model pre-training
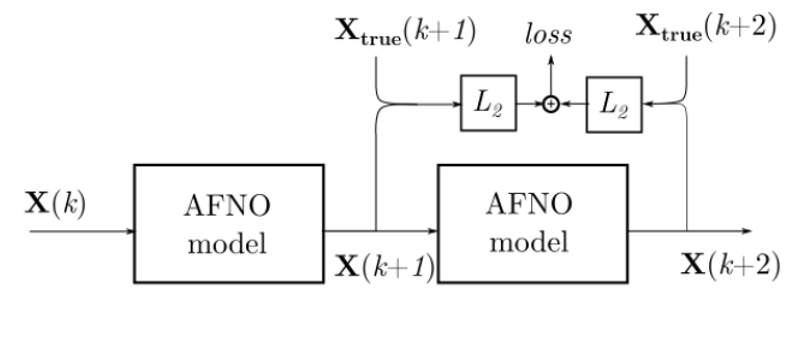
The second stage, fine-tuning, aims to enhance accuracy for medium- to long-range forecasting. Here, the model performs autoregressive prediction: the output for time \(k+1\) (generated from input at time \(k\)) is fed back as input to predict time \(k+2\). This multi-step prediction process improves the model's long-term stability and performance.
Wind speed model fine-tuning
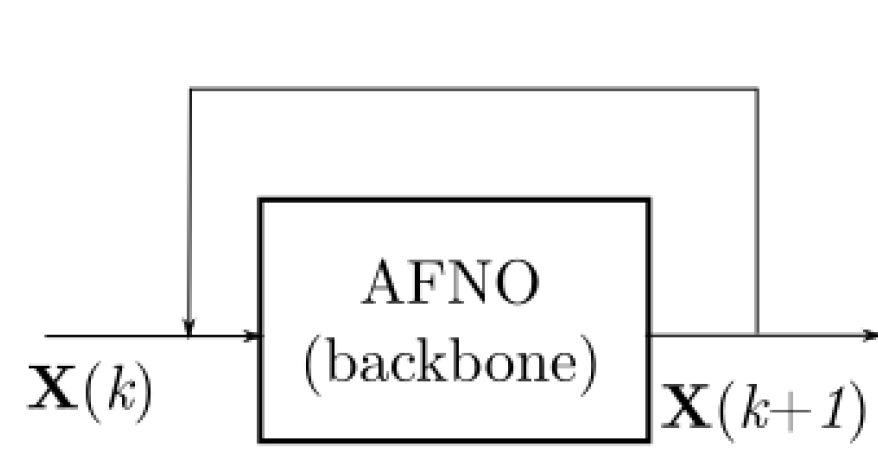
In the inference stage, given data at time \(k\), prediction results at times \(k+1\), \(k+2\), \(k+3\), etc. can be obtained through continuous iteration.
Wind speed model inference
2.2 Training and Inference Process of Precipitation Model¶
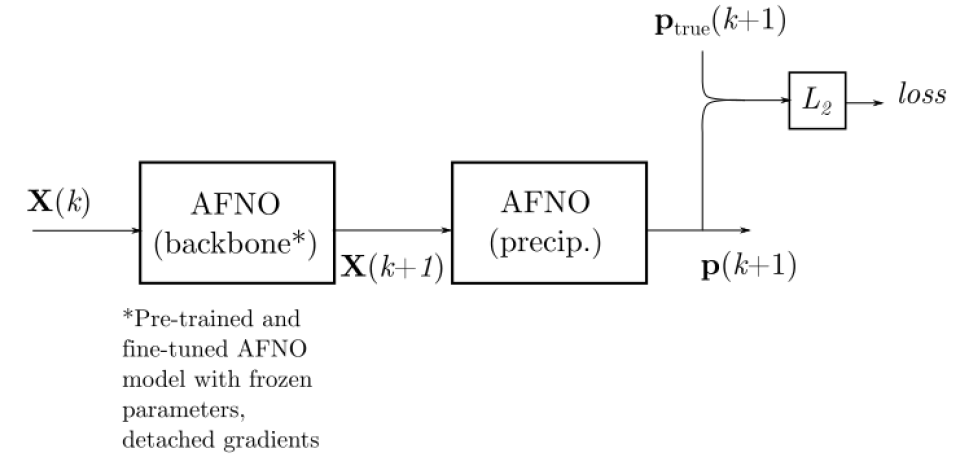
The precipitation model training relies on the pre-trained wind speed model. As illustrated below, the wind speed model takes atmospheric data \(X(k)\) to predict \(X(k+1)\). This predicted state \(X(k+1)\) then serves as input to the precipitation model, which outputs the precipitation forecast \(p(k+1)\). The model is trained by minimizing the L2 loss between the predicted precipitation \(p(k+1)\) and the ground truth \(p_{true}(k+1)\).
Precipitation model training
It should be noted that during the training process of the precipitation model, the parameters of the wind speed model are in a frozen state and do not participate in the optimizer parameter update process.
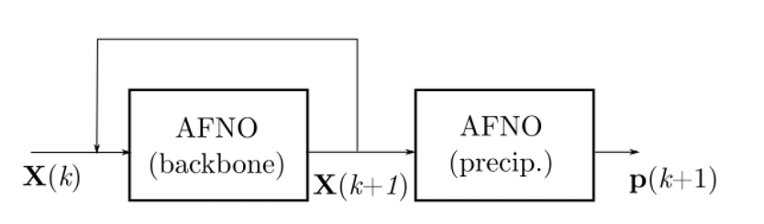
In the inference stage, given data at time \(k\), atmospheric variable prediction results at times \(k+1\), \(k+2\), \(k+3\), etc. can be obtained through continuous iteration using the wind speed model, and used as input to the precipitation model to predict precipitation at corresponding times.
Next, we will explain how to implement the training and inference of the FourCastNet wind speed model based on PaddleScience code. For other details in this case, please refer to API Documentation.
Info
Since complete reproduction requires 5+TB of storage space and 64-card training resources, if it is only for learning the algorithm principle of FourCastNet, it is recommended to train on a small part of the training dataset to reduce learning costs.
We use the ERA5 dataset processed by FourCastNet. The dataset has a resolution of 0.25 degrees (\(720 \times 1440\) grid), with each point representing approximately 30 km. Covering the period 1979-2018, the data is split into training, validation, and test sets by year:
The model training uses 20 atmospheric variables distributed on 5 pressure layers, as shown in the table below,
20 atmospheric variables
Among them, \(T\), \(U\), \(V\), \(Z\), \(RH\) represent temperature, zonal wind speed, meridional wind speed, geopotential and relative humidity at specified vertical heights respectively; \(U_{10}\), \(V_{10}\), \(T_{2m}\) represent zonal wind speed at 10 meters from the ground, meridional wind speed and temperature at 2 meters from the ground. \(sp\) represents surface pressure, and \(mslp\) represents mean sea level pressure. \(TCWV\) represents total column water vapor.
Data is sampled at 6-hour intervals (00:00, 06:00, 12:00, 18:00). Training and inference involve predicting the state at the next 6-hour interval; for example, taking 20 atmospheric variables at 00:00 as input to predict the variables at 06:00.
# set training hyper-parametersIMG_H:720IMG_W:1440# FourCastNet use 20 atmospheric variable,their index in the dataset is from 0 to 19.# The variable name is 'u10', 'v10', 't2m', 'sp', 'msl', 't850', 'u1000', 'v1000', 'z000',# 'u850', 'v850', 'z850', 'u500', 'v500', 'z500', 't500', 'z50', 'r500', 'r850', 'tcwv'.# You can obtain detailed information about each variable from# https://cds.climate.copernicus.eu/cdsapp#!/search?text=era5&type=datasetVARS_CHANNEL:[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19]USE_SAMPLED_DATA:false# set train data pathTRAIN_FILE_PATH:./datasets/era5/trainDATA_MEAN_PATH:./datasets/era5/stat/global_means.npyDATA_STD_PATH:./datasets/era5/stat/global_stds.npyDATA_TIME_MEAN_PATH:./datasets/era5/stat/time_means.npy# set evaluate data path
Since this is a data-driven task, we use PaddleScience's SupervisedConstraint. Before defining the constraint, we configure data loading and preprocessing parameters. The preprocessing steps are implemented as follows:
data_mean,data_std=fourcast_utils.get_mean_std(cfg.DATA_MEAN_PATH,cfg.DATA_STD_PATH,cfg.VARS_CHANNEL)data_time_mean=fourcast_utils.get_time_mean(cfg.DATA_TIME_MEAN_PATH,cfg.IMG_H,cfg.IMG_W,cfg.VARS_CHANNEL)data_time_mean_normalize=np.expand_dims((data_time_mean[0]-data_mean)/data_std,0)# set train transformstransforms=[{"SqueezeData":{}},{"CropData":{"xmin":(0,0),"xmax":(cfg.IMG_H,cfg.IMG_W)}},{"Normalize":{"mean":data_mean,"std":data_std}},
The data preprocessing part contains a total of 3 preprocessing methods, namely:
SqueezeData: Compress the dimensions of training data. If the dimension of input data is 4, compress data of 0th dimension and 1st dimension together, and finally transform the dimension of input data to 3.
CropData: Crop data at specified position from training data. Because the original data size in ERA5 dataset is \(721 \times 1440\), this case crops the training data to \(720 \times 1440\) according to the original paper setting.
Normalize: Normalize data according to mean and variance on the training dataset.
Full reproduction of FourCastNet requires over 5TB of storage and 64 GPUs. To accommodate different resource availabilities, we offer two training methods (both yield similar convergence):
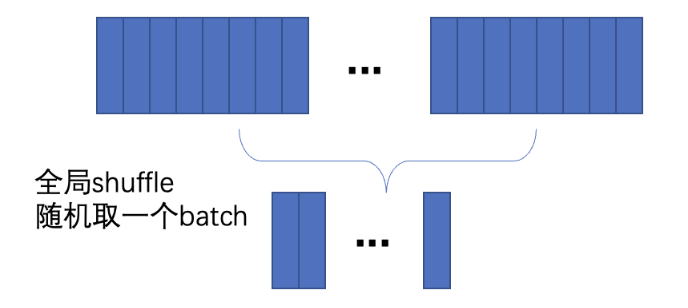
Method A (Sufficient Storage): Each node stores the full 5TB+ dataset. Data is randomly selected from the complete set using global shuffle, as shown below.
Global shuffle
In this method, the code for data loading is as follows:
Among them, the "dataset" field defines the used Dataset class name as ERA5Dataset, the "sampler" field defines the used Sampler class name as BatchSampler, setting batch_size to 1 and num_works to 8.
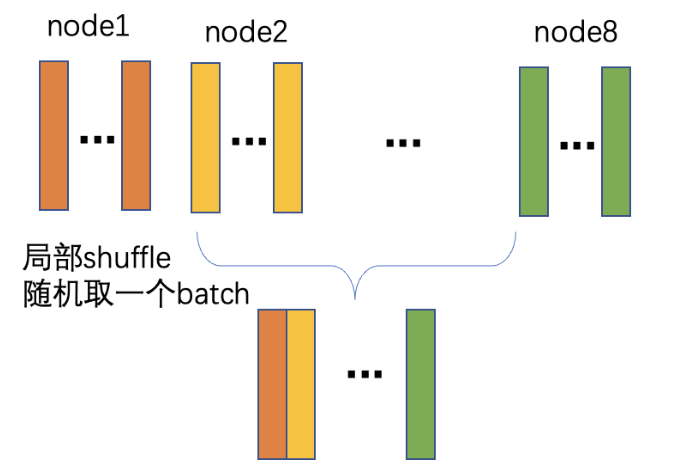
Method B (Limited Storage): The dataset is evenly partitioned across nodes. You can use ppsci/fourcastnet/sample_data.py to sample data. To use this method, set USE_SAMPLED_DATA to True (Method A is the default). Training uses local shuffle, where each node samples from its local partition. For example, splitting across 8 nodes reduces the per-node storage requirement to approximately 1.2TB.
Local shuffle
In this method, the code for data loading is as follows:
Among them, the "dataset" field defines the used Dataset class name as ERA5SampledDataset, the "sampler" field defines the used Sampler class name as DistributedBatchSampler, setting batch_size to 1 and num_works to 8.
When complete reproduction of FourCastNet is not required, simply use the default setting of this case (method a).
The code for defining supervised constraints is as follows:
The learning rate method used in this case is Cosine, and the learning rate size is set to 5e-4. The optimizer uses Adam, expressed in PaddleScience code as follows:
# init optimizer and lr schedulerlr_scheduler_cfg=dict(cfg.TRAIN.lr_scheduler)lr_scheduler_cfg.update({"iters_per_epoch":ITERS_PER_EPOCH})lr_scheduler=ppsci.optimizer.lr_scheduler.Cosine(**lr_scheduler_cfg)()
In this case, the validation set is used to evaluate the training status of the current model at certain training epoch intervals during the training process, and SupervisedValidator is needed to construct the validator. The code is as follows:
# set eval dataloader configeval_dataloader_cfg={"dataset":{"name":"ERA5Dataset","file_path":cfg.VALID_FILE_PATH,"input_keys":cfg.MODEL.afno.input_keys,"label_keys":cfg.MODEL.afno.output_keys,"vars_channel":cfg.VARS_CHANNEL,"transforms":transforms,"training":False,},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,}# set validatorsup_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,ppsci.loss.L2RelLoss(),metric={"MAE":ppsci.metric.MAE(keep_batch=True),"LatitudeWeightedRMSE":ppsci.metric.LatitudeWeightedRMSE(num_lat=cfg.IMG_H,std=data_std,keep_batch=True,variable_dict={"u10":0,"v10":1},),"LatitudeWeightedACC":ppsci.metric.LatitudeWeightedACC(num_lat=cfg.IMG_H,mean=data_time_mean_normalize,keep_batch=True,variable_dict={"u10":0,"v10":1},),},name="Sup_Validator",)
The SupervisedValidator validator is similar to SupervisedConstraint, the difference is that the validator needs to set the evaluation metric metric, here 3 evaluation metrics are used, namely MAE, LatitudeWeightedRMSE and LatitudeWeightedACC.
After completing the above settings, you only need to pass the instantiated objects to ppsci.solver.Solver in order, and then start training and evaluation.
# initialize solversolver=ppsci.solver.Solver(model,constraint,cfg.output_dir,optimizer,lr_scheduler,cfg.TRAIN.epochs,ITERS_PER_EPOCH,eval_during_train=True,seed=cfg.seed,validator=validator,compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,eval_with_no_grad=cfg.EVAL.eval_with_no_grad,)# train modelsolver.train()# evaluate after finished training
Having covered pre-training, we now discuss fine-tuning the wind speed model. Since the process is similar, we focus only on the differences. Key parameters for fine-tuning are defined below:
# set training hyper-parametersIMG_H:720IMG_W:1440# FourCastNet use 20 atmospheric variable,their index in the dataset is from 0 to 19.# The variable name is 'u10', 'v10', 't2m', 'sp', 'msl', 't850', 'u1000', 'v1000', 'z000',# 'u850', 'v850', 'z850', 'u500', 'v500', 'z500', 't500', 'z50', 'r500', 'r850', 'tcwv'.# You can obtain detailed information about each variable from# https://cds.climate.copernicus.eu/cdsapp#!/search?text=era5&type=datasetVARS_CHANNEL:[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19]# set train data pathTRAIN_FILE_PATH:./datasets/era5/trainDATA_MEAN_PATH:./datasets/era5/stat/global_means.npyDATA_STD_PATH:./datasets/era5/stat/global_stds.npyDATA_TIME_MEAN_PATH:./datasets/era5/stat/time_means.npy# set evaluate data pathVALID_FILE_PATH:./datasets/era5/test# set test data path
The fine-tuning model program adds a num_timestamps parameter to control the number of time steps iterated during model fine-tuning training. This parameter will first be used in the data loading setting to set the time step size of the ground truth generated by the dataset. The code is as follows:
]# set train dataloader configtrain_dataloader_cfg={"dataset":{"name":"ERA5Dataset","file_path":cfg.TRAIN_FILE_PATH,"input_keys":cfg.MODEL.afno.input_keys,"label_keys":output_keys,"vars_channel":cfg.VARS_CHANNEL,"num_label_timestamps":cfg.TRAIN.num_timestamps,"transforms":transforms,},"sampler":{"name":"BatchSampler","drop_last":True,"shuffle":True,},"batch_size":cfg.TRAIN.batch_size,"num_workers":8,
The num_timestamps parameter is set through the configuration file as follows:
In addition, unlike pre-training, fine-tuning model construction also requires setting the num_timestamps parameter to control the time step size of the prediction results output by the model. The code is as follows:
# set modelmodel_cfg=dict(cfg.MODEL.afno)model_cfg.update({"output_keys":output_keys,"num_timestamps":cfg.TRAIN.num_timestamps}
The code for evaluating model performance on the test set and visualization code have been added to the program for training fine-tuning models. Next, these two parts will be introduced in detail.
According to the settings in the paper, when evaluating the model on the test set, num_timestamps is set to 32 through the configuration file, and the interval between two adjacent test samples is 8.
# set eval dataloader configeval_dataloader_cfg={"dataset":{"name":"ERA5Dataset","file_path":cfg.TEST_FILE_PATH,"input_keys":cfg.MODEL.afno.input_keys,"label_keys":output_keys,"vars_channel":cfg.VARS_CHANNEL,"transforms":transforms,"num_label_timestamps":cfg.EVAL.num_timestamps,"training":False,"stride":8,},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,}# set metircmetric={"MAE":ppsci.metric.MAE(keep_batch=True),"LatitudeWeightedRMSE":ppsci.metric.LatitudeWeightedRMSE(num_lat=cfg.IMG_H,std=data_std,keep_batch=True,variable_dict={"u10":0,"v10":1},),"LatitudeWeightedACC":ppsci.metric.LatitudeWeightedACC(num_lat=cfg.IMG_H,mean=data_time_mean_normalize,keep_batch=True,variable_dict={"u10":0,"v10":1},),}# set validator for testingsup_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,ppsci.loss.L2RelLoss(),metric=metric,name="Sup_Validator",)
# set visualizer dataDATE_STRINGS=("2018-09-08 00:00:00",)vis_data=get_vis_data(cfg.TEST_FILE_PATH,DATE_STRINGS,cfg.EVAL.num_timestamps,cfg.VARS_CHANNEL,cfg.IMG_H,data_mean,data_std,
In the above code, the corresponding data is read for model input based on the set time parameter DATE_STRINGS. In addition, the get_vis_datas function also reads the ground truth data at the corresponding time. These data will also be visualized for comparison with the model prediction results.
Since the model predicts zonal and meridional wind speeds separately, it is necessary to synthesize wind speeds in these two directions into real wind speed. The code is as follows:
vis_output_expr[f"target_{hour}h"]=lambdad,hour=hour:d[f"target_{hour}h"]# set visualizervisualizer={"visualize_wind":ppsci.visualize.VisualizerWeather(vis_data,vis_output_expr,xticks=np.linspace(0,1439,13),xticklabels=[str(i)foriinrange(360,-1,-30)],yticks=np.linspace(0,719,7),yticklabels=[str(i)foriinrange(90,-91,-30)],vmin=0,vmax=25,colorbar_label="m\s",batch_size=cfg.EVAL.batch_size,num_timestamps=cfg.EVAL.num_timestamps,prefix="wind",)
The constructed model, validator, and visualizer above will be passed to ppsci.solver.Solver for evaluating performance on the test set and visualization.
solver=ppsci.solver.Solver(model,output_dir=cfg.output_dir,validator=validator,visualizer=visualizer,pretrained_model_path=cfg.EVAL.pretrained_model_path,compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,eval_with_no_grad=cfg.EVAL.eval_with_no_grad,)solver.eval()# visualize prediction from pretrained_model_path
# set training hyper-parametersIMG_H:720IMG_W:1440# FourCastNet use 20 atmospheric variable,their index in the dataset is from 0 to 19.# The variable name is 'u10', 'v10', 't2m', 'sp', 'msl', 't850', 'u1000', 'v1000', 'z000',# 'u850', 'v850', 'z850', 'u500', 'v500', 'z500', 't500', 'z50', 'r500', 'r850', 'tcwv'.# You can obtain detailed information about each variable from# https://cds.climate.copernicus.eu/cdsapp#!/search?text=era5&type=datasetVARS_CHANNEL:[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19]# set train data pathWIND_TRAIN_FILE_PATH:./datasets/era5/trainWIND_MEAN_PATH:./datasets/era5/stat/global_means.npyWIND_STD_PATH:./datasets/era5/stat/global_stds.npyWIND_TIME_MEAN_PATH:./datasets/era5/stat/time_means.npyTRAIN_FILE_PATH:./datasets/era5/precip/trainTIME_MEAN_PATH:./datasets/era5/stat/precip/time_means.npy# set evaluate data pathWIND_VALID_FILE_PATH:./datasets/era5/testVALID_FILE_PATH:./datasets/era5/precip/test# set test data pathWIND_TEST_FILE_PATH:./datasets/era5/out_of_sample/2018.h5TEST_FILE_PATH:./datasets/era5/precip/out_of_sample/2018.h5# set wind model path
This case solves the problem based on data-driven methods, so it is necessary to use SupervisedConstraint built in PaddleScience to construct supervised constraints. Before defining constraints, you need to first specify various parameters used for data loading in supervised constraints. First introduce the data preprocessing part, the code is as follows:
wind_data_mean,wind_data_std=fourcast_utils.get_mean_std(cfg.WIND_MEAN_PATH,cfg.WIND_STD_PATH,cfg.VARS_CHANNEL)data_time_mean=fourcast_utils.get_time_mean(cfg.TIME_MEAN_PATH,cfg.IMG_H,cfg.IMG_W)# set train transformstransforms=[{"SqueezeData":{}},{"CropData":{"xmin":(0,0),"xmax":(cfg.IMG_H,cfg.IMG_W)}},{"Normalize":{"mean":wind_data_mean,"std":wind_data_std,"apply_keys":("input",),}},{"Log1p":{"scale":1e-5,"apply_keys":("label",)}},
The data preprocessing part contains a total of 4 preprocessing methods, namely:
SqueezeData: Compress the dimensions of training data. If the dimension of input data is 4, compress data of 0th dimension and 1st dimension together, and finally transform the dimension of input data to 3.
CropData: Crop data at specified position from training data. Because the original data size in ERA5 dataset is \(721 \times 1440\), this case crops the training data size to \(720 \times 1440\) according to the original paper setting.
Normalize: Normalize data according to mean and variance on the training dataset. Here, the apply_keys field sets this preprocessing method to be applied only to input data.
Log1p: Map data to logarithmic space. Here, the apply_keys field sets this preprocessing method to be applied only to ground truth data.
# set train dataloader configtrain_dataloader_cfg={"dataset":{"name":"ERA5Dataset","file_path":cfg.WIND_TRAIN_FILE_PATH,"input_keys":cfg.MODEL.precip.input_keys,"label_keys":cfg.MODEL.precip.output_keys,"vars_channel":cfg.VARS_CHANNEL,"precip_file_path":cfg.TRAIN_FILE_PATH,"transforms":transforms,},"sampler":{"name":"BatchSampler","drop_last":True,"shuffle":True,},"batch_size":cfg.TRAIN.batch_size,"num_workers":8,
Among them, the "dataset" field defines the used Dataset class name as ERA5Dataset, the "sampler" field defines the used Sampler class name as BatchSampler, setting batch_size to 1 and num_works to 8.
The code for defining supervised constraints is as follows:
# set modelwind_model=ppsci.arch.AFNONet(**cfg.MODEL.afno)ppsci.utils.save_load.load_pretrain(wind_model,path=cfg.WIND_MODEL_PATH)model_cfg=dict(cfg.MODEL.precip)model_cfg.update({"wind_model":wind_model})
The parameters for defining the model are set through configuration as follows:
# set inference data pathWIND_INFER_PATH:./datasets/era5/test/2018-04-04_n6.npyINFER_FILE_PATH:./datasets/era5/test/2018-04-04_n6_precip.npy# model settingsMODEL:afno:
Among them, input_keys and output_keys represent the names of input and output variables of the network model respectively.
The learning rate method used in this case is Cosine, and the learning rate size is set to 2.5e-4. The optimizer uses Adam, expressed in PaddleScience code as follows:
# init optimizer and lr schedulerlr_scheduler_cfg=dict(cfg.TRAIN.lr_scheduler)lr_scheduler_cfg.update({"iters_per_epoch":ITERS_PER_EPOCH})lr_scheduler=ppsci.optimizer.lr_scheduler.Cosine(**lr_scheduler_cfg)()
In this case, the validation set is used to evaluate the training status of the current model at certain training epoch intervals during the training process, and SupervisedValidator is needed to construct the validator. The code is as follows:
# set eval dataloader configeval_dataloader_cfg={"dataset":{"name":"ERA5Dataset","file_path":cfg.WIND_VALID_FILE_PATH,"input_keys":cfg.MODEL.precip.input_keys,"label_keys":cfg.MODEL.precip.output_keys,"vars_channel":cfg.VARS_CHANNEL,"precip_file_path":cfg.VALID_FILE_PATH,"transforms":transforms,"training":False,},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,}# set metricmetric={"MAE":ppsci.metric.MAE(keep_batch=True),"LatitudeWeightedRMSE":ppsci.metric.LatitudeWeightedRMSE(num_lat=cfg.IMG_H,keep_batch=True,unlog=True),"LatitudeWeightedACC":ppsci.metric.LatitudeWeightedACC(num_lat=cfg.IMG_H,mean=data_time_mean,keep_batch=True,unlog=True),}# set validatorsup_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,ppsci.loss.L2RelLoss(),metric=metric,name="Sup_Validator",)
The SupervisedValidator validator is similar to SupervisedConstraint, the difference is that the validator needs to set the evaluation metric metric, here 3 evaluation metrics are used, namely MAE, LatitudeWeightedRMSE and LatitudeWeightedACC.
After completing the above settings, you only need to pass the instantiated objects to ppsci.solver.Solver in order, and then start training and evaluation.
# initialize solversolver=ppsci.solver.Solver(model,constraint,cfg.output_dir,optimizer,lr_scheduler,cfg.TRAIN.epochs,ITERS_PER_EPOCH,eval_during_train=True,validator=validator,compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,eval_with_no_grad=cfg.EVAL.eval_with_no_grad,)# train modelsolver.train()# evaluate after finished training
According to the settings in the paper, when evaluating the model on the test set, num_timestamps is set to 6, and the interval between two adjacent test samples is 8.
# set model for testingwind_model=ppsci.arch.AFNONet(**cfg.MODEL.afno)ppsci.utils.save_load.load_pretrain(wind_model,path=cfg.WIND_MODEL_PATH)model_cfg=dict(cfg.MODEL.precip)model_cfg.update({"output_keys":output_keys,"num_timestamps":cfg.EVAL.num_timestamps,"wind_model":wind_model,})
eval_dataloader_cfg={"dataset":{"name":"ERA5Dataset","file_path":cfg.WIND_TEST_FILE_PATH,"input_keys":cfg.MODEL.precip.input_keys,"label_keys":output_keys,"vars_channel":cfg.VARS_CHANNEL,"precip_file_path":cfg.TEST_FILE_PATH,"num_label_timestamps":cfg.EVAL.num_timestamps,"stride":8,"transforms":transforms,"training":False,},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,}# set metircmetric={"MAE":ppsci.metric.MAE(keep_batch=True),"LatitudeWeightedRMSE":ppsci.metric.LatitudeWeightedRMSE(num_lat=cfg.IMG_H,keep_batch=True,unlog=True),"LatitudeWeightedACC":ppsci.metric.LatitudeWeightedACC(num_lat=cfg.IMG_H,mean=data_time_mean,keep_batch=True,unlog=True),}# set validator for testingsup_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,ppsci.loss.L2RelLoss(),metric=metric,name="Sup_Validator",)
The precipitation model uses autoregressive method for inference, and the input data for model inference needs to be set first. The code is as follows:
# set set visualizer dataDATE_STRINGS=("2018-04-04 00:00:00",)vis_data=get_vis_data(cfg.WIND_TEST_FILE_PATH,cfg.TEST_FILE_PATH,DATE_STRINGS,cfg.EVAL.num_timestamps,cfg.VARS_CHANNEL,cfg.IMG_H,wind_data_mean,wind_data_std,
In the above code, the corresponding data is read for model input based on the set time parameter DATE_STRINGS. In addition, the get_vis_datas function also reads the ground truth data at the corresponding time. These data will also be visualized for comparison with the model prediction results.
Since the model performs logarithmic processing on precipitation, it is necessary to remap the model results back to linear space. The code is as follows:
)# set visualizervisualizer={"visualize_precip":ppsci.visualize.VisualizerWeather(vis_data,visu_output_expr,xticks=np.linspace(0,1439,13),xticklabels=[str(i)foriinrange(360,-1,-30)],yticks=np.linspace(0,719,7),yticklabels=[str(i)foriinrange(90,-91,-30)],vmin=0.001,vmax=130,colorbar_label="mm",log_norm=True,batch_size=cfg.EVAL.batch_size,num_timestamps=cfg.EVAL.num_timestamps,prefix="precip",)
The constructed model, validator, and visualizer above will be passed to ppsci.solver.Solver for evaluating performance on the test set and visualization.
# Copyright (c) 2023 PaddlePaddle Authors. All Rights Reserved.## Licensed under the Apache License, Version 2.0 (the "License");# you may not use this file except in compliance with the License.# You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.importosfromosimportpathasospimporthydraimportnumpyasnpimportpaddle.distributedasdistimportutilsasfourcast_utilsfromomegaconfimportDictConfigimportppscifromppsci.utilsimportloggerdefget_data_stat(cfg:DictConfig):data_mean,data_std=fourcast_utils.get_mean_std(cfg.DATA_MEAN_PATH,cfg.DATA_STD_PATH,cfg.VARS_CHANNEL)data_time_mean=fourcast_utils.get_time_mean(cfg.DATA_TIME_MEAN_PATH,cfg.IMG_H,cfg.IMG_W,cfg.VARS_CHANNEL)data_time_mean_normalize=np.expand_dims((data_time_mean[0]-data_mean)/data_std,0)returndata_mean,data_std,data_time_mean_normalizedeftrain(cfg:DictConfig):# set random seed for reproducibilityppsci.utils.misc.set_random_seed(cfg.seed)# initialize loggerlogger.init_logger("ppsci",osp.join(cfg.output_dir,"train.log"),"info")data_mean,data_std=fourcast_utils.get_mean_std(cfg.DATA_MEAN_PATH,cfg.DATA_STD_PATH,cfg.VARS_CHANNEL)data_time_mean=fourcast_utils.get_time_mean(cfg.DATA_TIME_MEAN_PATH,cfg.IMG_H,cfg.IMG_W,cfg.VARS_CHANNEL)data_time_mean_normalize=np.expand_dims((data_time_mean[0]-data_mean)/data_std,0)# set train transformstransforms=[{"SqueezeData":{}},{"CropData":{"xmin":(0,0),"xmax":(cfg.IMG_H,cfg.IMG_W)}},{"Normalize":{"mean":data_mean,"std":data_std}},]# set train dataloader configifnotcfg.USE_SAMPLED_DATA:train_dataloader_cfg={"dataset":{"name":"ERA5Dataset","file_path":cfg.TRAIN_FILE_PATH,"input_keys":cfg.MODEL.afno.input_keys,"label_keys":cfg.MODEL.afno.output_keys,"vars_channel":cfg.VARS_CHANNEL,"transforms":transforms,},"sampler":{"name":"BatchSampler","drop_last":True,"shuffle":True,},"batch_size":cfg.TRAIN.batch_size,"num_workers":8,}else:NUM_GPUS_PER_NODE=8train_dataloader_cfg={"dataset":{"name":"ERA5SampledDataset","file_path":cfg.TRAIN_FILE_PATH,"input_keys":cfg.MODEL.afno.input_keys,"label_keys":cfg.MODEL.afno.output_keys,},"sampler":{"name":"DistributedBatchSampler","drop_last":True,"shuffle":True,"num_replicas":NUM_GPUS_PER_NODE,"rank":dist.get_rank()%NUM_GPUS_PER_NODE,},"batch_size":cfg.TRAIN.batch_size,"num_workers":8,}# set constraintsup_constraint=ppsci.constraint.SupervisedConstraint(train_dataloader_cfg,ppsci.loss.L2RelLoss(),name="Sup",)constraint={sup_constraint.name:sup_constraint}# set iters_per_epoch by dataloader lengthITERS_PER_EPOCH=len(sup_constraint.data_loader)# set eval dataloader configeval_dataloader_cfg={"dataset":{"name":"ERA5Dataset","file_path":cfg.VALID_FILE_PATH,"input_keys":cfg.MODEL.afno.input_keys,"label_keys":cfg.MODEL.afno.output_keys,"vars_channel":cfg.VARS_CHANNEL,"transforms":transforms,"training":False,},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,}# set validatorsup_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,ppsci.loss.L2RelLoss(),metric={"MAE":ppsci.metric.MAE(keep_batch=True),"LatitudeWeightedRMSE":ppsci.metric.LatitudeWeightedRMSE(num_lat=cfg.IMG_H,std=data_std,keep_batch=True,variable_dict={"u10":0,"v10":1},),"LatitudeWeightedACC":ppsci.metric.LatitudeWeightedACC(num_lat=cfg.IMG_H,mean=data_time_mean_normalize,keep_batch=True,variable_dict={"u10":0,"v10":1},),},name="Sup_Validator",)validator={sup_validator.name:sup_validator}# set modelmodel=ppsci.arch.AFNONet(**cfg.MODEL.afno)# init optimizer and lr schedulerlr_scheduler_cfg=dict(cfg.TRAIN.lr_scheduler)lr_scheduler_cfg.update({"iters_per_epoch":ITERS_PER_EPOCH})lr_scheduler=ppsci.optimizer.lr_scheduler.Cosine(**lr_scheduler_cfg)()optimizer=ppsci.optimizer.Adam(lr_scheduler)(model)# initialize solversolver=ppsci.solver.Solver(model,constraint,cfg.output_dir,optimizer,lr_scheduler,cfg.TRAIN.epochs,ITERS_PER_EPOCH,eval_during_train=True,seed=cfg.seed,validator=validator,compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,eval_with_no_grad=cfg.EVAL.eval_with_no_grad,)# train modelsolver.train()# evaluate after finished trainingsolver.eval()defevaluate(cfg:DictConfig):# set random seed for reproducibilityppsci.utils.misc.set_random_seed(cfg.seed)# initialize loggerlogger.init_logger("ppsci",osp.join(cfg.output_dir,"eval.log"),"info")data_mean,data_std=fourcast_utils.get_mean_std(cfg.DATA_MEAN_PATH,cfg.DATA_STD_PATH,cfg.VARS_CHANNEL)data_time_mean=fourcast_utils.get_time_mean(cfg.DATA_TIME_MEAN_PATH,cfg.IMG_H,cfg.IMG_W,cfg.VARS_CHANNEL)data_time_mean_normalize=np.expand_dims((data_time_mean[0]-data_mean)/data_std,0)# set train transformstransforms=[{"SqueezeData":{}},{"CropData":{"xmin":(0,0),"xmax":(cfg.IMG_H,cfg.IMG_W)}},{"Normalize":{"mean":data_mean,"std":data_std}},]# set eval dataloader configeval_dataloader_cfg={"dataset":{"name":"ERA5Dataset","file_path":cfg.VALID_FILE_PATH,"input_keys":cfg.MODEL.afno.input_keys,"label_keys":cfg.MODEL.afno.output_keys,"vars_channel":cfg.VARS_CHANNEL,"transforms":transforms,"training":False,},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,}# set validatorsup_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,ppsci.loss.L2RelLoss(),metric={"MAE":ppsci.metric.MAE(keep_batch=True),"LatitudeWeightedRMSE":ppsci.metric.LatitudeWeightedRMSE(num_lat=cfg.IMG_H,std=data_std,keep_batch=True,variable_dict={"u10":0,"v10":1},),"LatitudeWeightedACC":ppsci.metric.LatitudeWeightedACC(num_lat=cfg.IMG_H,mean=data_time_mean_normalize,keep_batch=True,variable_dict={"u10":0,"v10":1},),},name="Sup_Validator",)validator={sup_validator.name:sup_validator}# set modelmodel=ppsci.arch.AFNONet(**cfg.MODEL.afno)# initialize solversolver=ppsci.solver.Solver(model,output_dir=cfg.output_dir,log_freq=cfg.log_freq,seed=cfg.seed,validator=validator,pretrained_model_path=cfg.EVAL.pretrained_model_path,compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,eval_with_no_grad=cfg.EVAL.eval_with_no_grad,)# evaluatesolver.eval()defexport(cfg:DictConfig):# set modelmodel=ppsci.arch.AFNONet(**cfg.MODEL.afno)# initialize solversolver=ppsci.solver.Solver(model,pretrained_model_path=cfg.INFER.pretrained_model_path,)# export modelfrompaddle.staticimportInputSpecinput_spec=[{key:InputSpec([None,20,cfg.IMG_H,cfg.IMG_W],"float32",name=key)forkeyinmodel.input_keys},]solver.export(input_spec,cfg.INFER.export_path)definference(cfg:DictConfig):fromdeploy.python_inferimportpinn_predictorpredictor=pinn_predictor.PINNPredictor(cfg)data_mean,data_std=fourcast_utils.get_mean_std(cfg.DATA_MEAN_PATH,cfg.DATA_STD_PATH,cfg.VARS_CHANNEL)data=np.load(cfg.INFER_FILE_PATH)input_0=(data[:,0]-data_mean)/data_stdall_data=input_0fortinrange(cfg.INFER.num_timestamps):data_t=data[:,t+1]data_t=(data_t-data_mean)/data_stdall_data=np.concatenate((all_data,data_t),axis=0)input_dict={cfg.MODEL.afno.input_keys[0]:all_data}vis_output=predictor.predict(input_dict,cfg.INFER.batch_size)vis_dict={store_key:vis_output[infer_key]forstore_key,infer_keyinzip(cfg.MODEL.afno.output_keys,vis_output.keys())}defoutput_wind_func(output,data_mean,data_std):output=(output*data_std)+data_meanwind_data=(output[0]**2+output[1]**2)**0.5returnwind_datawind_pred=[]pred_dict={}foriinrange(cfg.INFER.num_timestamps):hour=(i+1)*6wind_=[output_wind_func(vis_dict[cfg.MODEL.afno.output_keys[0]][i],data_mean,data_std)]wind_pred.append(wind_)pred_dict[f"output_{hour}h"]=np.asarray(wind_)output_dict={cfg.MODEL.afno.output_keys[0]:np.array(wind_pred)}wind_pred=[]target_dict={}foriinrange(cfg.INFER.num_timestamps):hour=(i+1)*6wind_=[(data[0][i][0]**2+data[0][i][1]**2)**0.5]target_dict[f"target_{hour}h"]=np.asarray(wind_)vis_dict={**pred_dict,**target_dict}plot_expr_dict={}forhourinrange(6,6+cfg.INFER.num_timestamps*6,6):plot_expr_dict.update({f"target_{hour}h":lambdad,hour=hour:d[f"target_{hour}h"],f"output_{hour}h":lambdad,hour=hour:d[f"output_{hour}h"],})visualizer_weather=ppsci.visualize.VisualizerWeather(vis_dict,plot_expr_dict,xticks=np.linspace(0,cfg.IMG_W-1,13),xticklabels=[str(i)foriinrange(360,-1,-30)],yticks=np.linspace(0,cfg.IMG_H-1,7),yticklabels=[str(i)foriinrange(90,-91,-30)],vmin=0,vmax=25,colorbar_label="m\s",batch_size=1,num_timestamps=cfg.INFER.num_timestamps,prefix="wind",)visualizer_weather.save(cfg.INFER.export_path,vis_dict)save_path=osp.join(cfg.INFER.export_path,"predict.npy")os.makedirs(cfg.INFER.export_path,exist_ok=True)np.save(save_path,output_dict[cfg.MODEL.afno.output_keys[0]])@hydra.main(version_base=None,config_path="./conf",config_name="fourcastnet_pretrain.yaml")defmain(cfg:DictConfig):ifcfg.mode=="train":train(cfg)elifcfg.mode=="eval":evaluate(cfg)elifcfg.mode=="export":export(cfg)elifcfg.mode=="infer":inference(cfg)else:raiseValueError(f"cfg.mode should in ['train', 'eval', 'export', 'infer'], but got '{cfg.mode}'")if__name__=="__main__":main()
# Copyright (c) 2023 PaddlePaddle Authors. All Rights Reserved.## Licensed under the Apache License, Version 2.0 (the "License");# you may not use this file except in compliance with the License.# You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.importfunctoolsimportosfromosimportpathasospfromtypingimportTupleimporth5pyimporthydraimportnumpyasnpimportpaddleimportutilsasfourcast_utilsfromomegaconfimportDictConfigimportppscifromppsci.utilsimportloggerdefget_vis_data(file_path:str,date_strings:Tuple[str,...],num_timestamps:int,vars_channel:Tuple[int,...],img_h:int,data_mean:np.ndarray,data_std:np.ndarray,):_file=h5py.File(file_path,"r")["fields"]data=[]fordate_strindate_strings:hours_since_jan_01_epoch=fourcast_utils.date_to_hours(date_str)ic=int(hours_since_jan_01_epoch/6)data.append(_file[ic:ic+num_timestamps+1,vars_channel,0:img_h])data=np.asarray(data)vis_data={"input":(data[:,0]-data_mean)/data_std}fortinrange(num_timestamps):hour=(t+1)*6data_t=data[:,t+1]wind_data=[]foriinrange(data_t.shape[0]):wind_data.append((data_t[i][0]**2+data_t[i][1]**2)**0.5)vis_data[f"target_{hour}h"]=np.asarray(wind_data)returnvis_datadeftrain(cfg:DictConfig):# set random seed for reproducibilityppsci.utils.set_random_seed(cfg.seed)# initialize loggerlogger.init_logger("ppsci",osp.join(cfg.output_dir,"train.log"),"info")# set training hyper-parametersoutput_keys=tuple(f"output_{i}"foriinrange(cfg.TRAIN.num_timestamps))data_mean,data_std=fourcast_utils.get_mean_std(cfg.DATA_MEAN_PATH,cfg.DATA_STD_PATH,cfg.VARS_CHANNEL)data_time_mean=fourcast_utils.get_time_mean(cfg.DATA_TIME_MEAN_PATH,cfg.IMG_H,cfg.IMG_W,cfg.VARS_CHANNEL)data_time_mean_normalize=np.expand_dims((data_time_mean[0]-data_mean)/data_std,0)# set transformstransforms=[{"SqueezeData":{}},{"CropData":{"xmin":(0,0),"xmax":(cfg.IMG_H,cfg.IMG_W)}},{"Normalize":{"mean":data_mean,"std":data_std}},]# set train dataloader configtrain_dataloader_cfg={"dataset":{"name":"ERA5Dataset","file_path":cfg.TRAIN_FILE_PATH,"input_keys":cfg.MODEL.afno.input_keys,"label_keys":output_keys,"vars_channel":cfg.VARS_CHANNEL,"num_label_timestamps":cfg.TRAIN.num_timestamps,"transforms":transforms,},"sampler":{"name":"BatchSampler","drop_last":True,"shuffle":True,},"batch_size":cfg.TRAIN.batch_size,"num_workers":8,}# set constraintsup_constraint=ppsci.constraint.SupervisedConstraint(train_dataloader_cfg,ppsci.loss.L2RelLoss(),name="Sup",)constraint={sup_constraint.name:sup_constraint}# set iters_per_epoch by dataloader lengthITERS_PER_EPOCH=len(sup_constraint.data_loader)# set eval dataloader configeval_dataloader_cfg={"dataset":{"name":"ERA5Dataset","file_path":cfg.VALID_FILE_PATH,"input_keys":cfg.MODEL.afno.input_keys,"label_keys":output_keys,"vars_channel":cfg.VARS_CHANNEL,"transforms":transforms,"num_label_timestamps":cfg.TRAIN.num_timestamps,"training":False,},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,}# set metricmetric={"MAE":ppsci.metric.MAE(keep_batch=True),"LatitudeWeightedRMSE":ppsci.metric.LatitudeWeightedRMSE(num_lat=cfg.IMG_H,std=data_std,keep_batch=True,variable_dict={"u10":0,"v10":1},),"LatitudeWeightedACC":ppsci.metric.LatitudeWeightedACC(num_lat=cfg.IMG_H,mean=data_time_mean_normalize,keep_batch=True,variable_dict={"u10":0,"v10":1},),}# set validatorsup_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,ppsci.loss.L2RelLoss(),metric=metric,name="Sup_Validator",)validator={sup_validator.name:sup_validator}# set modelmodel_cfg=dict(cfg.MODEL.afno)model_cfg.update({"output_keys":output_keys,"num_timestamps":cfg.TRAIN.num_timestamps})model=ppsci.arch.AFNONet(**model_cfg)# init optimizer and lr schedulerlr_scheduler_cfg=dict(cfg.TRAIN.lr_scheduler)lr_scheduler_cfg.update({"iters_per_epoch":ITERS_PER_EPOCH})lr_scheduler=ppsci.optimizer.lr_scheduler.Cosine(**lr_scheduler_cfg)()optimizer=ppsci.optimizer.Adam(lr_scheduler)(model)# initialize solversolver=ppsci.solver.Solver(model,constraint,cfg.output_dir,optimizer,lr_scheduler,cfg.TRAIN.epochs,ITERS_PER_EPOCH,eval_during_train=True,validator=validator,pretrained_model_path=cfg.TRAIN.pretrained_model_path,compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,eval_with_no_grad=cfg.EVAL.eval_with_no_grad,)# train modelsolver.train()# evaluate after finished trainingsolver.eval()defevaluate(cfg:DictConfig):# set random seed for reproducibilityppsci.utils.misc.set_random_seed(cfg.seed)# initialize loggerlogger.init_logger("ppsci",osp.join(cfg.output_dir,"eval.log"),"info")# set testing hyper-parametersoutput_keys=tuple(f"output_{i}"foriinrange(cfg.EVAL.num_timestamps))data_mean,data_std=fourcast_utils.get_mean_std(cfg.DATA_MEAN_PATH,cfg.DATA_STD_PATH,cfg.VARS_CHANNEL)data_time_mean=fourcast_utils.get_time_mean(cfg.DATA_TIME_MEAN_PATH,cfg.IMG_H,cfg.IMG_W,cfg.VARS_CHANNEL)data_time_mean_normalize=np.expand_dims((data_time_mean[0]-data_mean)/data_std,0)# set transformstransforms=[{"SqueezeData":{}},{"CropData":{"xmin":(0,0),"xmax":(cfg.IMG_H,cfg.IMG_W)}},{"Normalize":{"mean":data_mean,"std":data_std}},]# set modelmodel_cfg=dict(cfg.MODEL.afno)model_cfg.update({"output_keys":output_keys,"num_timestamps":cfg.EVAL.num_timestamps})model=ppsci.arch.AFNONet(**model_cfg)# set eval dataloader configeval_dataloader_cfg={"dataset":{"name":"ERA5Dataset","file_path":cfg.TEST_FILE_PATH,"input_keys":cfg.MODEL.afno.input_keys,"label_keys":output_keys,"vars_channel":cfg.VARS_CHANNEL,"transforms":transforms,"num_label_timestamps":cfg.EVAL.num_timestamps,"training":False,"stride":8,},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,}# set metircmetric={"MAE":ppsci.metric.MAE(keep_batch=True),"LatitudeWeightedRMSE":ppsci.metric.LatitudeWeightedRMSE(num_lat=cfg.IMG_H,std=data_std,keep_batch=True,variable_dict={"u10":0,"v10":1},),"LatitudeWeightedACC":ppsci.metric.LatitudeWeightedACC(num_lat=cfg.IMG_H,mean=data_time_mean_normalize,keep_batch=True,variable_dict={"u10":0,"v10":1},),}# set validator for testingsup_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,ppsci.loss.L2RelLoss(),metric=metric,name="Sup_Validator",)validator={sup_validator.name:sup_validator}# set visualizer dataDATE_STRINGS=("2018-09-08 00:00:00",)vis_data=get_vis_data(cfg.TEST_FILE_PATH,DATE_STRINGS,cfg.EVAL.num_timestamps,cfg.VARS_CHANNEL,cfg.IMG_H,data_mean,data_std,)defoutput_wind_func(d,var_name,data_mean,data_std):output=(d[var_name]*data_std)+data_meanwind_data=[]foriinrange(output.shape[0]):wind_data.append((output[i][0]**2+output[i][1]**2)**0.5)returnpaddle.to_tensor(wind_data,paddle.get_default_dtype())vis_output_expr={}foriinrange(cfg.EVAL.num_timestamps):hour=(i+1)*6vis_output_expr[f"output_{hour}h"]=functools.partial(output_wind_func,var_name=f"output_{i}",data_mean=paddle.to_tensor(data_mean,paddle.get_default_dtype()),data_std=paddle.to_tensor(data_std,paddle.get_default_dtype()),)vis_output_expr[f"target_{hour}h"]=lambdad,hour=hour:d[f"target_{hour}h"]# set visualizervisualizer={"visualize_wind":ppsci.visualize.VisualizerWeather(vis_data,vis_output_expr,xticks=np.linspace(0,1439,13),xticklabels=[str(i)foriinrange(360,-1,-30)],yticks=np.linspace(0,719,7),yticklabels=[str(i)foriinrange(90,-91,-30)],vmin=0,vmax=25,colorbar_label="m\s",batch_size=cfg.EVAL.batch_size,num_timestamps=cfg.EVAL.num_timestamps,prefix="wind",)}solver=ppsci.solver.Solver(model,output_dir=cfg.output_dir,validator=validator,visualizer=visualizer,pretrained_model_path=cfg.EVAL.pretrained_model_path,compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,eval_with_no_grad=cfg.EVAL.eval_with_no_grad,)solver.eval()# visualize prediction from pretrained_model_pathsolver.visualize()defexport(cfg:DictConfig):# set modelmodel=ppsci.arch.AFNONet(**cfg.MODEL.afno)# initialize solversolver=ppsci.solver.Solver(model,pretrained_model_path=cfg.INFER.pretrained_model_path,)# export modelfrompaddle.staticimportInputSpecinput_spec=[{key:InputSpec([None,20,cfg.IMG_H,cfg.IMG_W],"float32",name=key)forkeyinmodel.input_keys},]solver.export(input_spec,cfg.INFER.export_path)definference(cfg:DictConfig):fromdeploy.python_inferimportpinn_predictorpredictor=pinn_predictor.PINNPredictor(cfg)data_mean,data_std=fourcast_utils.get_mean_std(cfg.DATA_MEAN_PATH,cfg.DATA_STD_PATH,cfg.VARS_CHANNEL)data=np.load(cfg.INFER_FILE_PATH)input_0=(data[:,0]-data_mean)/data_stdall_data=input_0fortinrange(cfg.INFER.num_timestamps):data_t=data[:,t+1]data_t=(data_t-data_mean)/data_stdall_data=np.concatenate((all_data,data_t),axis=0)input_dict={cfg.MODEL.afno.input_keys[0]:all_data}vis_output=predictor.predict(input_dict,cfg.INFER.batch_size)vis_dict={store_key:vis_output[infer_key]forstore_key,infer_keyinzip(cfg.MODEL.afno.output_keys,vis_output.keys())}defoutput_wind_func(output,data_mean,data_std):output=(output*data_std)+data_meanwind_data=(output[0]**2+output[1]**2)**0.5returnwind_datawind_pred=[]pred_dict={}foriinrange(cfg.INFER.num_timestamps):hour=(i+1)*6wind_=[output_wind_func(vis_dict[cfg.MODEL.afno.output_keys[0]][i],data_mean,data_std)]wind_pred.append(wind_)pred_dict[f"output_{hour}h"]=np.asarray(wind_)output_dict={cfg.MODEL.afno.output_keys[0]:np.array(wind_pred)}wind_pred=[]target_dict={}foriinrange(cfg.INFER.num_timestamps):hour=(i+1)*6wind_=[(data[0][i][0]**2+data[0][i][1]**2)**0.5]target_dict[f"target_{hour}h"]=np.asarray(wind_)vis_dict={**pred_dict,**target_dict}plot_expr_dict={}forhourinrange(6,6+cfg.INFER.num_timestamps*6,6):plot_expr_dict.update({f"target_{hour}h":lambdad,hour=hour:d[f"target_{hour}h"],f"output_{hour}h":lambdad,hour=hour:d[f"output_{hour}h"],})visualizer_weather=ppsci.visualize.VisualizerWeather(vis_dict,plot_expr_dict,xticks=np.linspace(0,cfg.IMG_W-1,13),xticklabels=[str(i)foriinrange(360,-1,-30)],yticks=np.linspace(0,cfg.IMG_H-1,7),yticklabels=[str(i)foriinrange(90,-91,-30)],vmin=0,vmax=25,colorbar_label="m\s",batch_size=1,num_timestamps=cfg.INFER.num_timestamps,prefix="wind",)visualizer_weather.save(cfg.INFER.export_path,vis_dict)save_path=osp.join(cfg.INFER.export_path,"predict.npy")os.makedirs(cfg.INFER.export_path,exist_ok=True)np.save(save_path,output_dict[cfg.MODEL.afno.output_keys[0]])@hydra.main(version_base=None,config_path="./conf",config_name="fourcastnet_finetune.yaml")defmain(cfg:DictConfig):ifcfg.mode=="train":train(cfg)elifcfg.mode=="eval":evaluate(cfg)elifcfg.mode=="export":export(cfg)elifcfg.mode=="infer":inference(cfg)else:raiseValueError(f"cfg.mode should in ['train', 'eval', 'export', 'infer'], but got '{cfg.mode}'")if__name__=="__main__":main()
# Copyright (c) 2023 PaddlePaddle Authors. All Rights Reserved.## Licensed under the Apache License, Version 2.0 (the "License");# you may not use this file except in compliance with the License.# You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.importfunctoolsimportosimportos.pathasospfromtypingimportTupleimporth5pyimporthydraimportnumpyasnpimportpaddleimportutilsasfourcast_utilsfromomegaconfimportDictConfigimportppscifromppsci.utilsimportloggerdefget_vis_data(wind_file_path:str,file_path:str,date_strings:Tuple[str,...],num_timestamps:int,vars_channel:Tuple[int,...],img_h:int,data_mean:np.ndarray,data_std:np.ndarray,):__wind_file=h5py.File(wind_file_path,"r")["fields"]_file=h5py.File(file_path,"r")["tp"]wind_data=[]data=[]fordate_strindate_strings:hours_since_jan_01_epoch=fourcast_utils.date_to_hours(date_str)ic=int(hours_since_jan_01_epoch/6)wind_data.append(__wind_file[ic,vars_channel,0:img_h])data.append(_file[ic+1:ic+num_timestamps+1,0:img_h])wind_data=np.asarray(wind_data)data=np.asarray(data)vis_data={"input":(wind_data-data_mean)/data_std}fortinrange(num_timestamps):hour=(t+1)*6data_t=data[:,t]vis_data[f"target_{hour}h"]=np.asarray(data_t)returnvis_datadeftrain(cfg:DictConfig):# set random seed for reproducibilityppsci.utils.set_random_seed(cfg.seed)# initialize loggerlogger.init_logger("ppsci",f"{cfg.output_dir}/train.log","info")wind_data_mean,wind_data_std=fourcast_utils.get_mean_std(cfg.WIND_MEAN_PATH,cfg.WIND_STD_PATH,cfg.VARS_CHANNEL)data_time_mean=fourcast_utils.get_time_mean(cfg.TIME_MEAN_PATH,cfg.IMG_H,cfg.IMG_W)# set train transformstransforms=[{"SqueezeData":{}},{"CropData":{"xmin":(0,0),"xmax":(cfg.IMG_H,cfg.IMG_W)}},{"Normalize":{"mean":wind_data_mean,"std":wind_data_std,"apply_keys":("input",),}},{"Log1p":{"scale":1e-5,"apply_keys":("label",)}},]# set train dataloader configtrain_dataloader_cfg={"dataset":{"name":"ERA5Dataset","file_path":cfg.WIND_TRAIN_FILE_PATH,"input_keys":cfg.MODEL.precip.input_keys,"label_keys":cfg.MODEL.precip.output_keys,"vars_channel":cfg.VARS_CHANNEL,"precip_file_path":cfg.TRAIN_FILE_PATH,"transforms":transforms,},"sampler":{"name":"BatchSampler","drop_last":True,"shuffle":True,},"batch_size":cfg.TRAIN.batch_size,"num_workers":8,}# set constraintsup_constraint=ppsci.constraint.SupervisedConstraint(train_dataloader_cfg,ppsci.loss.L2RelLoss(),name="Sup",)constraint={sup_constraint.name:sup_constraint}# set iters_per_epoch by dataloader lengthITERS_PER_EPOCH=len(sup_constraint.data_loader)# set eval dataloader configeval_dataloader_cfg={"dataset":{"name":"ERA5Dataset","file_path":cfg.WIND_VALID_FILE_PATH,"input_keys":cfg.MODEL.precip.input_keys,"label_keys":cfg.MODEL.precip.output_keys,"vars_channel":cfg.VARS_CHANNEL,"precip_file_path":cfg.VALID_FILE_PATH,"transforms":transforms,"training":False,},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,}# set metricmetric={"MAE":ppsci.metric.MAE(keep_batch=True),"LatitudeWeightedRMSE":ppsci.metric.LatitudeWeightedRMSE(num_lat=cfg.IMG_H,keep_batch=True,unlog=True),"LatitudeWeightedACC":ppsci.metric.LatitudeWeightedACC(num_lat=cfg.IMG_H,mean=data_time_mean,keep_batch=True,unlog=True),}# set validatorsup_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,ppsci.loss.L2RelLoss(),metric=metric,name="Sup_Validator",)validator={sup_validator.name:sup_validator}# set modelwind_model=ppsci.arch.AFNONet(**cfg.MODEL.afno)ppsci.utils.save_load.load_pretrain(wind_model,path=cfg.WIND_MODEL_PATH)model_cfg=dict(cfg.MODEL.precip)model_cfg.update({"wind_model":wind_model})model=ppsci.arch.PrecipNet(**model_cfg)# init optimizer and lr schedulerlr_scheduler_cfg=dict(cfg.TRAIN.lr_scheduler)lr_scheduler_cfg.update({"iters_per_epoch":ITERS_PER_EPOCH})lr_scheduler=ppsci.optimizer.lr_scheduler.Cosine(**lr_scheduler_cfg)()optimizer=ppsci.optimizer.Adam(lr_scheduler)(model)# initialize solversolver=ppsci.solver.Solver(model,constraint,cfg.output_dir,optimizer,lr_scheduler,cfg.TRAIN.epochs,ITERS_PER_EPOCH,eval_during_train=True,validator=validator,compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,eval_with_no_grad=cfg.EVAL.eval_with_no_grad,)# train modelsolver.train()# evaluate after finished trainingsolver.eval()defevaluate(cfg:DictConfig):# set random seed for reproducibilityppsci.utils.misc.set_random_seed(cfg.seed)# initialize loggerlogger.init_logger("ppsci",osp.join(cfg.output_dir,"eval.log"),"info")# set testing hyper-parametersoutput_keys=tuple(f"output_{i}"foriinrange(cfg.EVAL.num_timestamps))# set model for testingwind_model=ppsci.arch.AFNONet(**cfg.MODEL.afno)ppsci.utils.save_load.load_pretrain(wind_model,path=cfg.WIND_MODEL_PATH)model_cfg=dict(cfg.MODEL.precip)model_cfg.update({"output_keys":output_keys,"num_timestamps":cfg.EVAL.num_timestamps,"wind_model":wind_model,})model=ppsci.arch.PrecipNet(**model_cfg)wind_data_mean,wind_data_std=fourcast_utils.get_mean_std(cfg.WIND_MEAN_PATH,cfg.WIND_STD_PATH,cfg.VARS_CHANNEL)data_time_mean=fourcast_utils.get_time_mean(cfg.TIME_MEAN_PATH,cfg.IMG_H,cfg.IMG_W)# set train transformstransforms=[{"SqueezeData":{}},{"CropData":{"xmin":(0,0),"xmax":(cfg.IMG_H,cfg.IMG_W)}},{"Normalize":{"mean":wind_data_mean,"std":wind_data_std,"apply_keys":("input",),}},{"Log1p":{"scale":1e-5,"apply_keys":("label",)}},]eval_dataloader_cfg={"dataset":{"name":"ERA5Dataset","file_path":cfg.WIND_TEST_FILE_PATH,"input_keys":cfg.MODEL.precip.input_keys,"label_keys":output_keys,"vars_channel":cfg.VARS_CHANNEL,"precip_file_path":cfg.TEST_FILE_PATH,"num_label_timestamps":cfg.EVAL.num_timestamps,"stride":8,"transforms":transforms,"training":False,},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,}# set metircmetric={"MAE":ppsci.metric.MAE(keep_batch=True),"LatitudeWeightedRMSE":ppsci.metric.LatitudeWeightedRMSE(num_lat=cfg.IMG_H,keep_batch=True,unlog=True),"LatitudeWeightedACC":ppsci.metric.LatitudeWeightedACC(num_lat=cfg.IMG_H,mean=data_time_mean,keep_batch=True,unlog=True),}# set validator for testingsup_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,ppsci.loss.L2RelLoss(),metric=metric,name="Sup_Validator",)validator={sup_validator.name:sup_validator}# set set visualizer dataDATE_STRINGS=("2018-04-04 00:00:00",)vis_data=get_vis_data(cfg.WIND_TEST_FILE_PATH,cfg.TEST_FILE_PATH,DATE_STRINGS,cfg.EVAL.num_timestamps,cfg.VARS_CHANNEL,cfg.IMG_H,wind_data_mean,wind_data_std,)defoutput_precip_func(d,var_name):output=1e-2*paddle.expm1(d[var_name][0])returnoutputvisu_output_expr={}foriinrange(cfg.EVAL.num_timestamps):hour=(i+1)*6visu_output_expr[f"output_{hour}h"]=functools.partial(output_precip_func,var_name=f"output_{i}",)visu_output_expr[f"target_{hour}h"]=(lambdad,hour=hour:d[f"target_{hour}h"]*1000)# set visualizervisualizer={"visualize_precip":ppsci.visualize.VisualizerWeather(vis_data,visu_output_expr,xticks=np.linspace(0,1439,13),xticklabels=[str(i)foriinrange(360,-1,-30)],yticks=np.linspace(0,719,7),yticklabels=[str(i)foriinrange(90,-91,-30)],vmin=0.001,vmax=130,colorbar_label="mm",log_norm=True,batch_size=cfg.EVAL.batch_size,num_timestamps=cfg.EVAL.num_timestamps,prefix="precip",)}solver=ppsci.solver.Solver(model,output_dir=cfg.output_dir,validator=validator,visualizer=visualizer,pretrained_model_path=cfg.EVAL.pretrained_model_path,compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,eval_with_no_grad=cfg.EVAL.eval_with_no_grad,)solver.eval()# visualize predictionsolver.visualize()defexport(cfg:DictConfig):# set modelwind_model=ppsci.arch.AFNONet(**cfg.MODEL.afno)ppsci.utils.save_load.load_pretrain(wind_model,path=cfg.INFER.WIND_MODEL_PATH)output_keys=tuple(f"output_{i}"foriinrange(cfg.INFER.num_timestamps))model_cfg=dict(cfg.MODEL.precip)model_cfg.update({"output_keys":output_keys,"num_timestamps":cfg.INFER.num_timestamps,"wind_model":wind_model,})model=ppsci.arch.PrecipNet(**model_cfg)# initialize solversolver=ppsci.solver.Solver(model,pretrained_model_path=cfg.INFER.pretrained_model_path,)# export modelfrompaddle.staticimportInputSpecinput_spec=[{key:InputSpec([None,20,cfg.IMG_H,cfg.IMG_W],"float32",name=key)forkeyinmodel.input_keys},]solver.export(input_spec,cfg.INFER.export_path)definference(cfg:DictConfig):output_keys=tuple(f"output_{i}"foriinrange(cfg.INFER.num_timestamps))model_cfg=dict(cfg.MODEL.precip)model_cfg.update({"output_keys":output_keys,})fromdeploy.python_inferimportpinn_predictorpredictor=pinn_predictor.PINNPredictor(cfg)data_mean,data_std=fourcast_utils.get_mean_std(cfg.WIND_MEAN_PATH,cfg.WIND_STD_PATH,cfg.VARS_CHANNEL)wind_data=np.load(cfg.WIND_INFER_PATH)data=np.load(cfg.INFER_FILE_PATH)input_datas=(wind_data-data_mean)/data_stdinput_dict={cfg.MODEL.precip.input_keys[0]:input_datas}vis_datas={cfg.MODEL.precip.input_keys[0]:input_datas}fortinrange(cfg.INFER.num_timestamps):hour=(t+1)*6data_t=data[:,t]*1000vis_datas[f"target_{hour}h"]=np.asarray(data_t)vis_output=predictor.predict(input_dict,cfg.INFER.batch_size)re_dict={store_key:vis_output[infer_key]forstore_key,infer_keyinzip(model_cfg["output_keys"],vis_output.keys())}plot_dict=vis_datasoutput_dict={}fortinrange(cfg.INFER.num_timestamps):hour=(t+1)*6output_dict[f"output_{t}"]=1e-2*np.expm1(re_dict[f"output_{t}"][0])plot_dict[f"output_{hour}h"]=output_dict[f"output_{t}"]output=np.concatenate(list(output_dict.values()),axis=0)output_dict[cfg.MODEL.precip.output_keys[0]]=outputplot_expr_dict={}forhourinrange(6,6+cfg.INFER.num_timestamps*6,6):plot_expr_dict.update({f"target_{hour}h":lambdad,hour=hour:d[f"target_{hour}h"],f"output_{hour}h":lambdad,hour=hour:d[f"output_{hour}h"],})visualizer_weather=ppsci.visualize.VisualizerWeather(plot_dict,plot_expr_dict,xticks=np.linspace(0,cfg.IMG_W-1,13),xticklabels=[str(i)foriinrange(360,-1,-30)],yticks=np.linspace(0,cfg.IMG_H-1,7),yticklabels=[str(i)foriinrange(90,-91,-30)],vmin=0.001,vmax=130,colorbar_label="mm",log_norm=True,batch_size=1,num_timestamps=cfg.INFER.num_timestamps,prefix="precip",)visualizer_weather.save(cfg.INFER.export_path,plot_dict)save_path=osp.join(cfg.INFER.export_path,"predict.npy")os.makedirs(cfg.INFER.export_path,exist_ok=True)np.save(save_path,output_dict)@hydra.main(version_base=None,config_path="./conf",config_name="fourcastnet_precip.yaml")defmain(cfg:DictConfig):ifcfg.mode=="train":train(cfg)elifcfg.mode=="eval":evaluate(cfg)elifcfg.mode=="export":export(cfg)elifcfg.mode=="infer":inference(cfg)else:raiseValueError(f"cfg.mode should in ['train', 'eval', 'export', 'infer'], but got '{cfg.mode}'")if__name__=="__main__":main()