NSFNets¶
# VP_NSFNet1
python VP_NSFNet1.py
# VP_NSFNet2
# linux
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/NSFNet/cylinder_nektar_wake.mat -P ./data/
# windows
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/NSFNet/cylinder_nektar_wake.mat --create-dirs -o ./data/cylinder_nektar_wake.mat
python VP_NSFNet2.py data_dir=./data/cylinder_nektar_wake.mat
# VP_NSFNet3
python VP_NSFNet3.py
# VP_NSFNet1
python VP_NSFNet1.py mode=eval pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/nsfnet/nsfnet1.pdparams
# VP_NSFNet2
# linux
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/NSFNet/cylinder_nektar_wake.mat -P ./data/
# windows
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/NSFNet/cylinder_nektar_wake.mat --create-dirs -o ./data/cylinder_nektar_wake.mat
python VP_NSFNet2.py mode=eval data_dir=./data/cylinder_nektar_wake.mat pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/nsfnet/nsfnet2.pdparams
# VP_NSFNet3
python VP_NSFNet3.py mode=eval pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/nsfnet/nsfnet3.pdparams
1. Background Introduction¶
In recent years, deep learning has achieved remarkable achievements in many fields, especially in computer vision and natural language processing. Inspired by the rapid development of deep learning and based on the powerful function approximation ability of deep learning, neural networks have also achieved success in the field of scientific computing. Current research is mainly divided into two categories. One is to add physical information and physical constraints to the loss function to train neural networks, represented by PINN and Deep Ritz Net. The other is data-driven deep neural network operators, represented by FNO and DeepONet. These methods have been widely used in scientific practice, such as weather forecasting, quantum chemistry, biological engineering, and computational fluid dynamics. In order to fully explore the ability of PINN to solve fluid equations, the author of this reproduction paper designed NSFNets, and successively used two-dimensional and three-dimensional Navier-Stokes equations with analytical or numerical solutions, as well as datasets solved with high precision using the DNS method as references, to perform forward problem solving training. The paper experiments show that PINN has excellent numerical solving capabilities for incompressible Navier-Stokes equations. The main goal of this project is to use PaddleScience to reproduce the code for high-precision solving of Navier-Stokes equations implemented in the paper.
2. Problem Definition¶
The classic PINN model is used for this problem, so I won't go into details.
Mainly introduce several types of Navier-Stokes equations solved:
The incompressible Navier-Stokes equation can be expressed as:
2.1 Kovasznay flow(NSFNet1)¶
We use Kovasznay flow as the first test case to demonstrate the performance of NSFnets. This two-dimensional steady Navier-Stokes flow has the following analytical solution:
where
We consider the computational domain as \([−0.5, 1.0] × [−0.5, 1.5]\). We first determine the optimization strategy. There are \(101\) points with fixed spatial coordinates on each boundary, i.e., \(Nb = 4 × 101\). To calculate the equation loss of NSFnet, \(2,601\) points are randomly selected within the domain. This steady flow has no initial conditions. We use the Adam optimizer to provide a better set of initial neural network learnable variables. Then, L-BFGS-B is used to fine-tune the neural network to obtain higher accuracy. The training process of L-BFGS-B terminates automatically based on the increment tolerance. In this section, we use \(3 × 10^4\) Adam iterations with a learning rate of \(10^{−3}\) before L-BFGS-B training. The effect of the number of Adam iterations is discussed in Figure A.1 of Appendix A of the paper, and we also studied the performance of NSFnet in terms of the number of sampling points and boundary points.
2.2 Cylinder wake (NSFNet2)¶
Here we use NSFnets to simulate \(2D\) vortex shedding behind a cylinder at \(Re = 100\). The cylinder is placed at \((x, y) = (0, 0)\) with diameter \(D = 1\). High-fidelity DNS data from \(M. Raissi 2019\) is used as a reference and provides boundary and initial data for NSFnet training. We consider the domain defined by \([1, 8] × [−2, 2]\), with a time interval of \([0, 7]\) (over one shedding period) and a time step \(Δt = 0.1\). For training data, we place \(100\) points along the \(x\) direction boundary and \(50\) points along the y direction boundary to control boundary conditions, and use \(140,000\) spatiotemporal scattered points within the domain to calculate residuals. NSFnet contains \(10\) hidden layers with \(100\) neurons each. Cylinder wake AIstudio dataset link.
2.3 Beltrami flow (NSFNet3)¶
3. Problem Solving¶
3.1 Model Construction¶
This paper uses the classic PINN MLP model for training.
3.2 Hyperparameter Setting¶
Specify the number of residual points, boundary points, initial value points, and the weights of boundary loss function and initial value loss function can be specified
3.3 Data Generation¶
Since the dataset is an analytical solution, we first construct the analytical solution function
Then take boundary points, initial value points, and internal points for calculating residuals (see section 3.3 of paper for specific selection method) and generate test points.
3.4 Constraint Construction¶
Since our boundary points and initial value points have analytical solutions, we use supervised constraints
where alpha and beta are the weights of the loss function, which are both taken as 100 in this code, consistent with the description in the paper.
Use internal points to construct residual constraints of Navier-Stokes equations
3.5 Validator Construction¶
Use the test set generated during data generation for model evaluation:
3.6 Optimizer Construction¶
Consistent with the description in the paper, we use piecewise learning rate to construct the Adam optimizer, where the number of training epochs can be adjusted by adjusting epoch_list.
3.7 Model Training and Evaluation¶
After completing the above settings, you only need to pass the instantiated objects to ppsci.solver.Solver.
Finally start training:
4. Complete Code¶
NSFNet1:
| NSFNet1.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 | |
| NSFNet2.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 | |
| NSFNet3.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 | |
5. Result Display¶
Mainly refer to paper data and reference code data.
5.1 NSFNet1(Kovasznay flow)¶
| velocity | paper | code | PaddleScience | NN size |
|---|---|---|---|---|
| u | 0.072% | 0.080% | 0.056% | 4 × 50 |
| v | 0.058% | 0.539% | 0.399% | 4 × 50 |
| p | 0.027% | 0.722% | 1.123% | 4 × 50 |
As shown in the table, columns 2, 3, and 4 are the \(L_{2}\) errors reproduced by the paper, other developers, and PaddleScience respectively. The \(L_{2}\) errors of Kovasznay flow velocity \(u\), \(v\) in \(x\), \(y\) directions are 0.055% and 0.399%, which are better than the paper (Table 2) and reference code.
5.2 NSFNet2(Cylinder wake)¶
The \(L_{2}\) error of Cylinder wake predicted at \(t=0\). As shown in the table, the \(L_{2}\) errors of Cylinder flow velocity \(u\), \(v\) in \(x\), \(y\) directions are 0.138% and 0.488%, which are close to the paper (Figure 9) and code.
| velocity | paper (VP-NSFnet, \(\alpha=\beta=1\)) | paper (VP-NSFnet, dynamic weights) | code | PaddleScience | NN size |
|---|---|---|---|---|---|
| u | 0.09% | 0.01% | 0.403% | 0.138% | 4 × 50 |
| v | 0.25% | 0.05% | 1.5% | 0.488% | 4 × 50 |
| p | 1.9% | 0.8% | / | / | 4 × 50 |
The velocity field of the NSFNet2 (2D Cylinder Flow) case is shown in the figure below. The two pictures in the first row are the cylinder wake region. The picture in the first row shows the numerical distribution of the flow velocity \(u\) in the \(x\) streamline direction. The left side is the DNS high-fidelity data as a reference, and the right side is the neural network predicted value. Blue is a smaller value and green is a larger value. The distribution area is \(x=[1,8]\), \(y=[-2, 2]\). The picture in the second row shows the distribution of the flow velocity \(v\) in the \(y\) spanwise direction. The left side is the DNS high-fidelity data reference value, and the right side is the neural network predicted value. The distribution area is \(x=[1,8]\), \(y=[-2, 2]\).

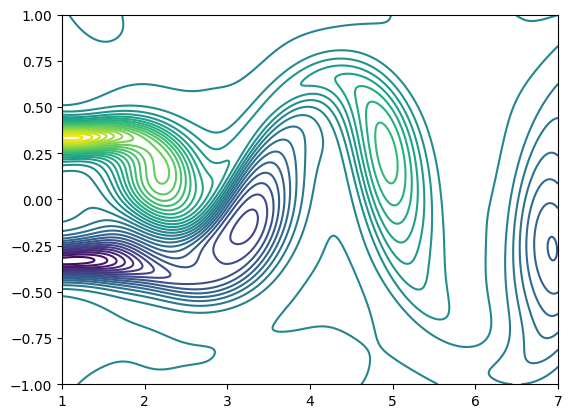
Based on the velocity field, we can calculate the vorticity field. As shown in the figure, it is the contour map of the vorticity field of the NSFNet2 (2D Cylinder Flow) case at time \(t=4.0\). We calculate the vorticity map as shown in the figure based on the flow velocities \(u\), \(v\) in the \(x\), \(y\) directions through the vorticity calculation formula. The vorticity structure has good continuity and is consistent with the paper. The calculation distribution area is \(x=[1, 8]\), \(y=[-2, 2]\).
5.3 NSFNet3(Beltrami flow)¶
The relative errors of the test dataset (analytical solution) are shown in the table. The \(L_{2}\) errors of Beltrami flow velocities \(u\), \(v\), \(w\) in \(x\), \(y\), \(z\) directions are 0.059%, 0.082% and 0.0732%, which are better than the code data.
| velocity | code(NN size:10×100) | PaddleScience (NN size:10×100) |
|---|---|---|
| u | 0.0766% | 0.059% |
| v | 0.0689% | 0.082% |
| w | 0.1090% | 0.073% |
| p | / | / |
The predicted relative errors of Beltrami flow at time $ t=1 $ on the $ z=0 $ plane are shown in the table. The \(L_{2}\) errors of Beltrami flow velocities \(u, v, w\) in \(x, y, z\) directions are 0.115%, 0.199% and 0.217%, and the \(L_{2}\) error of pressure \(p\) is 0.1.986%, which are all better than the paper data (Table 4. VP).
| velocity | paper(NN size:7×50) | PaddleScience(NN size:10×100) |
|---|---|---|
| u | 0.1634±0.0418% | 0.115% |
| v | 0.2185±0.0530% | 0.199% |
| w | 0.1783±0.0300% | 0.217% |
| p | 8.9335±2.4350% | 1.986% |
Beltrami flow velocity field, as shown in the figure, the left side is the analytical solution reference value, the right side is the neural network predicted value, blue is a smaller value, red is a larger value, the distribution area is \(x=[-1,1]\), \(y=[-1, 1]\), the first row is the distribution of flow velocity \(u\) in the \(x\) direction, the second row is the distribution of flow velocity \(v\) in the \(y\) direction, and the third row is the distribution of flow velocity \(w\) in the \(z\) direction.

6. Results Description¶
We use PINN to numerically solve the incompressible Navier-Stokes equations. In PINN, randomly selected time and space coordinates are used as input values, corresponding velocity fields and pressure fields are used as output values, and initial values, boundary conditions are used as supervised constraints and the Navier-Stokes equation itself is used as unsupervised constraints added to the loss function for training. We designed three different fluid cases for three different types of PINN Navier-Stokes equations, namely NSFNet1, NSFNet2, and NSFNet3. Through the decrease of the loss function, the comparison of the network prediction results with high-fidelity DNS data, and the reduction of the \(L_{2}\) error of the analytical solution, the convergence of the neural network in solving the Navier-Stokes equation can be proven, indicating that the NSFNets architecture possesses the ability to solve the incompressible Navier-Stokes equation. The experimental results show that the three forward problem cases using NSFNet can well approximate the reference solution, and we found that increasing the weights of boundary constraints and initial value constraints can enable the neural network to have better approximation effects.