Underground velocity images play an important role in the field of earth sciences. They reflect the propagation speed of seismic waves in various underground areas and provide key information for detecting the internal structure of the earth. Seismic waveform inversion methods are widely used to reconstruct underground velocity imaging. Traditional physics-driven solution methods are numerical optimization processes that require multiple iterations and solving wave equations. This is not only computationally expensive, but usually only achieves local optimal solutions, resulting in limited image accuracy. Data-driven deep learning methods can alleviate these problems and generate higher-precision velocity images in a shorter time.
VelocityGAN is a specific example. It is an end-to-end framework that can generate high-quality velocity images directly from raw seismic waveform data. The paper shows that VelocityGAN outperforms traditional physics-driven waveform inversion methods and achieves SOTA performance in data-driven benchmarks.
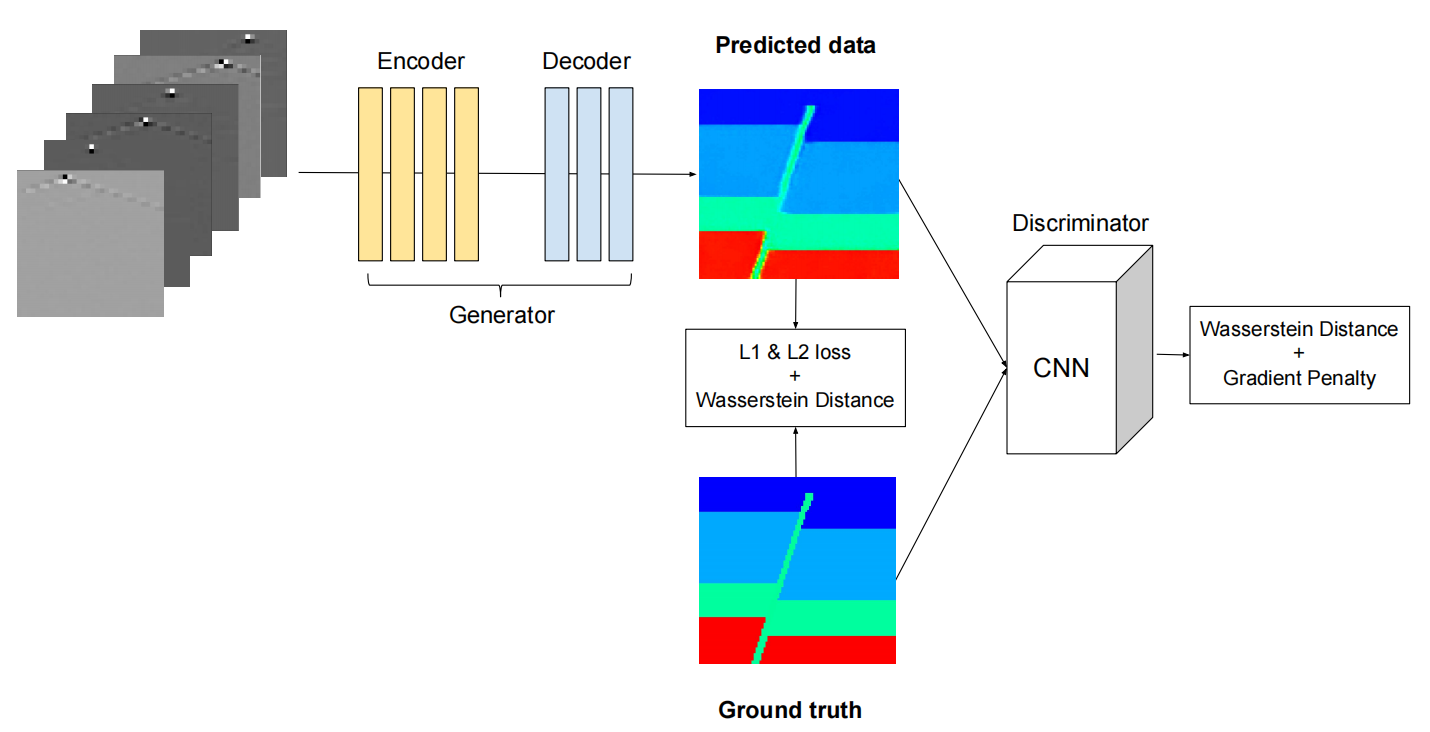
VelocityGAN is a conditional adversarial network containing an image-to-image generator and a CNN discriminator. The figure below shows the overall structure of the model.
Generator is a convolutional neural network with Encoder-Decoder structure. The Encoder extracts features from seismic waveform data and gradually compresses them into latent vectors; the Decoder infers the corresponding velocity map based on this latent vector.
Discriminator is a model composed of 9 convolutional blocks. Input velocity image, output image authenticity score.
Where \(\mathbb{P}_g\) is the generator distribution, \(\mathbb{P}_r\) is the real data distribution, and \(\mathbb{P}_{\hat{x}}\) is a mixed interpolation sample from \(\mathbb{P}_g\) and \(\mathbb{P}_r\).
The generator's loss function is a combination of adversarial loss [\(- \underset{\tilde{x} \sim \mathbb{P}_g}{\mathbb{E}}D(\tilde{x})\)] and content loss (MAE, MSE). Its expression is:
Where \(w\) and \(h\) are the width and height of the velocity map respectively, \(v(\cdot)\) and \(\tilde{v}(\cdot)\) represent the true pixel value and predicted pixel value of the velocity map respectively. \(\lambda_1\) and \(\lambda_2\) are hyperparameters used to adjust the relative importance of the two losses.
Next, we will explain how to use the PaddleScience framework to implement VelocityGAN. The following content only elaborates on key steps. For other details, please refer to API Documentation.
OpenFWI has a total of 12 datasets, divided into four categories: Vel Family, Fault Family, Style Family and Kimberlina Family. This case mainly uses the first two categories, and their configuration information is as follows:
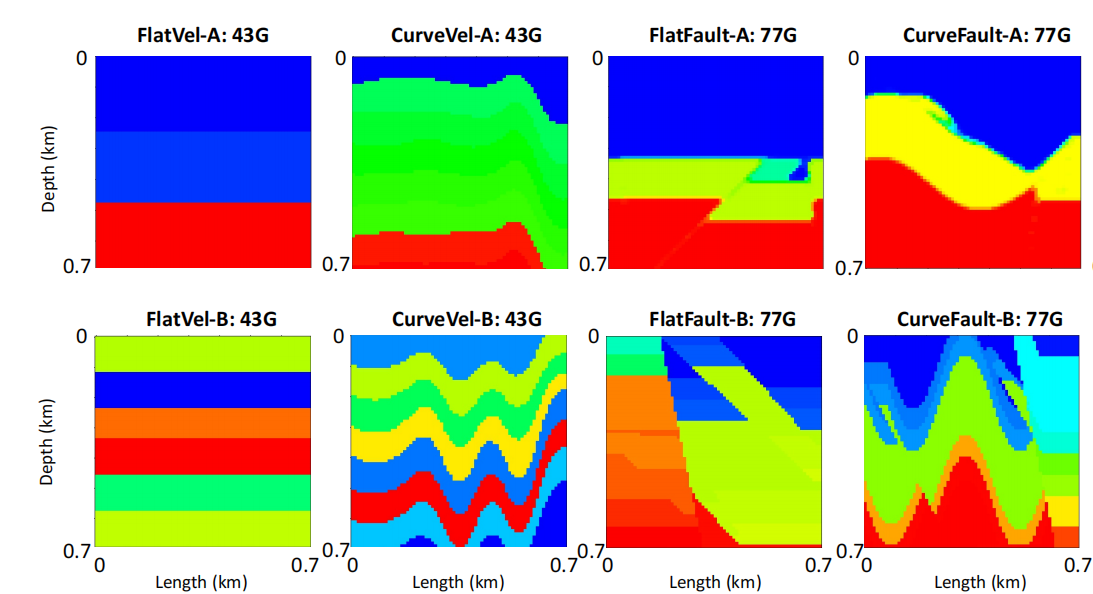
Among them, each dataset contains waveform data and corresponding velocity images. The figure below shows an example of velocity images in each dataset.
It can be seen that Vel Family includes two cases of straight and curved geological interfaces, while Fault Family adds some geological faults on this basis.
Each sample contains a velocity image and five waveform data, as shown in the figure below.
Among them, 5 red stars lined up represent five seismic sources on the ground, and 70 receivers are also arranged on the ground. Seismic waves propagate downwards and bounce back, and the receivers record data every 0.001 seconds, totaling 1000. Therefore, a seismic waveform dataset with a shape of (5, 1000, 70) is generated.
Since a dataset consists of 120 data files, passing in all file paths is cumbersome. In order to facilitate data reading, all paths can be packaged into a text file. By parsing the paths in turn, all data can be read. Due to this special reading method, we cannot use the built-in dataset API of PaddleScience, so we customized ppsci.data.dataset.FWIDataset.
The configuration code of dataloader is given below:
# set dataloader configdataloader_cfg={"dataset":{"name":"FWIDataset","input_keys":("data",),"label_keys":("real_image",),"anno":cfg.TRAIN.dataset.anno,"preload":cfg.TRAIN.dataset.preload,"sample_ratio":cfg.TRAIN.dataset.sample_ratio,"file_size":ctx["file_size"],"transform_data":transform_data,"transform_label":transform_label,},"sampler":{"name":"BatchSampler","shuffle":cfg.TRAIN.sampler.shuffle,"drop_last":cfg.TRAIN.sampler.drop_last,},"batch_size":cfg.TRAIN.batch_size,"use_shared_memory":cfg.TRAIN.use_shared_memory,"num_workers":cfg.TRAIN.num_workers,}
Among them, dataset uses our customized FWIDataset, and anno passes in the path of the text file, which contains the paths of all data files.
VelocityGAN in this case is not built into PaddleScience and needs to be implemented additionally, so we customized ppsci.arch.VelocityGenerator and ppsci.arch.VelocityDiscriminator.
# model settingsMODEL:gen_net:input_keys:["data"]output_keys:["fake_image"]dim1:32dim2:64dim3:128dim4:256dim5:512sample_spatial:1.0dis_net:input_keys:["image"]output_keys:["score"]dim1:32dim2:64dim3:128dim4:256
The loss function of VelocityGAN is a bit complicated and needs to be implemented by ourselves. PaddleScience provides an API for customizing loss functions - ppsci.loss.FunctionalLoss. The method is to define the loss function first, and then pass the function name as a parameter to FunctionalLoss. Note that the input and output of the custom loss function need to be in the format of a dictionary.
The loss of Generator includes L1 loss, L2 loss and adversarial loss. These three losses all have corresponding weights. If the weight of a certain loss is 0, it means that the loss item is not added during training.
defloss_func_gen(self,output_dict,label_dict,*args):"""Calculate loss of generator. The loss includes L1 loss, L2 loss, and adversarial loss. Each of these losses has a corresponding weight, and if the weight of any loss is zero, it means that this loss component is not added during training. Args: output_dict: Output dict of model. label_dict: Label dict. Returns: Loss of generator. """l1loss=paddle.nn.L1Loss()l2loss=paddle.nn.MSELoss()pred=output_dict["fake_image"]label=label_dict["real_image"]loss_g1v=l1loss(pred,label)loss_g2v=l2loss(pred,label)loss=(self.weight["lambda_g1v"]*loss_g1v+self.weight["lambda_g2v"]*loss_g2v)loss_adv=-paddle.mean(self.model_dis({"image":pred})["score"])loss+=self.weight["lambda_adv"]*loss_advreturn{"loss_g":loss}
defloss_func_dis(self,output_dict,label_dict,*args):"""Calculate loss of discriminator. The discriminator's loss includes Wasserstein loss and gradient penalty, and only the gradient penalty has a weight parameter. Args: output_dict: Output dict of model. label_dict: Label dict. Returns: Loss of discriminator. """pred=output_dict["fake_image"]pred.stop_gradient=Truelabel=label_dict["real_image"]gradient_penalty=self.compute_gradient_penalty(label,pred)loss_real=paddle.mean(self.model_dis({"image":label})["score"])loss_fake=paddle.mean(self.model_dis({"image":pred})["score"])loss=-loss_real+loss_fake+gradient_penalty*self.weight["lambda_gp"]return{"loss_d":loss}defcompute_gradient_penalty(self,real_samples,fake_samples):"""Calculate the gradient penalty. Generate a random interpolation factor, create mixed samples, process through the discriminator, compute the gradient of the output, apply L2 norm and constrain it to 1, and finally obtain the gradient penalty. Args: real_samples: Ground truth data from dataset. fake_samples: Generated data from generator. Returns: Gradient penalty. """alpha=paddle.rand([real_samples.shape[0],1,1,1],dtype=real_samples.dtype)interpolates=alpha*real_samples+(1-alpha)*fake_samplesinterpolates.stop_gradient=False# Allow gradients to be calculatedd_interpolates=self.model_dis({"image":interpolates})["score"]gradients=paddle.grad(outputs=d_interpolates,inputs=interpolates,create_graph=True,retain_graph=True,only_inputs=True,)[0]gradients=gradients.reshape([gradients.shape[0],-1])gradient_penalty=paddle.mean((paddle.norm(gradients,p=2,axis=1)-1)**2)returngradient_penalty
Indicates that the pred variable does not participate in gradient calculation. This is because pred is only used as the input of Discriminator and its gradient does not need to be considered. Moreover, pred is the output of Generator. If gradient calculation is not stopped, the parameter gradient of Generator will accumulate during discriminator training and eventually affect the training of the first batch of the generator.
# set constraintconstraint_gen=ppsci.constraint.SupervisedConstraint(dataloader_cfg=dataloader_cfg,loss=ppsci.loss.FunctionalLoss(gen_funcs.loss_func_gen),output_expr={"fake_image":lambdaout:out["fake_image"]},name="cst_gen",)constraint_gen_dict={constraint_gen.name:constraint_gen}constraint_dis=ppsci.constraint.SupervisedConstraint(dataloader_cfg=dataloader_cfg,loss=ppsci.loss.FunctionalLoss(dis_funcs.loss_func_dis),output_expr={"fake_image":lambdaout:out["fake_image"]},name="cst_dis",)constraint_dis_dict={constraint_dis.name:constraint_dis}
Among them, output_expr specifies how to construct output_dict, and name is the name of the constraint, which is convenient for subsequent indexing.
After the constraint construction is completed, it needs to be created in the form of a dictionary for easy passing to ppsci.solver.Solver later.
# set optimizeroptimizer=ppsci.optimizer.AdamW(learning_rate=cfg.TRAIN.learning_rate,weight_decay=cfg.TRAIN.weight_decay)optimizer_g=optimizer(model_gen)optimizer_d=optimizer(model_dis)
The evaluation indicators of this case are: MAE (Mean Absolute Error), RMSE (Root Mean Squared Error) and SSIM (Structural SIMilarity). Among them, PaddleScience provides APIs for MAE and RMSE, while SSIM requires us to implement it additionally.
PaddleScience provides an API for customizing metric functions - ppsci.metric.FunctionalMetric. The method is to define the metric function first, and then pass the function name as a parameter to FunctionalMetric. Note that the input and output of the custom metric function need to be in the format of a dictionary.
classSSIM(paddle.nn.Layer):""" SSIM is used to measure the similarity between two images. Attributes: window_size (int): The size of the gaussian window used for computing SSIM. Defaults to 11. size_average (bool): If True, the SSIM values across spatial dimensions are averaged. Defaults to True. Methods: forward(img1, img2): Computes the SSIM score between two images using a gaussian filter defined by `window`. """def__init__(self,window_size=11,size_average=True):super(SSIM,self).__init__()self.window_size=window_sizeself.size_average=size_averageself.channel=1self.window=create_window(window_size,self.channel)defforward(self,img1,img2):_,channel,_,_=img1.shapeifchannel==self.channelandself.window.dtype==img1.dtype:window=self.windowelse:window=create_window(self.window_size,channel)ifimg1.place.is_gpu_place():window=window.cuda(img1.place.gpu_device_id())window=window.astype(img1.dtype)self.window=windowself.channel=channelreturn_ssim(img1,img2,window,self.window_size,channel,self.size_average)defgaussian(window_size,sigma):gauss=paddle.to_tensor(data=[exp(-((x-window_size//2)**2)/float(2*sigma**2))forxinrange(window_size)],dtype="float32",)returngauss/gauss.sum()defcreate_window(window_size,channel):_1D_window=gaussian(window_size,1.5).unsqueeze(1)_2D_window=(paddle.mm(_1D_window,_1D_window.t()).astype("float32").unsqueeze(0).unsqueeze(0))window=_2D_window.expand([channel,1,window_size,window_size])returnwindowdef_ssim(img1,img2,window,window_size,channel,size_average=True):mu1=paddle.nn.functional.conv2d(x=img1,weight=window,padding=window_size//2,groups=channel)mu2=paddle.nn.functional.conv2d(x=img2,weight=window,padding=window_size//2,groups=channel)mu1_sq=mu1.pow(y=2)mu2_sq=mu2.pow(y=2)mu1_mu2=mu1*mu2sigma1_sq=(paddle.nn.functional.conv2d(x=img1*img1,weight=window,padding=window_size//2,groups=channel)-mu1_sq)sigma2_sq=(paddle.nn.functional.conv2d(x=img2*img2,weight=window,padding=window_size//2,groups=channel)-mu2_sq)sigma12=(paddle.nn.functional.conv2d(x=img1*img2,weight=window,padding=window_size//2,groups=channel)-mu1_mu2)C1=0.01**2C2=0.03**2ssim_map=((2*mu1_mu2+C1)*(2*sigma12+C2)/((mu1_sq+mu2_sq+C1)*(sigma1_sq+sigma2_sq+C2)))ifsize_average:returnssim_map.mean()else:returnssim_map.mean(axis=1).mean(axis=1).mean(axis=1)defssim_metirc(output_dict,label_dict):ssim_loss=SSIM(window_size=11)metric_dict={}forkeyinlabel_dict:ssim=ssim_loss(label_dict[key]/2+0.5,output_dict[key]/2+0.5)metric_dict[key]=ssimreturnmetric_dict
# set validatorvalidator=ppsci.validate.SupervisedValidator(dataloader_cfg=valid_dataloader_cfg,loss=ppsci.loss.MAELoss("mean"),output_expr={"real_image":lambdaout:out["fake_image"]},metric={"MAE":ppsci.metric.MAE(),"RMSE":ppsci.metric.RMSE(),"SSIM":ppsci.metric.FunctionalMetric(func_module.ssim_metirc),},name="val",)validator_dict={validator.name:validator}
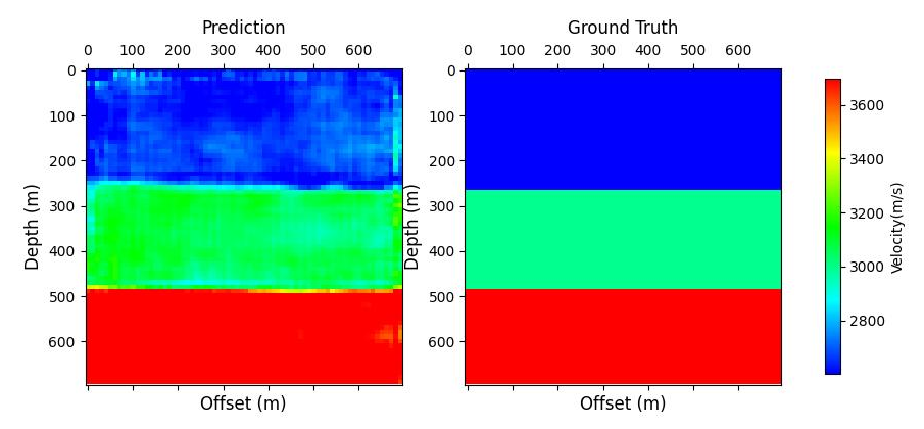
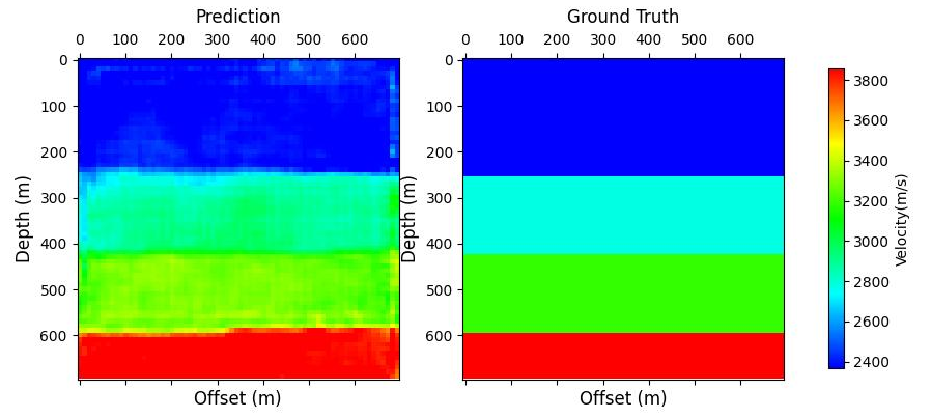
# visualizationifcfg.VIS.vis:withsolver.no_grad_context_manager(True):forbatch_idx,(input_,label_,_)inenumerate(validator.data_loader):ifbatch_idx+1>cfg.VIS.vb:breakfake_image=model_gen(input_)["fake_image"].numpy()real_image=label_["real_image"].numpy()foriinrange(cfg.VIS.vsa):plot_velocity(fake_image[i,0],real_image[i,0],f"{cfg.output_dir}/V_{batch_idx}_{i}.png",)print(f"The visualizations are saved to {cfg.output_dir}")
importjsonimportosimportsysimportfunctionsasfunc_moduleimporthydraimportpaddlefromfunctionsimportplot_velocityfromomegaconfimportDictConfigimportppscifromppsci.utilsimportloggeros.environ["FLAGS_embedding_deterministic"]="1"os.environ["FLAGS_cudnn_deterministic"]="1"os.environ["NVIDIA_TF32_OVERRIDE"]="0"os.environ["NCCL_ALGO"]="Tree"defevaluate(cfg:DictConfig):# get dataset configuration informationwithopen("dataset_config.json")asf:try:ctx=json.load(f)[cfg.DATASET]exceptKeyError:print("Unsupported dataset.")sys.exit()ifcfg.file_sizeisnotNone:ctx["file_size"]=cfg.file_size# get data transformationtransform_data,transform_label=func_module.create_transform(ctx,cfg.k)# set modelmodel_gen=ppsci.arch.VelocityGenerator(**cfg.MODEL.gen_net)# set valid_dataloader_cfgvalid_dataloader_cfg={"dataset":{"name":"FWIDataset","input_keys":("data",),"label_keys":("real_image",),"anno":cfg.EVAL.dataset.anno,"preload":cfg.EVAL.dataset.preload,"sample_ratio":cfg.EVAL.dataset.sample_ratio,"file_size":ctx["file_size"],"transform_data":transform_data,"transform_label":transform_label,},"batch_size":cfg.EVAL.batch_size,"use_shared_memory":cfg.EVAL.use_shared_memory,"num_workers":cfg.EVAL.num_workers,}# set validatorvalidator=ppsci.validate.SupervisedValidator(dataloader_cfg=valid_dataloader_cfg,loss=ppsci.loss.MAELoss("mean"),output_expr={"real_image":lambdaout:out["fake_image"]},metric={"MAE":ppsci.metric.MAE(),"RMSE":ppsci.metric.RMSE(),"SSIM":ppsci.metric.FunctionalMetric(func_module.ssim_metirc),},name="val",)validator_dict={validator.name:validator}# initialize solversolver=ppsci.solver.Solver(model=model_gen,validator=validator_dict,pretrained_model_path=cfg.EVAL.pretrained_model_path,)# evaluationsolver.eval()# visualizationifcfg.VIS.vis:withsolver.no_grad_context_manager(True):forbatch_idx,(input_,label_,_)inenumerate(validator.data_loader):ifbatch_idx+1>cfg.VIS.vb:breakfake_image=model_gen(input_)["fake_image"].numpy()real_image=label_["real_image"].numpy()foriinrange(cfg.VIS.vsa):plot_velocity(fake_image[i,0],real_image[i,0],f"{cfg.output_dir}/V_{batch_idx}_{i}.png",)print(f"The visualizations are saved to {cfg.output_dir}")deftrain(cfg:DictConfig):# get dataset configuration informationwithopen(cfg.DATASET_CONFIG)asf:try:ctx=json.load(f)[cfg.DATASET]exceptKeyError:print("Unsupported dataset.")sys.exit()ifcfg.file_sizeisnotNone:ctx["file_size"]=cfg.file_size# get data transformationtransform_data,transform_label=func_module.create_transform(ctx,cfg.k)# set modelmodel_gen=ppsci.arch.VelocityGenerator(**cfg.MODEL.gen_net)model_dis=ppsci.arch.VelocityDiscriminator(**cfg.MODEL.dis_net)# set class for loss functiongen_funcs=func_module.GenFuncs(model_dis,cfg.WEIGHT_DICT.gen)dis_funcs=func_module.DisFuncs(model_dis,cfg.WEIGHT_DICT.dis)# set dataloader configdataloader_cfg={"dataset":{"name":"FWIDataset","input_keys":("data",),"label_keys":("real_image",),"anno":cfg.TRAIN.dataset.anno,"preload":cfg.TRAIN.dataset.preload,"sample_ratio":cfg.TRAIN.dataset.sample_ratio,"file_size":ctx["file_size"],"transform_data":transform_data,"transform_label":transform_label,},"sampler":{"name":"BatchSampler","shuffle":cfg.TRAIN.sampler.shuffle,"drop_last":cfg.TRAIN.sampler.drop_last,},"batch_size":cfg.TRAIN.batch_size,"use_shared_memory":cfg.TRAIN.use_shared_memory,"num_workers":cfg.TRAIN.num_workers,}# set constraintconstraint_gen=ppsci.constraint.SupervisedConstraint(dataloader_cfg=dataloader_cfg,loss=ppsci.loss.FunctionalLoss(gen_funcs.loss_func_gen),output_expr={"fake_image":lambdaout:out["fake_image"]},name="cst_gen",)constraint_gen_dict={constraint_gen.name:constraint_gen}constraint_dis=ppsci.constraint.SupervisedConstraint(dataloader_cfg=dataloader_cfg,loss=ppsci.loss.FunctionalLoss(dis_funcs.loss_func_dis),output_expr={"fake_image":lambdaout:out["fake_image"]},name="cst_dis",)constraint_dis_dict={constraint_dis.name:constraint_dis}# set optimizeroptimizer=ppsci.optimizer.AdamW(learning_rate=cfg.TRAIN.learning_rate,weight_decay=cfg.TRAIN.weight_decay)optimizer_g=optimizer(model_gen)optimizer_d=optimizer(model_dis)# initialize solversolver_gen=ppsci.solver.Solver(model=model_gen,output_dir=cfg.output_dir,constraint=constraint_gen_dict,optimizer=optimizer_g,epochs=cfg.TRAIN.epochs_gen,iters_per_epoch=cfg.TRAIN.iters_per_epoch_gen,)solver_dis=ppsci.solver.Solver(model=model_gen,output_dir=cfg.output_dir,constraint=constraint_dis_dict,optimizer=optimizer_d,epochs=cfg.TRAIN.epochs_dis,iters_per_epoch=cfg.TRAIN.iters_per_epoch_dis,)# trainingforiinrange(cfg.TRAIN.epochs):logger.message(f"\nEpoch: {i+1}\n")solver_dis.train()solver_gen.train()# save model weightpaddle.save(model_gen.state_dict(),os.path.join(cfg.output_dir,"model_gen.pdparams"))@hydra.main(version_base=None,config_path="./conf",config_name="velocityGAN.yaml")defmain(cfg:DictConfig):ifcfg.mode=="train":train(cfg)elifcfg.mode=="eval":evaluate(cfg)else:raiseValueError(f"cfg.mode should in ['train', 'eval'], but got '{cfg.mode}'")if__name__=="__main__":main()