# ICAR-ENSO data model trainingpythonearthformer_enso_train.py
# SEVIR data model trainingpythonearthformer_sevir_train.py
# ICAR-ENSO model evaluationpythonearthformer_enso_train.pymode=evalEVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/earthformer/earthformer_enso.pdparams
# SEVIR model evaluationpythonearthformer_sevir_train.pymode=evalEVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/earthformer/earthformer_sevir.pdparams
# ICAR-ENSO model inferencepythonearthformer_enso_train.pymode=export# SEVIR model inferencepythonearthformer_sevir_train.pymode=export
# ICAR-ENSO model inferencepythonearthformer_enso_train.pymode=infer
# SEVIR model inferencepythonearthformer_sevir_train.pymode=infer
The Earth is a complex system. Variations in the Earth system, ranging from routine events like temperature fluctuations to extreme events like droughts, hail, and El Niño/Southern Oscillation (ENSO), affect our daily lives. Among all consequences, Earth system changes affect crop yields, flight delays, trigger floods and forest fires. Accurate and timely forecasting of these changes can help people take necessary precautions to avoid crises or make better use of natural resources such as wind and solar energy. Therefore, improving prediction models for Earth changes (such as weather and climate) has huge socio-economic impact.
Earthformer, a space-time transformer for Earth system forecasting. To better explore the design of space-time attention, the paper proposes Cuboid Attention, a generic building block for efficient space-time attention. The idea is to decompose the input tensor into non-overlapping cuboids and apply cuboid-level self-attention in parallel. Since we restrict the O(N2) self-attention to local cuboids, the overall complexity is greatly reduced. Different types of correlations can be captured by different cuboid decompositions. At the same time, the paper introduces a set of global vectors that attend to all local cuboids, thereby gathering the overall state of the system. By attending to global vectors, local cuboids can grasp the overall dynamics of the system and share information with each other.
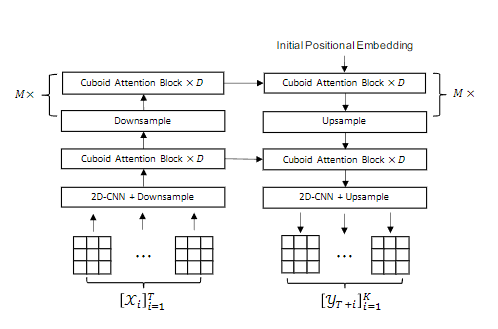
The Earthformer network model uses a hierarchical Transformer encoder-decoder based on Cuboid Attention. The idea is to decompose data into cuboids and apply cuboid-level self-attention in parallel. These cuboids are further connected to a collection of global vectors.
The overall structure of the model is shown in the figure:
EarthFormer Network Model
The original EarthFormer code trained estimation models for sea surface temperature (sst) in the ICAR-ENSO dataset and vertically integrated liquid (vil) in the SEVIR dataset. Next, the training and inference processes of these two models will be introduced.
2.1 Training and Inference Process of ICAR-ENSO and SEVIR Models¶
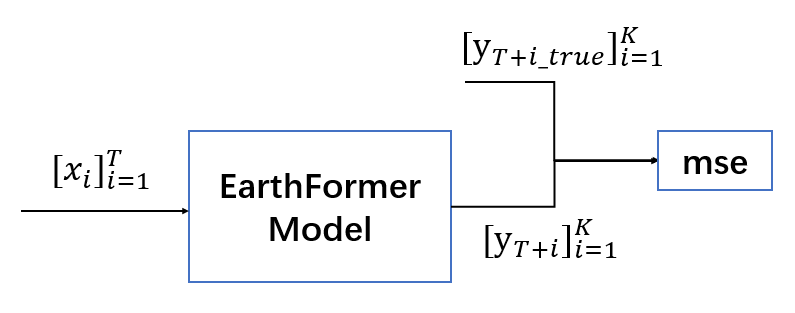
The model pre-training phase trains the model based on randomly initialized network weights, as shown in the figure below, where \([x_{i}]_{i=1}^{T}\) represents input meteorological data of a spatiotemporal sequence of length \(T\), \([y_{T+i}]_{i=1}^{K}\) represents predicted meteorological data for future \(K\) steps, and \([y_{T+i_true}]_{i=1}^{K}\) represents true data for future \(K\) steps, such as sea surface temperature data and vertically integrated liquid data. Finally, the mse loss function is calculated for the network model prediction output and the ground truth.
earthformer model pretraining
In the inference phase, given data of sequence length \(T\), obtain prediction results of sequence length \(K\).
earthformer model inference
3. Implementation of Sea Surface Temperature Model¶
Next, we will explain how to implement EarthFormer model training and inference based on PaddleScience code. For other details in this case, please refer to API Documentation.
The dataset uses the ICAR-ENSO dataset processed by EarthFormer.
This dataset is provided by the Institute for Climate and Application Research (ICAR). The data includes historical simulation data from CMIP5/6 models and nearly 100 years of historical observation assimilation data reconstructed by the US SODA model. Each sample contains the following meteorological and spatiotemporal variables: Sea Surface Temperature anomaly (SST), Heat Content anomaly (T300), Zonal Wind anomaly (Ua), Meridional Wind anomaly (Va), data dimension is (year, month, lat, lon). Training data provides Nino3.4 index label data for the corresponding month. The initial field data used for testing are n segments of 12 time series randomly extracted from multiple international ocean data assimilation results, and the data format is saved in NPY format.
Training Data:
The first dimension (year) of each data sample represents the starting year corresponding to the data. For CMIP data, there are a total of 291 years, of which 1-2265 are 151 years of historical simulation data provided by 15 models in CMIP6 (Total: 151 years * 15 models = 2265); 2266-4645 are 140 years of historical simulation data provided by 17 models in CMIP5 (Total: 140 years * 17 models = 2380). For historical observation assimilation data, it is SODA data provided by the United States.
Training Data Label
The label data is the Nino3.4 SST anomaly index, data dimension is (year, month).
The label data corresponding to CMIP(SODA)_train.nc is the three-month moving average of the Nino3.4 SST anomaly index at the current moment, so the data dimension and dimension introduction are consistent with the training data.
Note: The three-month moving average is the average of the current month and the next two months.
Test Data
The initial field (input) data used for testing are n segments of 12 time series randomly extracted from multiple international ocean data assimilation results. The data format is saved in NPY format, with dimensions (12, lat, lon, 4), 12 is time t and past 11 moments, 4 are predictors, stored in the order of SST, T300, Ua, Va.
In the training of the EarthFormer model for the ICAR-ENSO dataset, only Sea Surface Temperature (SST) is trained and predicted. Training SST anomaly observations for 12 steps (one year), predicting SST anomalies for up to 14 steps.
This case solves the problem based on data-driven methods, so it is necessary to use SupervisedConstraint built in PaddleScience to construct supervised constraints. Before defining constraints, you need to first specify various parameters used for data loading in supervised constraints.
Among them, the "dataset" field defines the Dataset class name used as ENSODataset, the "sampler" field defines the Sampler class name used as BatchSampler, batch_size is set to 16, and num_works is 8.
The code for defining supervised constraints is as follows:
# set constraintsup_constraint=ppsci.constraint.SupervisedConstraint(train_dataloader_cfg,loss=ppsci.loss.FunctionalLoss(enso_metric.train_mse_func),name="Sup",)constraint={sup_constraint.name:sup_constraint}
The first parameter of SupervisedConstraint is the data loading method, here train_dataloader_cfg defined above is used;
The second parameter is the definition of loss function, here the custom loss function mse_loss is used;
The third parameter is the name of the constraint condition, which is convenient for subsequent indexing. Here it is named Sup.
In this case, the sea surface temperature model is implemented based on the CuboidTransformer network model, expressed in PaddleScience code as follows:
# model settingsMODEL:input_keys:["sst_data"]output_keys:["sst_target","nino_target"]input_shape:[12,24,48,1]target_shape:[14,24,48,1]base_units:64scale_alpha:1.0enc_depth:[1,1]dec_depth:[1,1]enc_use_inter_ffn:truedec_use_inter_ffn:truedec_hierarchical_pos_embed:falsedownsample:2downsample_type:"patch_merge"upsample_type:"upsample"num_global_vectors:0use_dec_self_global:falsedec_self_update_global:trueuse_dec_cross_global:falseuse_global_vector_ffn:falseuse_global_self_attn:falseseparate_global_qkv:falseglobal_dim_ratio:1self_pattern:"axial"cross_self_pattern:"axial"cross_pattern:"cross_1x1"dec_cross_last_n_frames:nullattn_drop:0.1proj_drop:0.1ffn_drop:0.1num_heads:4ffn_activation:"gelu"gated_ffn:falsenorm_layer:"layer_norm"padding_type:"zeros"pos_embed_type:"t+h+w"use_relative_pos:trueself_attn_use_final_proj:truedec_use_first_self_attn:falsez_init_method:"zeros"initial_downsample_type:"conv"initial_downsample_activation:"leaky_relu"initial_downsample_scale:[1,1,2]initial_downsample_conv_layers:2final_upsample_conv_layers:1checkpoint_level:2attn_linear_init_mode:"0"ffn_linear_init_mode:"0"conv_init_mode:"0"down_up_linear_init_mode:"0"
Among them, input_keys and output_keys represent the names of input and output variables of the network model respectively.
The learning rate method used in this case is Cosine, and the learning rate size is set to 2e-4. The optimizer uses AdamW, and groups parameters to use different weight_decay, expressed in PaddleScience code as follows:
decay_parameters=get_parameter_names(model,[nn.LayerNorm])decay_parameters=[namefornameindecay_parametersif"bias"notinname]optimizer_grouped_parameters=[{"params":[pforn,pinmodel.named_parameters()ifnindecay_parameters],"weight_decay":cfg.TRAIN.wd,},{"params":[pforn,pinmodel.named_parameters()ifnnotindecay_parameters],"weight_decay":0.0,},]# # init optimizer and lr schedulerlr_scheduler_cfg=dict(cfg.TRAIN.lr_scheduler)lr_scheduler=ppsci.optimizer.lr_scheduler.Cosine(**lr_scheduler_cfg,iters_per_epoch=ITERS_PER_EPOCH,eta_min=cfg.TRAIN.min_lr_ratio*cfg.TRAIN.lr_scheduler.learning_rate,warmup_epoch=int(0.2*cfg.TRAIN.epochs),)()optimizer=paddle.optimizer.AdamW(lr_scheduler,parameters=optimizer_grouped_parameters)
During the training process of this case, the training status of the current model will be evaluated using the validation set at certain training round intervals, and SupervisedValidator is needed to construct the validator. The code is as follows:
# set eval dataloader configeval_dataloader_cfg={"dataset":{"name":"ENSODataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"in_len":cfg.DATASET.in_len,"out_len":cfg.DATASET.out_len,"in_stride":cfg.DATASET.in_stride,"out_stride":cfg.DATASET.out_stride,"train_samples_gap":cfg.DATASET.train_samples_gap,"eval_samples_gap":cfg.DATASET.eval_samples_gap,"normalize_sst":cfg.DATASET.normalize_sst,"training":"eval",},"batch_size":cfg.EVAL.batch_size,}sup_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,loss=ppsci.loss.FunctionalLoss(enso_metric.train_mse_func),metric={"rmse":ppsci.metric.FunctionalMetric(enso_metric.eval_rmse_func),},name="Sup_Validator",)validator={sup_validator.name:sup_validator}
The SupervisedValidator validator is quite similar to SupervisedConstraint, the difference is that the validator needs to set evaluation metric metric, here custom evaluation metrics MAE, MSE, RMSE, corr_nino3.4_epoch and corr_nino3.4_weighted_epoch are used.
# set eval dataloader configeval_dataloader_cfg={"dataset":{"name":"ENSODataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"in_len":cfg.DATASET.in_len,"out_len":cfg.DATASET.out_len,"in_stride":cfg.DATASET.in_stride,"out_stride":cfg.DATASET.out_stride,"train_samples_gap":cfg.DATASET.train_samples_gap,"eval_samples_gap":cfg.DATASET.eval_samples_gap,"normalize_sst":cfg.DATASET.normalize_sst,"training":"test",},"batch_size":cfg.EVAL.batch_size,}sup_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,loss=ppsci.loss.FunctionalLoss(enso_metric.train_mse_func),metric={"rmse":ppsci.metric.FunctionalMetric(enso_metric.eval_rmse_func),},name="Sup_Validator",)validator={sup_validator.name:sup_validator}
pred_data=predictor.predict(in_seq,cfg.INFER.batch_size)# save predict datasave_path=osp.join(cfg.output_dir,"result_enso_pred.npy")np.save(save_path,pred_data)logger.info(f"Save output to {save_path}")
4. Implementation of Vertically Integrated Liquid (vil) Model¶
The dataset uses the SEVIR dataset processed by EarthFormer.
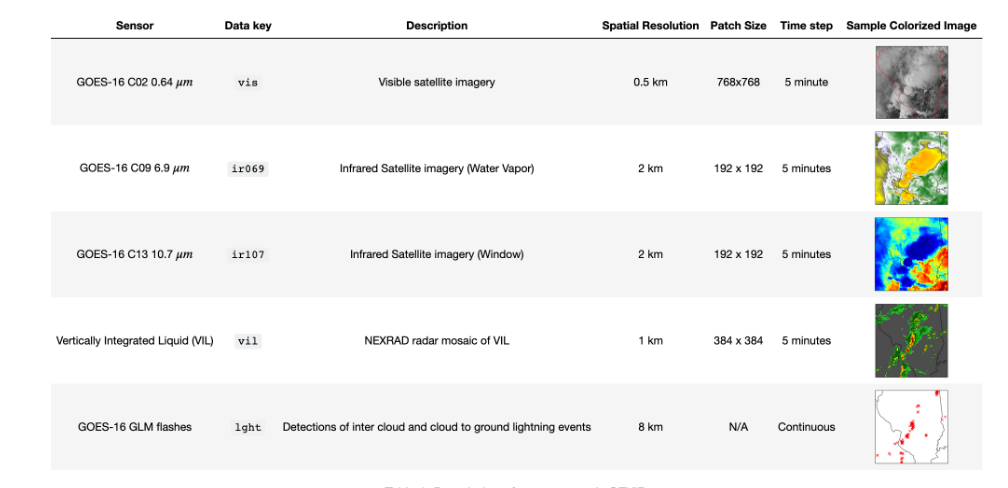
The Storm Event ImagRy (SEVIR) dataset was collected and provided by MIT Lincoln Laboratory and Amazon. SEVIR is an annotated, curated, and spatiotemporally aligned dataset containing over 10,000 weather events, each consisting of a sequence of 384 km x 384 km images spanning 4 hours. Images in SEVIR are sampled and aligned via five different data types: three channels of the GOES-16 Advanced Baseline Imager (C02, C09, C13), NEXRAD Vertically Integrated Liquid (vil), and GOES-16 Geostationary Lightning Mapper (GLM) flashes.
The structure of the SEVIR dataset consists of two parts: Catalog and Data File. The catalog is a CSV file containing rows describing event metadata. Data files are a set of HDF5 files containing events for specific sensor types. Data in these files is stored as 4D tensors with shape N x L x W x T, where N is the number of events in the file, LxW is image size, and T is the number of time steps in the image sequence.
SEVIR Sensor Type Description
EarthFormer uses NEXRAD Vertically Integrated Liquid (VIL) in SEVIR as a benchmark for precipitation forecasting, that is, predicting VIL for the future 60 minutes given a context of 65 minutes of VIL. Therefore, the resolution is 13x384x384→12x384x384.
This case solves the problem based on data-driven methods, so it is necessary to use SupervisedConstraint built in PaddleScience to construct supervised constraints. Before defining constraints, you need to first specify various parameters used for data loading in supervised constraints.
# set train dataloader configtrain_dataloader_cfg={"dataset":{"name":"SEVIRDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"data_types":cfg.DATASET.data_types,"seq_len":cfg.DATASET.seq_len,"raw_seq_len":cfg.DATASET.raw_seq_len,"sample_mode":cfg.DATASET.sample_mode,"stride":cfg.DATASET.stride,"batch_size":cfg.DATASET.batch_size,"layout":cfg.DATASET.layout,"in_len":cfg.DATASET.in_len,"out_len":cfg.DATASET.out_len,"split_mode":cfg.DATASET.split_mode,"start_date":cfg.TRAIN.start_date,"end_date":cfg.TRAIN.end_date,"preprocess":cfg.DATASET.preprocess,"rescale_method":cfg.DATASET.rescale_method,"shuffle":True,"verbose":False,"training":True,},"sampler":{"name":"BatchSampler","drop_last":True,"shuffle":True,},"batch_size":cfg.TRAIN.batch_size,"num_workers":8,}
Among them, the "dataset" field defines the Dataset class name used as ENSODataset, the "sampler" field defines the Sampler class name used as BatchSampler, batch_size is set to 1, and num_works is 8.
The code for defining supervised constraints is as follows:
# set constraintsup_constraint=ppsci.constraint.SupervisedConstraint(train_dataloader_cfg,loss=ppsci.loss.FunctionalLoss(sevir_metric.train_mse_func),name="Sup",)constraint={sup_constraint.name:sup_constraint}
The first parameter of SupervisedConstraint is the data loading method, here train_dataloader_cfg defined above is used;
The second parameter is the definition of loss function, here the custom loss function mse_loss is used;
The third parameter is the name of the constraint condition, which is convenient for subsequent indexing. Here it is named Sup.
In this case, the vertically integrated liquid model is implemented based on the CuboidTransformer network model, expressed in PaddleScience code as follows:
# model settingsMODEL:input_keys:["input"]output_keys:["vil"]input_shape:[13,384,384,1]target_shape:[12,384,384,1]base_units:128scale_alpha:1.0enc_depth:[1,1]dec_depth:[1,1]enc_use_inter_ffn:truedec_use_inter_ffn:truedec_hierarchical_pos_embed:falsedownsample:2downsample_type:"patch_merge"upsample_type:"upsample"num_global_vectors:8use_dec_self_global:falsedec_self_update_global:trueuse_dec_cross_global:falseuse_global_vector_ffn:falseuse_global_self_attn:trueseparate_global_qkv:trueglobal_dim_ratio:1self_pattern:"axial"cross_self_pattern:"axial"cross_pattern:"cross_1x1"dec_cross_last_n_frames:nullattn_drop:0.1proj_drop:0.1ffn_drop:0.1num_heads:4ffn_activation:"gelu"gated_ffn:falsenorm_layer:"layer_norm"padding_type:"zeros"pos_embed_type:"t+h+w"use_relative_pos:trueself_attn_use_final_proj:truedec_use_first_self_attn:falsez_init_method:"zeros"initial_downsample_type:"stack_conv"initial_downsample_activation:"leaky_relu"initial_downsample_stack_conv_num_layers:3initial_downsample_stack_conv_dim_list:[16,64,128]initial_downsample_stack_conv_downscale_list:[3,2,2]initial_downsample_stack_conv_num_conv_list:[2,2,2]checkpoint_level:2attn_linear_init_mode:"0"ffn_linear_init_mode:"0"conv_init_mode:"0"down_up_linear_init_mode:"0"
Among them, input_keys and output_keys represent the names of input and output variables of the network model respectively.
The learning rate method used in this case is Cosine, and the learning rate size is set to 1e-3. The optimizer uses AdamW, and groups parameters to use different weight_decay, expressed in PaddleScience code as follows:
decay_parameters=get_parameter_names(model,[nn.LayerNorm])decay_parameters=[namefornameindecay_parametersif"bias"notinname]optimizer_grouped_parameters=[{"params":[pforn,pinmodel.named_parameters()ifnindecay_parameters],"weight_decay":cfg.TRAIN.wd,},{"params":[pforn,pinmodel.named_parameters()ifnnotindecay_parameters],"weight_decay":0.0,},]# init optimizer and lr schedulerlr_scheduler_cfg=dict(cfg.TRAIN.lr_scheduler)lr_scheduler=ppsci.optimizer.lr_scheduler.Cosine(**lr_scheduler_cfg,iters_per_epoch=ITERS_PER_EPOCH,eta_min=cfg.TRAIN.min_lr_ratio*cfg.TRAIN.lr_scheduler.learning_rate,warmup_epoch=int(0.2*cfg.TRAIN.epochs),)()optimizer=paddle.optimizer.AdamW(lr_scheduler,parameters=optimizer_grouped_parameters)
During the training process of this case, the training status of the current model will be evaluated using the validation set at certain training round intervals, and SupervisedValidator is needed to construct the validator. The code is as follows:
# set eval dataloader configeval_dataloader_cfg={"dataset":{"name":"SEVIRDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"data_types":cfg.DATASET.data_types,"seq_len":cfg.DATASET.seq_len,"raw_seq_len":cfg.DATASET.raw_seq_len,"sample_mode":cfg.DATASET.sample_mode,"stride":cfg.DATASET.stride,"batch_size":cfg.DATASET.batch_size,"layout":cfg.DATASET.layout,"in_len":cfg.DATASET.in_len,"out_len":cfg.DATASET.out_len,"split_mode":cfg.DATASET.split_mode,"start_date":cfg.TRAIN.end_date,"end_date":cfg.EVAL.end_date,"preprocess":cfg.DATASET.preprocess,"rescale_method":cfg.DATASET.rescale_method,"shuffle":False,"verbose":False,"training":False,},"batch_size":cfg.EVAL.batch_size,}sup_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,loss=ppsci.loss.MSELoss(),metric={"rmse":ppsci.metric.FunctionalMetric(sevir_metric.eval_rmse_func(out_len=cfg.DATASET.seq_len,layout=cfg.DATASET.layout,metrics_mode=cfg.EVAL.metrics_mode,metrics_list=cfg.EVAL.metrics_list,threshold_list=cfg.EVAL.threshold_list,)),},name="Sup_Validator",)validator={sup_validator.name:sup_validator}
The SupervisedValidator validator is quite similar to SupervisedConstraint, the difference is that the validator needs to set evaluation metric metric, here custom evaluation metrics MAE, MSE, csi, pod, sucr and bias are used, and the last four evaluation metrics use different thresholds [16,74,133,160,181,219] respectively.
Since the validation strategy in paddlescience is currently divided into two categories, one is to directly concatenate model outputs for the validation dataset and then calculate evaluation metrics. The other is to calculate evaluation metrics for each batch_size, then concatenate, and finally average all results. This method assumes that there is no correlation between data. However, there is correlation between data in the SEVIR dataset, so the second method is not applicable; and because the SEVIR dataset is large, using the first method for validation requires large video memory, so the method used to validate the SEVIR dataset is as follows:
Calculate hits, misses and fas three data for a batch size
Save the cumulative sum of the three values of all batch for all data in the dataset.
Calculate csi, pod, sucr and bias four indicators for the cumulative sum of the three values.
# evaluate after finished trainingmetric=sevir_metric.eval_rmse_func(out_len=cfg.DATASET.seq_len,layout=cfg.DATASET.layout,metrics_mode=cfg.EVAL.metrics_mode,metrics_list=cfg.EVAL.metrics_list,threshold_list=cfg.EVAL.threshold_list,)withsolver.no_grad_context_manager(True):forindex,(input_,label,_)inenumerate(sup_validator.data_loader):truefield=label["vil"].squeeze(0)prefield=model(input_)["vil"].squeeze(0)metric.sevir_score.update(prefield,truefield)metric_dict=metric.sevir_score.compute()print(metric_dict)
# set eval dataloader configeval_dataloader_cfg={"dataset":{"name":"SEVIRDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"data_types":cfg.DATASET.data_types,"seq_len":cfg.DATASET.seq_len,"raw_seq_len":cfg.DATASET.raw_seq_len,"sample_mode":cfg.DATASET.sample_mode,"stride":cfg.DATASET.stride,"batch_size":cfg.DATASET.batch_size,"layout":cfg.DATASET.layout,"in_len":cfg.DATASET.in_len,"out_len":cfg.DATASET.out_len,"split_mode":cfg.DATASET.split_mode,"start_date":cfg.TEST.start_date,"end_date":cfg.TEST.end_date,"preprocess":cfg.DATASET.preprocess,"rescale_method":cfg.DATASET.rescale_method,"shuffle":False,"verbose":False,"training":False,},"batch_size":cfg.EVAL.batch_size,}sup_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,loss=ppsci.loss.MSELoss(),metric={"rmse":ppsci.metric.FunctionalMetric(sevir_metric.eval_rmse_func(out_len=cfg.DATASET.seq_len,layout=cfg.DATASET.layout,metrics_mode=cfg.EVAL.metrics_mode,metrics_list=cfg.EVAL.metrics_list,threshold_list=cfg.EVAL.threshold_list,)),},name="Sup_Validator",)validator={sup_validator.name:sup_validator}
fromosimportpathasospimportenso_metricasenso_metricimporthydraimportnumpyasnpimportpaddlefromomegaconfimportDictConfigfrompaddleimportnnimportppscifromppsci.data.datasetimportenso_datasetfromppsci.utilsimportloggertry:importxarrayasxrexceptModuleNotFoundError:raiseModuleNotFoundError("Please install xarray with `pip install xarray`.")defget_parameter_names(model,forbidden_layer_types):result=[]forname,childinmodel.named_children():result+=[f"{name}.{n}"forninget_parameter_names(child,forbidden_layer_types)ifnotisinstance(child,tuple(forbidden_layer_types))]# Add model specific parameters (defined with nn.Parameter) since they are not in any child.result+=list(model._parameters.keys())returnresultdeftrain(cfg:DictConfig):# set train dataloader configtrain_dataloader_cfg={"dataset":{"name":"ENSODataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"in_len":cfg.DATASET.in_len,"out_len":cfg.DATASET.out_len,"in_stride":cfg.DATASET.in_stride,"out_stride":cfg.DATASET.out_stride,"train_samples_gap":cfg.DATASET.train_samples_gap,"eval_samples_gap":cfg.DATASET.eval_samples_gap,"normalize_sst":cfg.DATASET.normalize_sst,},"sampler":{"name":"BatchSampler","drop_last":True,"shuffle":True,},"batch_size":cfg.TRAIN.batch_size,"num_workers":8,}# set constraintsup_constraint=ppsci.constraint.SupervisedConstraint(train_dataloader_cfg,loss=ppsci.loss.FunctionalLoss(enso_metric.train_mse_func),name="Sup",)constraint={sup_constraint.name:sup_constraint}# set iters_per_epoch by dataloader lengthITERS_PER_EPOCH=len(sup_constraint.data_loader)# set eval dataloader configeval_dataloader_cfg={"dataset":{"name":"ENSODataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"in_len":cfg.DATASET.in_len,"out_len":cfg.DATASET.out_len,"in_stride":cfg.DATASET.in_stride,"out_stride":cfg.DATASET.out_stride,"train_samples_gap":cfg.DATASET.train_samples_gap,"eval_samples_gap":cfg.DATASET.eval_samples_gap,"normalize_sst":cfg.DATASET.normalize_sst,"training":"eval",},"batch_size":cfg.EVAL.batch_size,}sup_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,loss=ppsci.loss.FunctionalLoss(enso_metric.train_mse_func),metric={"rmse":ppsci.metric.FunctionalMetric(enso_metric.eval_rmse_func),},name="Sup_Validator",)validator={sup_validator.name:sup_validator}model=ppsci.arch.CuboidTransformer(**cfg.MODEL,)decay_parameters=get_parameter_names(model,[nn.LayerNorm])decay_parameters=[namefornameindecay_parametersif"bias"notinname]optimizer_grouped_parameters=[{"params":[pforn,pinmodel.named_parameters()ifnindecay_parameters],"weight_decay":cfg.TRAIN.wd,},{"params":[pforn,pinmodel.named_parameters()ifnnotindecay_parameters],"weight_decay":0.0,},]# # init optimizer and lr schedulerlr_scheduler_cfg=dict(cfg.TRAIN.lr_scheduler)lr_scheduler=ppsci.optimizer.lr_scheduler.Cosine(**lr_scheduler_cfg,iters_per_epoch=ITERS_PER_EPOCH,eta_min=cfg.TRAIN.min_lr_ratio*cfg.TRAIN.lr_scheduler.learning_rate,warmup_epoch=int(0.2*cfg.TRAIN.epochs),)()optimizer=paddle.optimizer.AdamW(lr_scheduler,parameters=optimizer_grouped_parameters)# initialize solversolver=ppsci.solver.Solver(model,constraint,cfg.output_dir,optimizer,lr_scheduler,cfg.TRAIN.epochs,ITERS_PER_EPOCH,eval_during_train=cfg.TRAIN.eval_during_train,seed=cfg.seed,validator=validator,compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,eval_with_no_grad=cfg.EVAL.eval_with_no_grad,)# train modelsolver.train()# evaluate after finished trainingsolver.eval()defevaluate(cfg:DictConfig):# set eval dataloader configeval_dataloader_cfg={"dataset":{"name":"ENSODataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"in_len":cfg.DATASET.in_len,"out_len":cfg.DATASET.out_len,"in_stride":cfg.DATASET.in_stride,"out_stride":cfg.DATASET.out_stride,"train_samples_gap":cfg.DATASET.train_samples_gap,"eval_samples_gap":cfg.DATASET.eval_samples_gap,"normalize_sst":cfg.DATASET.normalize_sst,"training":"test",},"batch_size":cfg.EVAL.batch_size,}sup_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,loss=ppsci.loss.FunctionalLoss(enso_metric.train_mse_func),metric={"rmse":ppsci.metric.FunctionalMetric(enso_metric.eval_rmse_func),},name="Sup_Validator",)validator={sup_validator.name:sup_validator}model=ppsci.arch.CuboidTransformer(**cfg.MODEL,)# initialize solversolver=ppsci.solver.Solver(model,output_dir=cfg.output_dir,log_freq=cfg.log_freq,seed=cfg.seed,validator=validator,pretrained_model_path=cfg.EVAL.pretrained_model_path,compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,eval_with_no_grad=cfg.EVAL.eval_with_no_grad,)# evaluatesolver.eval()defexport(cfg:DictConfig):# set modelmodel=ppsci.arch.CuboidTransformer(**cfg.MODEL,)# initialize solversolver=ppsci.solver.Solver(model,pretrained_model_path=cfg.INFER.pretrained_model_path,)# export modelfrompaddle.staticimportInputSpecinput_spec=[{key:InputSpec([1,12,24,48,1],"float32",name=key)forkeyinmodel.input_keys},]solver.export(input_spec,cfg.INFER.export_path)definference(cfg:DictConfig):importpredictorpredictor=predictor.EarthformerPredictor(cfg)train_cmip=xr.open_dataset(cfg.INFER.data_path).transpose("year","month","lat","lon")# select longitudeslon=train_cmip.lon.valueslon=lon[np.logical_and(lon>=95,lon<=330)]train_cmip=train_cmip.sel(lon=lon)data=train_cmip.sst.valuesdata=enso_dataset.fold(data)idx_sst=enso_dataset.prepare_inputs_targets(len_time=data.shape[0],input_length=cfg.INFER.in_len,input_gap=cfg.INFER.in_stride,pred_shift=cfg.INFER.out_len*cfg.INFER.out_stride,pred_length=cfg.INFER.out_len,samples_gap=cfg.INFER.samples_gap,)data=data[idx_sst].astype("float32")sst_data=data[...,np.newaxis]idx=np.random.choice(len(data),None,False)in_seq=sst_data[idx,:cfg.INFER.in_len,...]# ( in_len, lat, lon, 1)in_seq=in_seq[np.newaxis,...]target_seq=sst_data[idx,cfg.INFER.in_len:,...]# ( out_len, lat, lon, 1)target_seq=target_seq[np.newaxis,...]pred_data=predictor.predict(in_seq,cfg.INFER.batch_size)# save predict datasave_path=osp.join(cfg.output_dir,"result_enso_pred.npy")np.save(save_path,pred_data)logger.info(f"Save output to {save_path}")@hydra.main(version_base=None,config_path="./conf",config_name="earthformer_enso_pretrain.yaml",)defmain(cfg:DictConfig):ifcfg.mode=="train":train(cfg)elifcfg.mode=="eval":evaluate(cfg)elifcfg.mode=="export":export(cfg)elifcfg.mode=="infer":inference(cfg)else:raiseValueError(f"cfg.mode should in ['train', 'eval', 'export', 'infer'], but got '{cfg.mode}'")if__name__=="__main__":main()
importh5pyimporthydraimportnumpyasnpimportpaddleimportsevir_metricimportsevir_vis_seqfromomegaconfimportDictConfigfrompaddleimportnnimportppscidefget_parameter_names(model,forbidden_layer_types):result=[]forname,childinmodel.named_children():result+=[f"{name}.{n}"forninget_parameter_names(child,forbidden_layer_types)ifnotisinstance(child,tuple(forbidden_layer_types))]# Add model specific parameters (defined with nn.Parameter) since they are not in any child.result+=list(model._parameters.keys())returnresultdeftrain(cfg:DictConfig):# set train dataloader configtrain_dataloader_cfg={"dataset":{"name":"SEVIRDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"data_types":cfg.DATASET.data_types,"seq_len":cfg.DATASET.seq_len,"raw_seq_len":cfg.DATASET.raw_seq_len,"sample_mode":cfg.DATASET.sample_mode,"stride":cfg.DATASET.stride,"batch_size":cfg.DATASET.batch_size,"layout":cfg.DATASET.layout,"in_len":cfg.DATASET.in_len,"out_len":cfg.DATASET.out_len,"split_mode":cfg.DATASET.split_mode,"start_date":cfg.TRAIN.start_date,"end_date":cfg.TRAIN.end_date,"preprocess":cfg.DATASET.preprocess,"rescale_method":cfg.DATASET.rescale_method,"shuffle":True,"verbose":False,"training":True,},"sampler":{"name":"BatchSampler","drop_last":True,"shuffle":True,},"batch_size":cfg.TRAIN.batch_size,"num_workers":8,}# set constraintsup_constraint=ppsci.constraint.SupervisedConstraint(train_dataloader_cfg,loss=ppsci.loss.FunctionalLoss(sevir_metric.train_mse_func),name="Sup",)constraint={sup_constraint.name:sup_constraint}# set iters_per_epoch by dataloader lengthITERS_PER_EPOCH=len(sup_constraint.data_loader)# set eval dataloader configeval_dataloader_cfg={"dataset":{"name":"SEVIRDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"data_types":cfg.DATASET.data_types,"seq_len":cfg.DATASET.seq_len,"raw_seq_len":cfg.DATASET.raw_seq_len,"sample_mode":cfg.DATASET.sample_mode,"stride":cfg.DATASET.stride,"batch_size":cfg.DATASET.batch_size,"layout":cfg.DATASET.layout,"in_len":cfg.DATASET.in_len,"out_len":cfg.DATASET.out_len,"split_mode":cfg.DATASET.split_mode,"start_date":cfg.TRAIN.end_date,"end_date":cfg.EVAL.end_date,"preprocess":cfg.DATASET.preprocess,"rescale_method":cfg.DATASET.rescale_method,"shuffle":False,"verbose":False,"training":False,},"batch_size":cfg.EVAL.batch_size,}sup_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,loss=ppsci.loss.MSELoss(),metric={"rmse":ppsci.metric.FunctionalMetric(sevir_metric.eval_rmse_func(out_len=cfg.DATASET.seq_len,layout=cfg.DATASET.layout,metrics_mode=cfg.EVAL.metrics_mode,metrics_list=cfg.EVAL.metrics_list,threshold_list=cfg.EVAL.threshold_list,)),},name="Sup_Validator",)validator={sup_validator.name:sup_validator}model=ppsci.arch.CuboidTransformer(**cfg.MODEL,)decay_parameters=get_parameter_names(model,[nn.LayerNorm])decay_parameters=[namefornameindecay_parametersif"bias"notinname]optimizer_grouped_parameters=[{"params":[pforn,pinmodel.named_parameters()ifnindecay_parameters],"weight_decay":cfg.TRAIN.wd,},{"params":[pforn,pinmodel.named_parameters()ifnnotindecay_parameters],"weight_decay":0.0,},]# init optimizer and lr schedulerlr_scheduler_cfg=dict(cfg.TRAIN.lr_scheduler)lr_scheduler=ppsci.optimizer.lr_scheduler.Cosine(**lr_scheduler_cfg,iters_per_epoch=ITERS_PER_EPOCH,eta_min=cfg.TRAIN.min_lr_ratio*cfg.TRAIN.lr_scheduler.learning_rate,warmup_epoch=int(0.2*cfg.TRAIN.epochs),)()optimizer=paddle.optimizer.AdamW(lr_scheduler,parameters=optimizer_grouped_parameters)# initialize solversolver=ppsci.solver.Solver(model,constraint,cfg.output_dir,optimizer,lr_scheduler,cfg.TRAIN.epochs,ITERS_PER_EPOCH,eval_during_train=cfg.TRAIN.eval_during_train,seed=cfg.seed,validator=validator,compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,eval_with_no_grad=cfg.EVAL.eval_with_no_grad,)# train modelsolver.train()# evaluate after finished trainingmetric=sevir_metric.eval_rmse_func(out_len=cfg.DATASET.seq_len,layout=cfg.DATASET.layout,metrics_mode=cfg.EVAL.metrics_mode,metrics_list=cfg.EVAL.metrics_list,threshold_list=cfg.EVAL.threshold_list,)withsolver.no_grad_context_manager(True):forindex,(input_,label,_)inenumerate(sup_validator.data_loader):truefield=label["vil"].squeeze(0)prefield=model(input_)["vil"].squeeze(0)metric.sevir_score.update(prefield,truefield)metric_dict=metric.sevir_score.compute()print(metric_dict)defevaluate(cfg:DictConfig):# set eval dataloader configeval_dataloader_cfg={"dataset":{"name":"SEVIRDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"data_types":cfg.DATASET.data_types,"seq_len":cfg.DATASET.seq_len,"raw_seq_len":cfg.DATASET.raw_seq_len,"sample_mode":cfg.DATASET.sample_mode,"stride":cfg.DATASET.stride,"batch_size":cfg.DATASET.batch_size,"layout":cfg.DATASET.layout,"in_len":cfg.DATASET.in_len,"out_len":cfg.DATASET.out_len,"split_mode":cfg.DATASET.split_mode,"start_date":cfg.TEST.start_date,"end_date":cfg.TEST.end_date,"preprocess":cfg.DATASET.preprocess,"rescale_method":cfg.DATASET.rescale_method,"shuffle":False,"verbose":False,"training":False,},"batch_size":cfg.EVAL.batch_size,}sup_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,loss=ppsci.loss.MSELoss(),metric={"rmse":ppsci.metric.FunctionalMetric(sevir_metric.eval_rmse_func(out_len=cfg.DATASET.seq_len,layout=cfg.DATASET.layout,metrics_mode=cfg.EVAL.metrics_mode,metrics_list=cfg.EVAL.metrics_list,threshold_list=cfg.EVAL.threshold_list,)),},name="Sup_Validator",)validator={sup_validator.name:sup_validator}model=ppsci.arch.CuboidTransformer(**cfg.MODEL,)# initialize solversolver=ppsci.solver.Solver(model,output_dir=cfg.output_dir,log_freq=cfg.log_freq,seed=cfg.seed,validator=validator,pretrained_model_path=cfg.EVAL.pretrained_model_path,compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,eval_with_no_grad=cfg.EVAL.eval_with_no_grad,)# evaluatemetric=sevir_metric.eval_rmse_func(out_len=cfg.DATASET.seq_len,layout=cfg.DATASET.layout,metrics_mode=cfg.EVAL.metrics_mode,metrics_list=cfg.EVAL.metrics_list,threshold_list=cfg.EVAL.threshold_list,)withsolver.no_grad_context_manager(True):forindex,(input_,label,_)inenumerate(sup_validator.data_loader):truefield=label["vil"].reshape([-1,*label["vil"].shape[2:]])prefield=model(input_)["vil"].reshape([-1,*label["vil"].shape[2:]])metric.sevir_score.update(prefield,truefield)metric_dict=metric.sevir_score.compute()print(metric_dict)defexport(cfg:DictConfig):# set modelmodel=ppsci.arch.CuboidTransformer(**cfg.MODEL,)# initialize solversolver=ppsci.solver.Solver(model,pretrained_model_path=cfg.INFER.pretrained_model_path,)# export modelfrompaddle.staticimportInputSpecinput_spec=[{key:InputSpec([1,13,384,384,1],"float32",name=key)forkeyinmodel.input_keys},]solver.export(input_spec,cfg.INFER.export_path)definference(cfg:DictConfig):importpredictorfromppsci.data.datasetimportsevir_datasetpredictor=predictor.EarthformerPredictor(cfg)ifcfg.INFER.rescale_method=="sevir":scale_dict=sevir_dataset.PREPROCESS_SCALE_SEVIRoffset_dict=sevir_dataset.PREPROCESS_OFFSET_SEVIRelifcfg.INFER.rescale_method=="01":scale_dict=sevir_dataset.PREPROCESS_SCALE_01offset_dict=sevir_dataset.PREPROCESS_OFFSET_01else:raiseValueError(f"Invalid rescale option: {cfg.INFER.rescale_method}.")# read h5 datah5data=h5py.File(cfg.INFER.data_path,"r")data=np.array(h5data[cfg.INFER.data_type]).transpose([0,3,1,2])idx=np.random.choice(len(data),None,False)data=(scale_dict[cfg.INFER.data_type]*data[idx]+offset_dict[cfg.INFER.data_type])input_data=data[:cfg.INFER.in_len,...]input_data=input_data.reshape(1,*input_data.shape,1).astype(np.float32)target_data=data[cfg.INFER.in_len:cfg.INFER.in_len+cfg.INFER.out_len,...]target_data=target_data.reshape(1,*target_data.shape,1).astype(np.float32)pred_data=predictor.predict(input_data,cfg.INFER.batch_size)sevir_vis_seq.save_example_vis_results(save_dir=cfg.INFER.sevir_vis_save,save_prefix=f"data_{idx}",in_seq=input_data,target_seq=target_data,pred_seq=pred_data,layout=cfg.INFER.layout,plot_stride=cfg.INFER.plot_stride,label=cfg.INFER.logging_prefix,interval_real_time=cfg.INFER.interval_real_time,)@hydra.main(version_base=None,config_path="./conf",config_name="earthformer_sevir_pretrain.yaml",)defmain(cfg:DictConfig):ifcfg.mode=="train":train(cfg)elifcfg.mode=="eval":evaluate(cfg)elifcfg.mode=="export":export(cfg)elifcfg.mode=="infer":inference(cfg)else:raiseValueError(f"cfg.mode should in ['train', 'eval', 'export', 'infer'], but got '{cfg.mode}'")if__name__=="__main__":main()
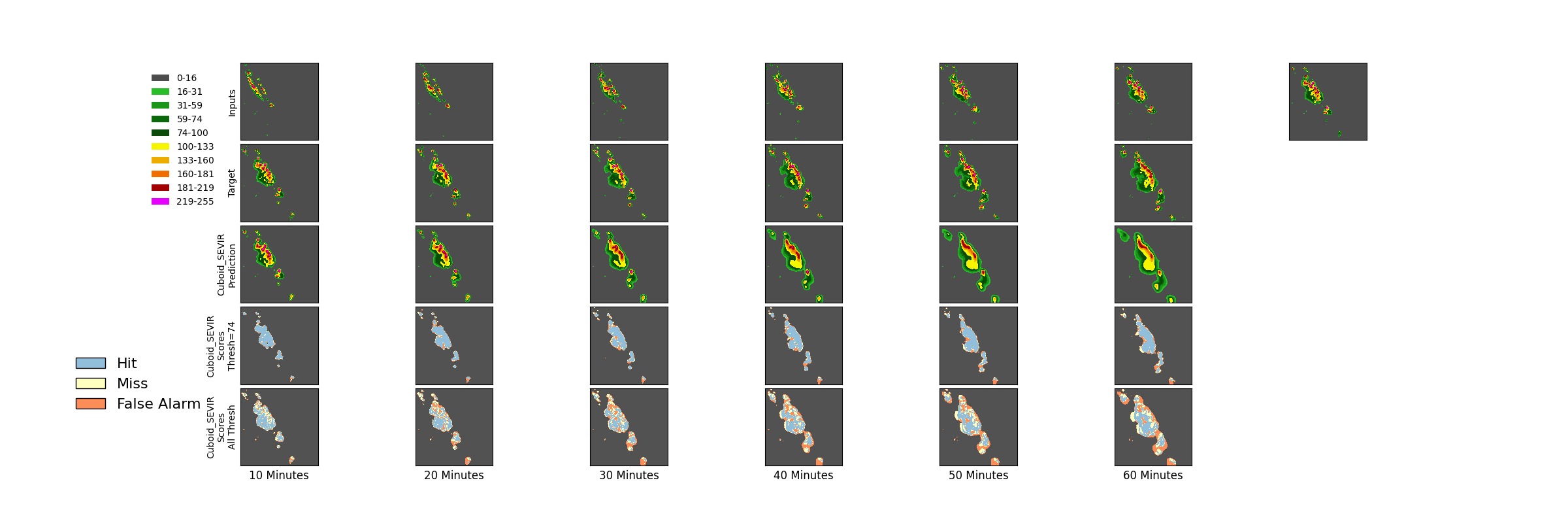
The figure below shows the prediction results and ground truth results of the vertically integrated liquid model obtained at 60-minute intervals based on 65 minutes of input data.
Prediction results ("prediction") vs ground truth ("target") of vil in SEVIR
Description:
Hit:TP, Miss:FN, False Alarm:FP
First row: Input data;
Second row: Ground truth results;
Third row: Prediction results;
Fourth row: TP, FN, FP markers under threshold 74
Fifth row: TP, FN, FP markers under all threshold cases