The Lorenz system, proposed by meteorologist Edward N. Lorenz in 1963, is a seminal model in chaos theory. It famously illustrates the "Butterfly Effect," where small changes in initial conditions can lead to vastly different outcomes—metaphorically, a butterfly flapping its wings in Brazil causing a tornado in Texas.
Mathematically, the Lorenz system describes atmospheric convection using a set of three ordinary differential equations. It exhibits chaotic behavior for certain parameter values, characterized by extreme sensitivity to initial conditions and long-term unpredictability. Due to this sensitivity, the Lorenz system serves as an excellent benchmark for evaluating the precision and stability of machine learning models in capturing complex dynamics.
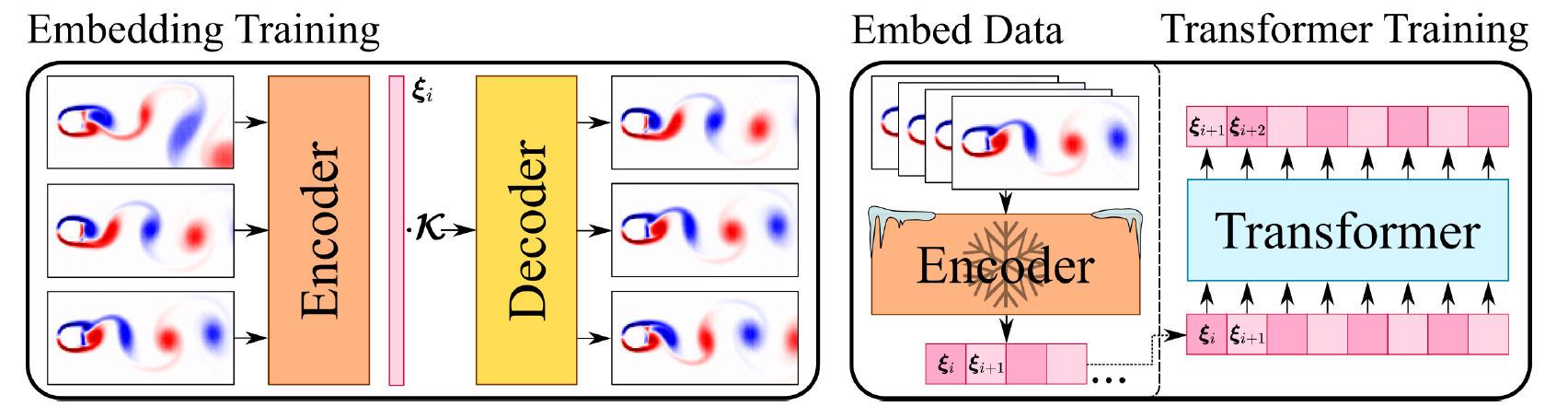
Next, we will explain how to solve this problem using deep learning methods based on PaddleScience code. This case is based on the method of the paper Transformers for Modeling Physical Systems. Next, we will first briefly introduce the theoretical method of this paper, then introduce the dataset used, and finally explain the construction of supervised constraints and model construction for the two training steps of this method (Embedding model training, Transformer model training), while other details please refer to API Documentation.
While Transformers have revolutionized NLP and CV, their application to physical system modeling is relatively new. This example implements the method from Transformers for Modeling Physical Systems, which adapts the Transformer architecture for dynamical systems.
The approach involves two key components:
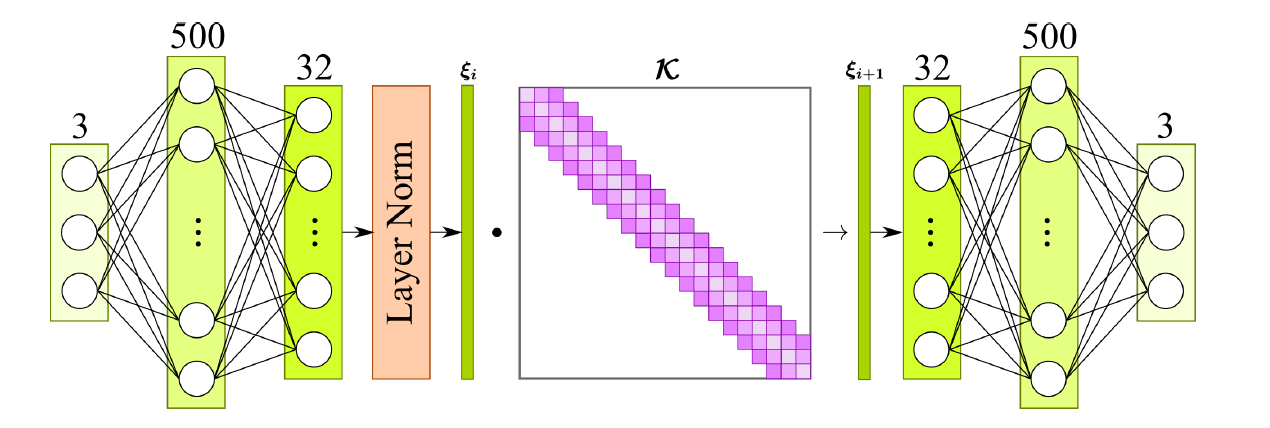
1. Embedding Model: An autoencoder structure.
- Encoder: Maps physical state variables to a latent embedding space.
- Decoder: Reconstructs physical states from the latent vectors.
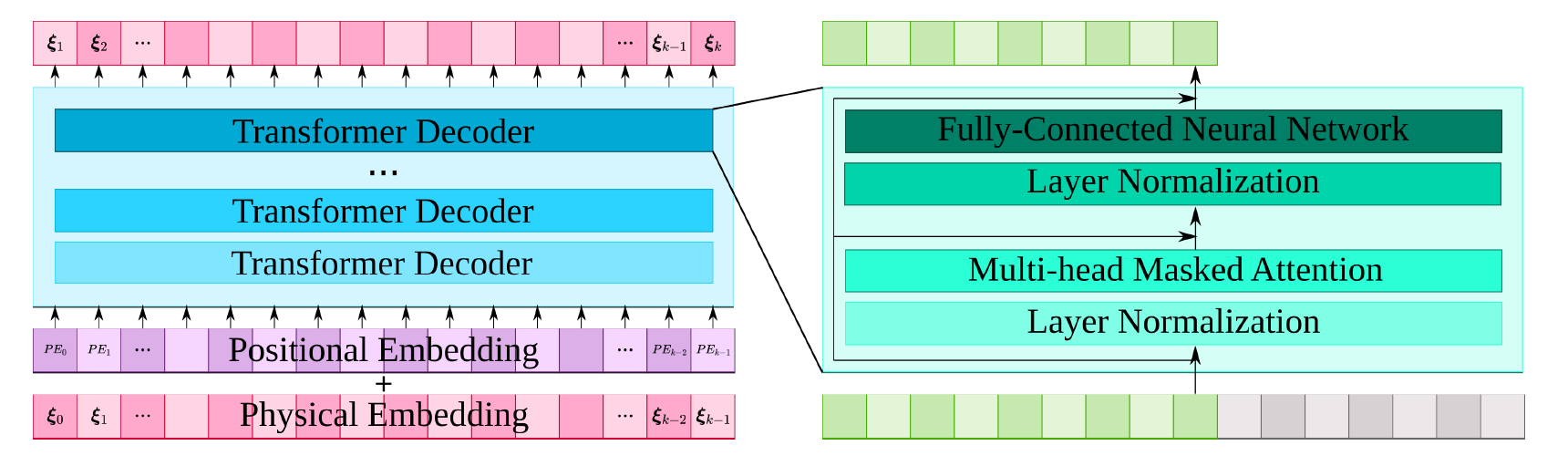
2. Transformer Model: Operates within the latent space. It predicts the future latent state based on the current latent state (output of the Encoder).
Training Strategy:
1. Train the Embedding model to minimize reconstruction error.
2. Freeze the Embedding model and train the Transformer to predict dynamics in the latent space.
The dataset uses data provided in Transformer-Physx. This dataset is obtained using the Runge-Kutta traditional numerical solution method, with a time step size of 0.01, and the initial position is randomly selected from the following range:
output_dir:${hydra:run.dir}TRAIN_BLOCK_SIZE:16VALID_BLOCK_SIZE:32TRAIN_FILE_PATH:./datasets/lorenz_training_rk.hdf5VALID_FILE_PATH:./datasets/lorenz_valid_rk.hdf5# model settingsMODEL:input_keys:["states"]
Among them, the first two parameters of LorenzEmbedding have been described above and will not be repeated here. The third and fourth parameters of the network model are the mean and variance of the training dataset, used to normalize the input data. The code for calculating the mean and variance is expressed as follows:
# init optimizer and lr schedulerclip=paddle.nn.ClipGradByGlobalNorm(clip_norm=0.1)lr_scheduler=ppsci.optimizer.lr_scheduler.ExponentialDecay(iters_per_epoch=ITERS_PER_EPOCH,decay_steps=ITERS_PER_EPOCH,**cfg.TRAIN.lr_scheduler,)()optimizer=ppsci.optimizer.Adam(lr_scheduler,grad_clip=clip,**cfg.TRAIN.optimizer)(model)
During the training process of this case, the training status of the current model will be evaluated using the validation set at certain training round intervals, and SupervisedValidator is needed to construct the validator. The code is as follows:
The SupervisedValidator validator is quite similar to SupervisedConstraint, the difference is that the validator needs to set evaluation metric metric, here ppsci.metric.MSE is used.
Having trained the Embedding model, we now train the Transformer model using the fixed Embedding model. The process is similar, so we focus on the differences.
output_dir:${hydra:run.dir}log_freq:20TRAIN_BLOCK_SIZE:64VALID_BLOCK_SIZE:256TRAIN_FILE_PATH:./datasets/lorenz_training_rk.hdf5VALID_FILE_PATH:./datasets/lorenz_valid_rk.hdf5# set working condition
Note: The Transformer trains on data in the latent (encoding) space. We pass the pre-trained Embedding model to LorenzDataset to map the physical data to the encoding space during initialization.
The code for defining supervised constraints is as follows:
In addition to filling in input_keys and output_keys, the class PhysformerGPT2 also needs to set the number of layers of the Transformer model num_layers, the context size num_ctx, the length of the input Embedding vector embed_size, and the parameter num_heads of the multi-head attention mechanism. The values filled in here are 4, 64, 32, 4.
The learning rate method used in this case is CosineWarmRestarts, and the learning rate size is set to 0.001. The optimizer uses Adam, and gradient clipping uses the ClipGradByGlobalNorm method built in Paddle. Expressed in PaddleScience code as follows:
During the training process, the training status of the current model will be evaluated using the validation set at certain training round intervals, and SupervisedValidator is needed to construct the validator. Expressed in PaddleScience code as follows:
To visualize results, we must map the Transformer's latent output back to physical space using the Decoder. We define an OutputTransform for this purpose:
First, use the dataset in mse_validator above for visualization, and introduce the vis_data_nums variable to control the number of samples to be visualized. Finally, construct the visualizer through VisualizerScatter3D.
3.4.6 Model Training, Evaluation and Visualization¶
After completing the above settings, you only need to pass the instantiated objects to ppsci.solver.Solver, and then start training and evaluation.
# Copyright (c) 2023 PaddlePaddle Authors. All Rights Reserved.## Licensed under the Apache License, Version 2.0 (the "License");# you may not use this file except in compliance with the License.# You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.# Two-stage training# 1. Train a embedding model by running train_enn.py.# 2. Load pretrained embedding model and freeze it, then train a transformer model by running train_transformer.py.# This file is for step1: training a embedding model.# This file is based on PaddleScience/ppsci API.fromosimportpathasospimporthydraimportnumpyasnpimportpaddlefromomegaconfimportDictConfigimportppscifromppsci.utilsimportloggerdefget_mean_std(data:np.ndarray):mean=np.asarray([np.mean(data[:,:,0]),np.mean(data[:,:,1]),np.mean(data[:,:,2])]).reshape(1,3)std=np.asarray([np.std(data[:,:,0]),np.std(data[:,:,1]),np.std(data[:,:,2])]).reshape(1,3)returnmean,stddeftrain(cfg:DictConfig):# set random seed for reproducibilityppsci.utils.misc.set_random_seed(cfg.seed)# initialize loggerlogger.init_logger("ppsci",osp.join(cfg.output_dir,f"{cfg.mode}.log"),"info")weights=(1.0*(cfg.TRAIN_BLOCK_SIZE-1),1.0e4*cfg.TRAIN_BLOCK_SIZE)regularization_key="k_matrix"# manually build constraint(s)train_dataloader_cfg={"dataset":{"name":"LorenzDataset","file_path":cfg.TRAIN_FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.MODEL.output_keys,"block_size":cfg.TRAIN_BLOCK_SIZE,"stride":16,"weight_dict":{key:valueforkey,valueinzip(cfg.MODEL.output_keys,weights)},},"sampler":{"name":"BatchSampler","drop_last":True,"shuffle":True,},"batch_size":cfg.TRAIN.batch_size,"num_workers":4,}sup_constraint=ppsci.constraint.SupervisedConstraint(train_dataloader_cfg,ppsci.loss.MSELossWithL2Decay(regularization_dict={regularization_key:1.0e-1*(cfg.TRAIN_BLOCK_SIZE-1)}),{key:lambdaout,k=key:out[k]forkeyincfg.MODEL.output_keys+(regularization_key,)},name="Sup",)constraint={sup_constraint.name:sup_constraint}# set iters_per_epoch by dataloader lengthITERS_PER_EPOCH=len(sup_constraint.data_loader)# manually init modeldata_mean,data_std=get_mean_std(sup_constraint.data_loader.dataset.data)model=ppsci.arch.LorenzEmbedding(cfg.MODEL.input_keys,cfg.MODEL.output_keys+(regularization_key,),data_mean,data_std,)# init optimizer and lr schedulerclip=paddle.nn.ClipGradByGlobalNorm(clip_norm=0.1)lr_scheduler=ppsci.optimizer.lr_scheduler.ExponentialDecay(iters_per_epoch=ITERS_PER_EPOCH,decay_steps=ITERS_PER_EPOCH,**cfg.TRAIN.lr_scheduler,)()optimizer=ppsci.optimizer.Adam(lr_scheduler,grad_clip=clip,**cfg.TRAIN.optimizer)(model)# manually build validatorweights=(1.0*(cfg.VALID_BLOCK_SIZE-1),1.0e4*cfg.VALID_BLOCK_SIZE)eval_dataloader_cfg={"dataset":{"name":"LorenzDataset","file_path":cfg.VALID_FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.MODEL.output_keys,"block_size":cfg.VALID_BLOCK_SIZE,"stride":32,"weight_dict":{key:valueforkey,valueinzip(cfg.MODEL.output_keys,weights)},},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,"num_workers":4,}mse_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,ppsci.loss.MSELoss(),metric={"MSE":ppsci.metric.MSE()},name="MSE_Validator",)validator={mse_validator.name:mse_validator}# initialize solversolver=ppsci.solver.Solver(model,constraint,cfg.output_dir,optimizer,lr_scheduler,cfg.TRAIN.epochs,ITERS_PER_EPOCH,eval_during_train=True,validator=validator,)# train modelsolver.train()# evaluate after finished trainingsolver.eval()defevaluate(cfg:DictConfig):# set random seed for reproducibilityppsci.utils.misc.set_random_seed(cfg.seed)# initialize loggerlogger.init_logger("ppsci",osp.join(cfg.output_dir,f"{cfg.mode}.log"),"info")weights=(1.0*(cfg.TRAIN_BLOCK_SIZE-1),1.0e4*cfg.TRAIN_BLOCK_SIZE)regularization_key="k_matrix"# manually build constraint(s)train_dataloader_cfg={"dataset":{"name":"LorenzDataset","file_path":cfg.TRAIN_FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.MODEL.output_keys,"block_size":cfg.TRAIN_BLOCK_SIZE,"stride":16,"weight_dict":{key:valueforkey,valueinzip(cfg.MODEL.output_keys,weights)},},"sampler":{"name":"BatchSampler","drop_last":True,"shuffle":True,},"batch_size":cfg.TRAIN.batch_size,"num_workers":4,}sup_constraint=ppsci.constraint.SupervisedConstraint(train_dataloader_cfg,ppsci.loss.MSELossWithL2Decay(regularization_dict={regularization_key:1.0e-1*(cfg.TRAIN_BLOCK_SIZE-1)}),{key:lambdaout,k=key:out[k]forkeyincfg.MODEL.output_keys+(regularization_key,)},name="Sup",)# manually init modeldata_mean,data_std=get_mean_std(sup_constraint.data_loader.dataset.data)model=ppsci.arch.LorenzEmbedding(cfg.MODEL.input_keys,cfg.MODEL.output_keys+(regularization_key,),data_mean,data_std,)# manually build validatorweights=(1.0*(cfg.VALID_BLOCK_SIZE-1),1.0e4*cfg.VALID_BLOCK_SIZE)eval_dataloader_cfg={"dataset":{"name":"LorenzDataset","file_path":cfg.VALID_FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.MODEL.output_keys,"block_size":cfg.VALID_BLOCK_SIZE,"stride":32,"weight_dict":{key:valueforkey,valueinzip(cfg.MODEL.output_keys,weights)},},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,"num_workers":4,}mse_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,ppsci.loss.MSELoss(),metric={"MSE":ppsci.metric.MSE()},name="MSE_Validator",)validator={mse_validator.name:mse_validator}solver=ppsci.solver.Solver(model,output_dir=cfg.output_dir,validator=validator,pretrained_model_path=cfg.EVAL.pretrained_model_path,)solver.eval()@hydra.main(version_base=None,config_path="./conf",config_name="enn.yaml")defmain(cfg:DictConfig):ifcfg.mode=="train":train(cfg)elifcfg.mode=="eval":evaluate(cfg)else:raiseValueError(f"cfg.mode should in ['train', 'eval'], but got '{cfg.mode}'")if__name__=="__main__":main()
# Copyright (c) 2023 PaddlePaddle Authors. All Rights Reserved.## Licensed under the Apache License, Version 2.0 (the "License");# you may not use this file except in compliance with the License.# You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.# Two-stage training# 1. Train a embedding model by running train_enn.py.# 2. Load pretrained embedding model and freeze it, then train a transformer model by running train_transformer.py.# This file is for step2: training a transformer model, based on frozen pretrained embedding model.# This file is based on PaddleScience/ppsci API.fromosimportpathasospfromtypingimportDictimporthydraimportpaddlefromomegaconfimportDictConfigimportppscifromppsci.archimportbasefromppsci.utilsimportloggerfromppsci.utilsimportsave_loaddefbuild_embedding_model(embedding_model_path:str)->ppsci.arch.LorenzEmbedding:input_keys=("states",)output_keys=("pred_states","recover_states")regularization_key="k_matrix"model=ppsci.arch.LorenzEmbedding(input_keys,output_keys+(regularization_key,))save_load.load_pretrain(model,embedding_model_path)returnmodelclassOutputTransform(object):def__init__(self,model:base.Arch):self.model=modelself.model.eval()def__call__(self,x:Dict[str,paddle.Tensor]):pred_embeds=x["pred_embeds"]pred_states=self.model.decoder(pred_embeds)returnpred_statesdeftrain(cfg:DictConfig):# train time-series: 2048 time-steps: 256 block-size: 64 stride: 64# valid time-series: 64 time-steps: 1024 block-size: 256 stride: 1024# test time-series: 256 time-steps: 1024# set random seed for reproducibilityppsci.utils.misc.set_random_seed(cfg.seed)# initialize loggerlogger.init_logger("ppsci",osp.join(cfg.output_dir,f"{cfg.mode}.log"),"info")embedding_model=build_embedding_model(cfg.EMBEDDING_MODEL_PATH)output_transform=OutputTransform(embedding_model)# manually build constraint(s)train_dataloader_cfg={"dataset":{"name":"LorenzDataset","input_keys":cfg.MODEL.input_keys,"label_keys":cfg.MODEL.output_keys,"file_path":cfg.TRAIN_FILE_PATH,"block_size":cfg.TRAIN_BLOCK_SIZE,"stride":64,"embedding_model":embedding_model,},"sampler":{"name":"BatchSampler","drop_last":True,"shuffle":True,},"batch_size":cfg.TRAIN.batch_size,"num_workers":4,}sup_constraint=ppsci.constraint.SupervisedConstraint(train_dataloader_cfg,ppsci.loss.MSELoss(),name="Sup",)constraint={sup_constraint.name:sup_constraint}# set iters_per_epoch by dataloader lengthITERS_PER_EPOCH=len(constraint["Sup"].data_loader)# manually init modelmodel=ppsci.arch.PhysformerGPT2(**cfg.MODEL)# init optimizer and lr schedulerclip=paddle.nn.ClipGradByGlobalNorm(clip_norm=0.1)lr_scheduler=ppsci.optimizer.lr_scheduler.CosineWarmRestarts(iters_per_epoch=ITERS_PER_EPOCH,**cfg.TRAIN.lr_scheduler)()optimizer=ppsci.optimizer.Adam(lr_scheduler,grad_clip=clip,**cfg.TRAIN.optimizer)(model)# manually build validatoreval_dataloader_cfg={"dataset":{"name":"LorenzDataset","file_path":cfg.VALID_FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.MODEL.output_keys,"block_size":cfg.VALID_BLOCK_SIZE,"stride":1024,"embedding_model":embedding_model,},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,"num_workers":4,}mse_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,ppsci.loss.MSELoss(),metric={"MSE":ppsci.metric.MSE()},name="MSE_Validator",)validator={mse_validator.name:mse_validator}# set visualizer(optional)states=mse_validator.data_loader.dataset.dataembedding_data=mse_validator.data_loader.dataset.embedding_datavis_data={"embeds":embedding_data[:cfg.VIS_DATA_NUMS,:-1,:],"states":states[:cfg.VIS_DATA_NUMS,1:,:],}visualizer={"visualize_states":ppsci.visualize.VisualizerScatter3D(vis_data,{"pred_states":lambdad:output_transform(d),"states":lambdad:d["states"],},num_timestamps=1,prefix="result_states",)}solver=ppsci.solver.Solver(model,constraint,cfg.output_dir,optimizer,lr_scheduler,cfg.TRAIN.epochs,ITERS_PER_EPOCH,eval_during_train=cfg.TRAIN.eval_during_train,eval_freq=cfg.TRAIN.eval_freq,validator=validator,visualizer=visualizer,)# train modelsolver.train()# evaluate after finished trainingsolver.eval()# visualize prediction after finished trainingsolver.visualize()defevaluate(cfg:DictConfig):# directly evaluate pretrained model(optional)logger.init_logger("ppsci",osp.join(cfg.output_dir,f"{cfg.mode}.log"),"info")embedding_model=build_embedding_model(cfg.EMBEDDING_MODEL_PATH)output_transform=OutputTransform(embedding_model)# manually init modelmodel=ppsci.arch.PhysformerGPT2(**cfg.MODEL)# manually build validatoreval_dataloader_cfg={"dataset":{"name":"LorenzDataset","file_path":cfg.VALID_FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.MODEL.output_keys,"block_size":cfg.VALID_BLOCK_SIZE,"stride":1024,"embedding_model":embedding_model,},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,"num_workers":4,}mse_validator=ppsci.validate.SupervisedValidator(eval_dataloader_cfg,ppsci.loss.MSELoss(),metric={"MSE":ppsci.metric.MSE()},name="MSE_Validator",)validator={mse_validator.name:mse_validator}# set visualizer(optional)states=mse_validator.data_loader.dataset.dataembedding_data=mse_validator.data_loader.dataset.embedding_datavis_datas={"embeds":embedding_data[:cfg.VIS_DATA_NUMS,:-1,:],"states":states[:cfg.VIS_DATA_NUMS,1:,:],}visualizer={"visulzie_states":ppsci.visualize.VisualizerScatter3D(vis_datas,{"pred_states":lambdad:output_transform(d),"states":lambdad:d["states"],},num_timestamps=1,prefix="result_states",)}solver=ppsci.solver.Solver(model,output_dir=cfg.output_dir,validator=validator,visualizer=visualizer,pretrained_model_path=cfg.EVAL.pretrained_model_path,)solver.eval()# visualize prediction for pretrained model(optional)solver.visualize()defexport(cfg:DictConfig):# set modelembedding_model=build_embedding_model(cfg.EMBEDDING_MODEL_PATH)model_cfg={**cfg.MODEL,"embedding_model":embedding_model,"input_keys":["states"],"output_keys":["pred_states"],}model=ppsci.arch.PhysformerGPT2(**model_cfg)# initialize solversolver=ppsci.solver.Solver(model,pretrained_model_path=cfg.INFER.pretrained_model_path,)# export modelfrompaddle.staticimportInputSpecinput_spec=[{key:InputSpec([None,255,3],"float32",name=key)forkeyinmodel.input_keys},]solver.export(input_spec,cfg.INFER.export_path)definference(cfg:DictConfig):fromdeploy.python_inferimportpinn_predictorpredictor=pinn_predictor.PINNPredictor(cfg)dataset_cfg={"name":"LorenzDataset","file_path":cfg.VALID_FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.MODEL.output_keys,"block_size":cfg.VALID_BLOCK_SIZE,"stride":1024,}dataset=ppsci.data.dataset.build_dataset(dataset_cfg)input_dict={"states":dataset.data[:cfg.VIS_DATA_NUMS,:-1,:],}output_dict=predictor.predict(input_dict,cfg.INFER.batch_size)# mapping data to cfg.INFER.output_keysoutput_keys=["pred_states"]output_dict={store_key:output_dict[infer_key]forstore_key,infer_keyinzip(output_keys,output_dict.keys())}input_dict={"states":dataset.data[:cfg.VIS_DATA_NUMS,1:,:],}data_dict={**input_dict,**output_dict}foriinrange(cfg.VIS_DATA_NUMS):ppsci.visualize.save_plot_from_3d_dict(f"./lorenz_transformer_pred_{i}",{key:value[i]forkey,valueindata_dict.items()},("states","pred_states"),)@hydra.main(version_base=None,config_path="./conf",config_name="transformer.yaml")defmain(cfg:DictConfig):ifcfg.mode=="train":train(cfg)elifcfg.mode=="eval":evaluate(cfg)elifcfg.mode=="export":export(cfg)elifcfg.mode=="infer":inference(cfg)else:raiseValueError(f"cfg.mode should in ['train', 'eval', 'export', 'infer'], but got '{cfg.mode}'")if__name__=="__main__":main()