PhyCRNet¶
# linux
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/PhyCRNet/burgers_1501x2x128x128.mat -P ./data/
# windows
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/PhyCRNet/burgers_1501x2x128x128.mat --create-dirs -o ./data/burgers_1501x2x128x128.mat
python main.py DATA_PATH=./data/burgers_1501x2x128x128.mat
# linux
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/PhyCRNet/burgers_1501x2x128x128.mat -P ./data/
# windows
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/PhyCRNet/burgers_1501x2x128x128.mat --create-dirs -o ./data/burgers_1501x2x128x128.mat
python main.py mode=eval DATA_PATH=./data/burgers_1501x2x128x128.mat EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/phycrnet/phycrnet_burgers.pdparams
| Pretrained Model | Metrics |
|---|---|
| phycrnet_burgers_pretrained.pdparams | a-RMSE: 3.20e-3 |
1. Background Introduction¶
Complex spatiotemporal systems can often be modeled by partial differential equations (PDEs), which are common in many fields such as applied mathematics, physics, biology, chemistry, and engineering. Solving PDE systems has always been a key component of the field of scientific computing. The specific goal of this paper is to propose a novel physics-informed convolutional-recurrent learning architecture (PhyCRNet) and its lightweight variant (PhyCRNet-s) for solving multi-dimensional spatiotemporal PDEs without any labeled data. The main goal of this project is to use PaddleScience to reproduce the code provided in the paper and align it with the accuracy of the code.
The network has the following advantages:
-
Using ConvLSTM (encoder-decoder Convolutional Long Short-Term Memory network) can fully extract features in low-dimensional space and learn their changes over time.
-
Use a global residual iteration so that the iterative process in time can be strictly enforced.
-
Use filtering based on high-order finite difference schemes to accurately solve important partial differential equation derivative values.
-
Using enforced boundary conditions ensures that the numerical solution obtained satisfies the initial values and boundary conditions required by the original equation.
2. Problem Definition¶
In this model, we consider PDE models containing time and space. Such models will have the problem of error accumulation over time during the inference process. Therefore, this paper attempts to mitigate the error accumulation of each time iteration step by designing a recurrent convolutional neural network. The problem we solve is the two-dimensional Burgers' Equation with initial values randomly obtained from a Gaussian distribution:
The two-dimensional Burgers' Equation characterizes complex nonlinear reaction-diffusion interaction problems and is therefore often used as a benchmark to compare various scientific computing algorithms.
3. Problem Solving¶
3.1 Model Construction¶
In this section, we introduce the architecture of PhyCRNet, including the encoder-decoder module, residual connections, autoregressive (AR) process, and filter-based differentiation. The network architecture is shown in the figure. The encoder (yellow Encoder, containing 3 convolutional layers) is used to learn low-dimensional latent features from input state variables \(u(t=i), i = 0,1,2,..,T-1\), where \(T\) represents the total time steps. We apply ReLU as the activation function for the convolutional layers. Then, we pass the output of the ConvLSTM layer (low resolution obtained by Encoder) to the time propagator of latent features (green part), where the memory unit \(C_i\) of the output LSTM and the hidden variable unit \(h_i\) of the LSTM will serve as inputs for the next time step. The benefit of doing this is to model the basic dynamics of low-dimensional variables, accurately capturing temporal dependencies while helping to reduce memory burden. Another advantage of using LSTM comes from the hyperbolic tangent function of the output state, which can maintain a smooth gradient curve and control values between -1 and 1. After establishing the low-resolution LSTM convolutional recurrent scheme, we directly reconstruct the low-resolution latent space into high-resolution quantities based on the upsampling operation Decoder (blue part). Specifically, sub-pixel convolutional layers (i.e., pixel shuffle) are applied because they have better efficiency and reconstruction accuracy with fewer artifacts compared to deconvolution. Finally, we add another convolutional layer used to scale the bounded latent variable space output back to the original physical space. There is no activation function after this Decoder. In addition, it is worth mentioning that given the limited number of input variables and their drawbacks for super-resolution, we did not consider batch normalization in PhyCRNet. Instead, we use batch normalization to train the network to achieve training acceleration and better convergence. Inspired by the Forward Euler Scheme in dynamics, we attach a global residual connection between the input state variable \(u_i\) and the output variable \(u_{i+1}\). The specific network structure is shown in the figure below:

Next, the remaining challenge is how to perform physical embedding to integrate the accuracy improvement brought by the N-S equation. We apply gradient-free convolution filters to represent discrete numerical differentiation to approximate derivative terms of interest. For example, the filters based on Finite Difference considered in this paper are 2nd-order and 4th-order central difference schemes to calculate time and space derivatives.
Time difference:
Space difference:
Where \(\delta t\) and \(\delta x\) represent time step and space step.
In addition, it should be noted that the derivative on the boundary cannot be directly calculated. The risk of losing boundary difference information can be mitigated by the ghost point filling mechanism often used in traditional finite differences introduced next. Its main core is to fill one or more layers of ghost points around the matrix (the number of layers depends on the difference scheme, i.e., the size of the filter). Taking the figure below as an example, under Dirichlet boundary conditions (Dirichlet BCs), we only need to fill constant ghost points around the original matrix; under Neumann boundary conditions (Neumann BCs), we need to determine the value of ghost points based on their boundary condition derivative values.

3.2 Data Loading¶
We use data generated by RK4 or spectral methods (initial values generated using normal distribution), which needs to be read from .mat files:
3.3 Constraint Construction¶
Set constraints and related loss functions:
3.4 Validator Construction¶
Set evaluation dataset and related loss functions:
3.6 Optimizer Construction¶
The training process will call the optimizer to update model parameters. Here, the Adam optimizer is selected and learning_rate is set.
3.7 Model Training and Evaluation¶
To evaluate the solution accuracy produced by all neural network-based solvers, we evaluated full-field error propagation in two stages: training and extrapolation. The full-field error \(\epsilon_\tau\) at time τ is defined as the accumulated root mean square error (a-RMSE) given b.
This step needs to be done by setting an external function, so during the training process, we use function.transform_out for training
And in the evaluation process, we use function.tranform_output_val for evaluation and generate accumulated root mean square error.
After completing the above settings, you only need to pass the instantiated objects to ppsci.solver.Solver in order.
Finally, start training and evaluation:
4. Complete Code¶
| phycrnet | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 | |
5. Result Display¶
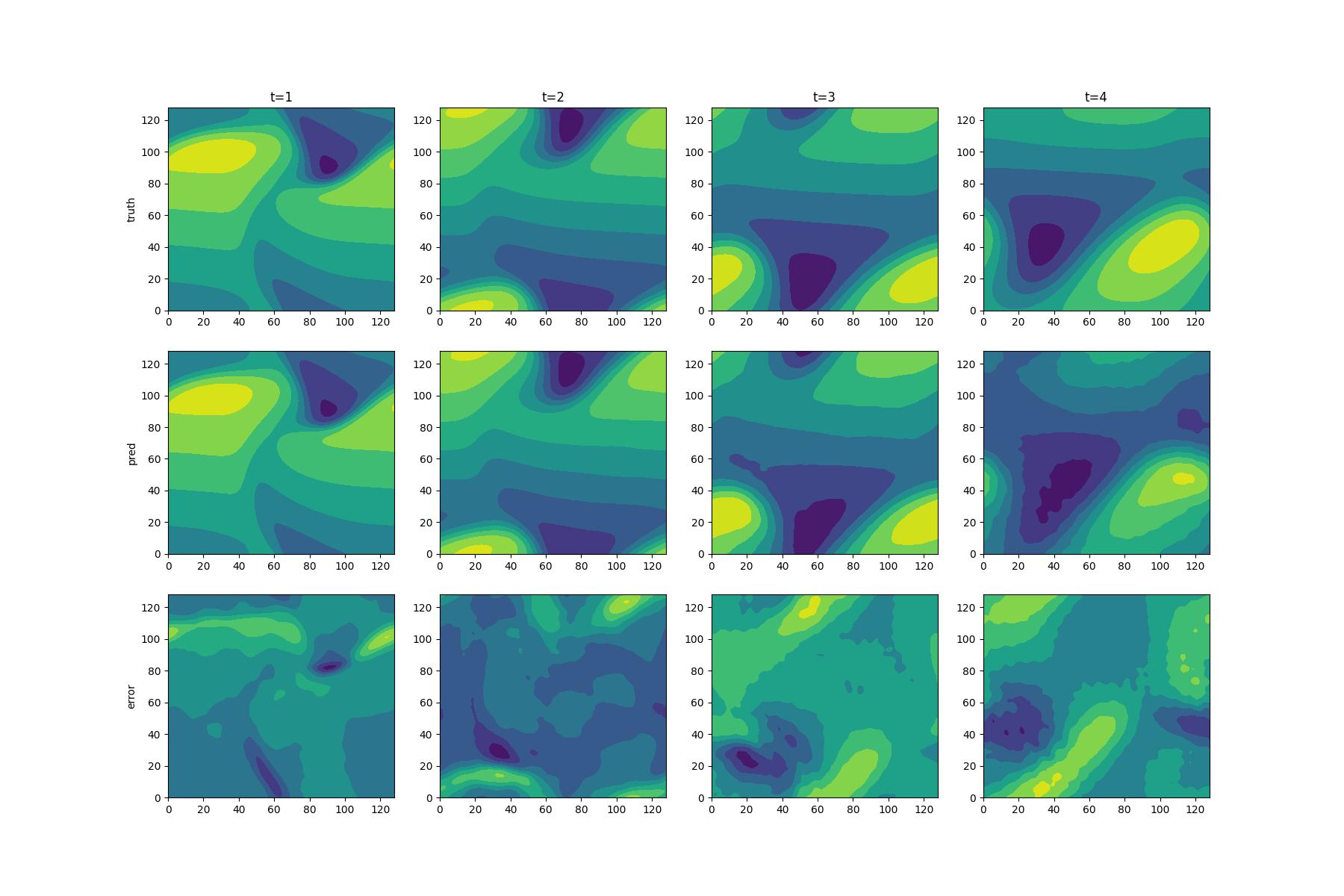
This paper trains on Burgers' Equation, and the results obtained are as follows. Based on the comparison of accuracy and scalability, we can conclude that our model performs well on both the training set (t=1.0, 2.0) and the extrapolation set (t=3.0, 4.0). pred is the contour map of the first component u of the velocity predicted by the network on the domain, truth is the contour map of the true first component u of the velocity on the domain, and Error is the difference between the predicted value and the true value across the entire domain.
6. Result Description¶
Solving partial differential equations is a fundamental problem in scientific computing, and neural network solving of partial differential equations has significant effects on challenging problems in traditional methods such as inverse problems and data assimilation problems. However, existing neural network solving methods are limited by issues such as scalability, error propagation, and generalization ability. Therefore, this paper proposes a new neural network PhyCRNet, which embeds the idea of traditional finite differences into physics-informed neural networks to specifically solve the problems of original neural networks lacking inference ability for long-time data, error accumulation, and lack of generalization ability. At the same time, this paper converts the original soft constraints of boundary conditions into hard constraints through a boundary processing method similar to finite differences, greatly improving the accuracy of the neural network. The newly proposed network can effectively solve the data assimilation problems and inverse problems mentioned above.