Preformer¶
Before starting training and evaluation, please download the ERA5 dataset file.
Before starting evaluation, please download or train to generate a pre-trained model.
The dataset used for evaluation has been saved and can be downloaded and evaluated through the following links: rain_2016_01.h5, ERA5_201601.tar.gz, mean.nc, std.nc.
After downloading or decompressing, please maintain the following directory form: ERA5/ ├── mean.nc ├── std.nc ├── rain_2016_01.h5 └── 2016/ ├── r_2016010100.npy ├── ...
1. Background Introduction¶
Precipitation is a weather phenomenon closely related to human production and life. Accurate prediction of short-term precipitation not only provides key technical support for public services such as agricultural management, traffic planning, and disaster prevention, but is also a challenging academic research task. In recent years, deep learning has made major breakthroughs in the field of meteorological prediction. Taking multi-modal three-dimensional (altitude, longitude and latitude) meteorological data as the research object, researching short-term precipitation prediction methods based on deep learning has important theoretical research value and broad application prospects.
Preformer, a spatiotemporal Transformer network for short-term precipitation prediction, consists of an encoder, an evolver, and a decoder. Specifically, the encoder encodes spatial features by exploring dependencies between embeddings. Global temporal dynamics are learned from rearranged embeddings through the evolver. Finally, in the decoder, spatiotemporal representations are decoded into future precipitation.
2. Model Principle¶
This chapter briefly introduces the model principle of Preformer.
2.1 Encoder¶
This module uses two layers of Transformers to extract spatial features and update node features:
2.2 Evolver¶
This module uses two layers of Transformers to learn global temporal dynamics:
2.3 Decoder¶
This module uses two layers of convolution to decode spatiotemporal representations into future precipitation:
2.4 Preformer Model Structure¶
The overall structure of the model is shown in the figure:
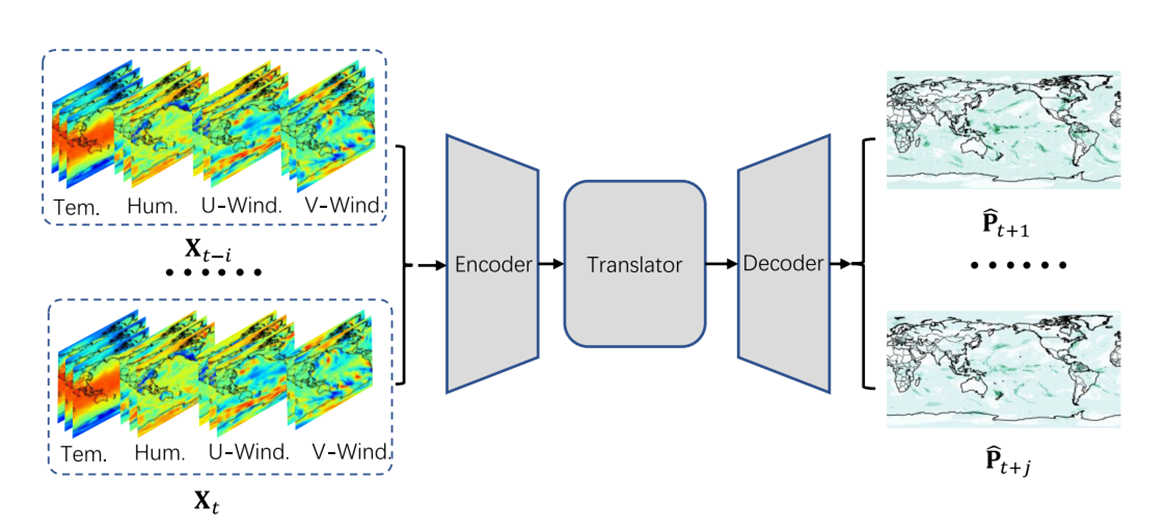
The Preformer model first uses a feature embedding layer to encode spatial features of input signals (meteorological elements of the past few hours):
Then the model uses the evolver to learn the dynamic characteristics of spatial features and predict the meteorological characteristics of the next few hours:
| ppsci/arch/preformer.py | |
|---|---|
Finally, the model combines spatiotemporal dynamic characteristics with initial meteorological underlying features, and uses two layers of convolution to predict future short-term precipitation intensity:
| ppsci/arch/preformer.py | |
|---|---|
3. Model Training¶
3.1 Dataset Introduction¶
The case uses the preprocessed ERA5SQ dataset, which belongs to a subset of ERA5 reanalysis data. ERA5SQ contains multiple variables of global atmosphere, land and ocean. The study area ranges from 140°E to 70°W, and from 55°N to the equator, with a spatial resolution of 0.25°. The dataset starts from 2016 to 2020, providing estimates of weather conditions every hour, which is very suitable for tasks such as precipitation prediction and analysis of total water vapor.
The dataset is saved as a T x C x H x W matrix, recording rainfall and meteorological element values at the corresponding location and time, where T is the time series length, C represents the channel dimension, the case selects meteorological information such as temperature, relative humidity, eastward wind speed, northward wind speed of 3 different pressure layers, H and W represent the height and width of the matrix divided by latitude and longitude. According to the year, the dataset is divided into training set, validation set, and test set at a ratio of 7:2:1. In the case, the mean and standard deviation of rainfall data, etc., were pre-calculated for subsequent regularization operations.
3.2 Model Training¶
3.2.1 Model Construction¶
This case is implemented based on the Preformer model, expressed in PaddleScience code as follows:
3.2.2 Constraint Builder Construction¶
This case solves the problem based on data-driven methods, so it is necessary to use SupervisedConstraint built in PaddleScience to construct supervised constraint builders. Before defining the constraint builder, you need to first specify various parameters used for data loading in the constraint builder.
The code for loading training set data is as follows:
The code for defining supervised constraints is as follows:
| examples/preformer/main.py | |
|---|---|
3.2.3 Validator Construction¶
In this case, the validation set is used to evaluate the training status of the current model at certain training epoch intervals during the training process, and SupervisedValidator is needed to construct the validator.
The code for loading validation set data is as follows:
| examples/preformer/main.py | |
|---|---|
The code for defining supervised validator is as follows:
| examples/preformer/main.py | |
|---|---|
3.2.4 Learning Rate and Optimizer Construction¶
In this case, the learning rate size is set to 1e-3, and the optimizer uses Adam, expressed in PaddleScience code as follows:
| examples/preformer/main.py | |
|---|---|
3.2.5 Model Training¶
After completing the above settings, you only need to pass the instantiated objects to ppsci.solver.Solver, and then start training.
3.2.6 Evaluation During Training¶
By setting the eval_during_train parameter in ppsci.solver.Solver, the model parameters with the best effect on the validation set can be automatically saved.
| examples/preformer/main.py | |
|---|---|
3.3 Evaluating Model¶
3.3.1 Validator Construction¶
The code for loading test set data is as follows:
| examples/preformer/main.py | |
|---|---|
The code for defining supervised validator is as follows:
| examples/preformer/main.py | |
|---|---|
Similar to SupervisedValidator of validation set, the evaluation indicators used here are MAE and MSE.
3.3.2 Load Model and Evaluate¶
Set the loading path of pre-trained model parameters and load the model.
Instantiate ppsci.solver.Solver, and then start evaluation.
4. Complete Code¶
Dataset interface:
| ppsci/data/dataset/era5sq_dataset.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 | |
Model structure:
| ppsci/arch/preformer.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 | |
Model training:
| examples/preformer/main.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 | |
Configuration file:
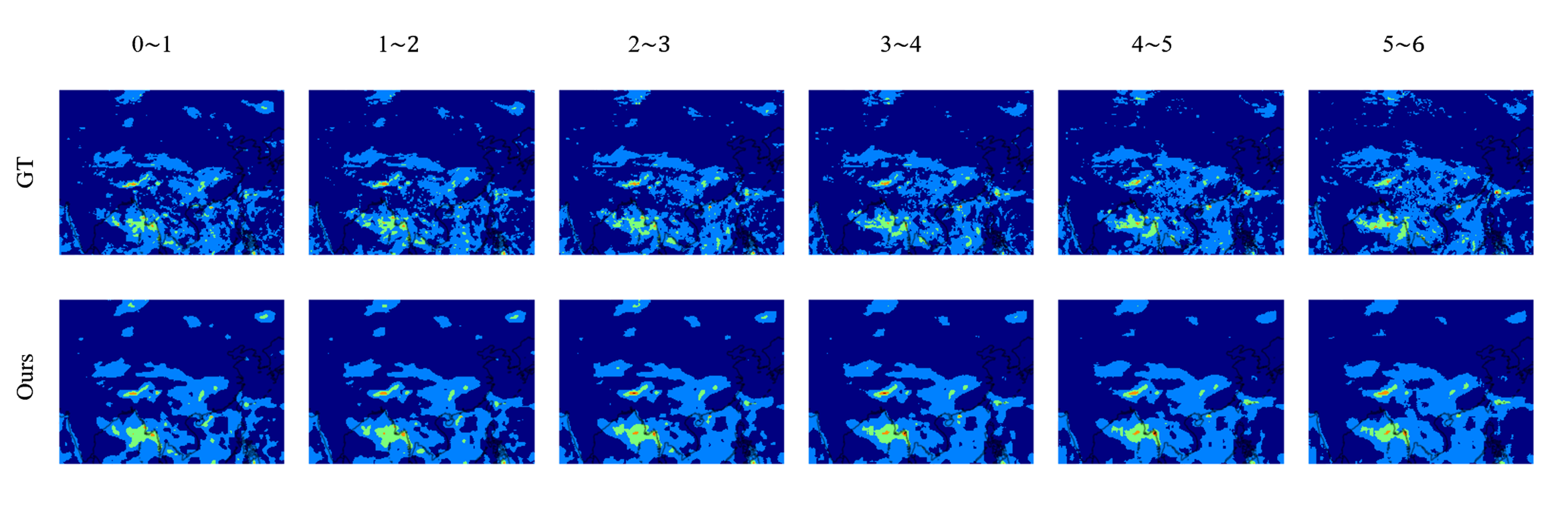
5. Result Display¶
The figure below shows the comparison between the prediction results of the Preformer model in the short-term precipitation prediction task and the ground truth results. The horizontal axis in the figure represents different time periods, with each time period interval being 1 hour, and the model predicts 6 frames of precipitation each time.