Volterra integral equation is an integral equation, that is, the equation contains the integral operation of the function to be solved. It has two forms, as shown below
\[
\begin{aligned}
f(t) &= \int_a^t K(t, s) x(s) d s \\
x(t) &= f(t)+\int_a^t K(t, s) x(s) d s
\end{aligned}
\]
In the field of mathematics, the Volterra equation can be used to express various multivariate probability distributions and is a powerful tool for multivariate statistical analysis. This makes it very useful when dealing with complex data structures, such as in the field of machine learning. The Volterra equation can also be used to calculate the correlation of attributes of different dimensions and simulate complex dataset structures to provide effective data support for machine learning tasks.
In the field of biology, the Volterra equation is used as a guide for fishery production and is of great significance to ecological balance and environmental protection. In addition, the equation also has applications in disease prevention and control, population statistics, etc. It is worth mentioning that the establishment of the Volterra equation was the first successful attempt to apply mathematics in the field of biology, promoting the emergence and development of the science of biomathematics.
This case takes the second equation as an example and uses deep learning for solving.
\[
u(t) = -\dfrac{du}{dt} + \int_{t_0}^t e^{t-s} u(s) d s
\]
Where \(u(t)\) is the function to be solved, \(-\dfrac{du}{dt}\) corresponds to \(f(t)\), and \(e^{t-s}\) corresponds to \(K(t,s)\).
Therefore, a neural network model can be used, with \(t\) as input and \(u(t)\) as output, construct differential constraints according to the above equation, and perform unsupervised learning to finally fit the function \(u(t)\) to be solved.
In order to facilitate solving in a computer, we move the terms of the above formula, putting the integral term on the left side and the non-integral term on the right side, as shown below:
\[
\int_{t_0}^t e^{t-s} u(s) d s = u(t) + \dfrac{du}{dt}
\]
Next, we will explain how to convert the problem into PaddleScience code step by step and solve the problem using deep learning methods.
In order to quickly understand PaddleScience, only key steps such as model construction, equation construction, and computational domain construction are described below, while other details please refer to API Documentation.
In order to accurately and quickly access the value of specific variables during calculation, we specify here that the input variable name of the network model is "x" (i.e. \(t\) in the formula), and the output variable name is "u". Then by specifying the number of hidden layers and number of neurons of MLP, we instantiate the neural network model model.
The integration domain of the Volterra_IDE problem is \(a\) ~ \(t\), where a is a fixed constant 0, and the range of t is 0 ~ 5, so the built-in one-dimensional geometry TimeDomain of PaddleScience can be used as the computational domain.
Since Volterra_IDE uses an integral equation, ppsci.equation.Volterra built into PaddleScience can be used directly, and specify the required parameters: lower limit of integration a, number of discrete points of tnum_points, number of one-dimensional Gaussian integration points quad_deg, \(K(t,s)\) kernel function kernel_func, \(u(t) - f(t)\) right side expression of the equation func.
# set equationdefkernel_func(x,s):returnnp.exp(s-x)deffunc(out):x,u=out["x"],out["u"]returnjacobian(u,x)+uequation={"volterra":ppsci.equation.Volterra(cfg.BOUNDS[0],cfg.TRAIN.npoint_interior,cfg.TRAIN.quad_deg,kernel_func,func,)}
This paper uses unsupervised learning to constrain the left and right sides of the equation after moving terms to be as equal as possible.
Since the left side of the equation involves integral calculation (actually using Gaussian integration approximate calculation), after sampling multiple t_i points in the 0 ~ 5 interval, it is also necessary to calculate the point set used for Gaussian integration, that is, for each (0, t_i) interval, calculate the one-to-one corresponding Gaussian integration point set quad_i and point weight weight_i. PaddleScience adds this step as preprocessing of input data to the code, as shown below
After the differential equation constraint and initial value constraint are constructed, encapsulate them into a dictionary with the name we just named as the keyword for subsequent access.
Next, we need to specify the number of training epochs and learning rate. Here, based on experimental experience, let the L-BFGS optimizer perform one round of optimization, but the number of max_iters in one round of optimization can be set to a larger number 15000.
# training settingsTRAIN:epochs:1iters_per_epoch:1save_freq:1eval_during_train:trueeval_freq:1optimizer:learning_rate:1max_iter:15000max_eval:1250tolerance_grad:1.0e-8tolerance_change:0history_size:100quad_deg:20npoint_interior:12npoint_ic:1pretrained_model_path:null
Usually during the training process, the training status of the current model is evaluated using the validation set (test set) at a certain epoch interval, so ppsci.validate.GeometryValidator is used to construct the validator.
# set validatorl2rel_validator=ppsci.validate.GeometryValidator({"u":lambdaout:out["u"]},{"u":u_solution_func},geom["timedomain"],{"dataset":"IterableNamedArrayDataset","total_size":cfg.EVAL.npoint_eval,},ppsci.loss.L2RelLoss(),evenly=True,metric={"L2Rel":ppsci.metric.L2Rel()},name="L2Rel_Validator",)validator={l2rel_validator.name:l2rel_validator}
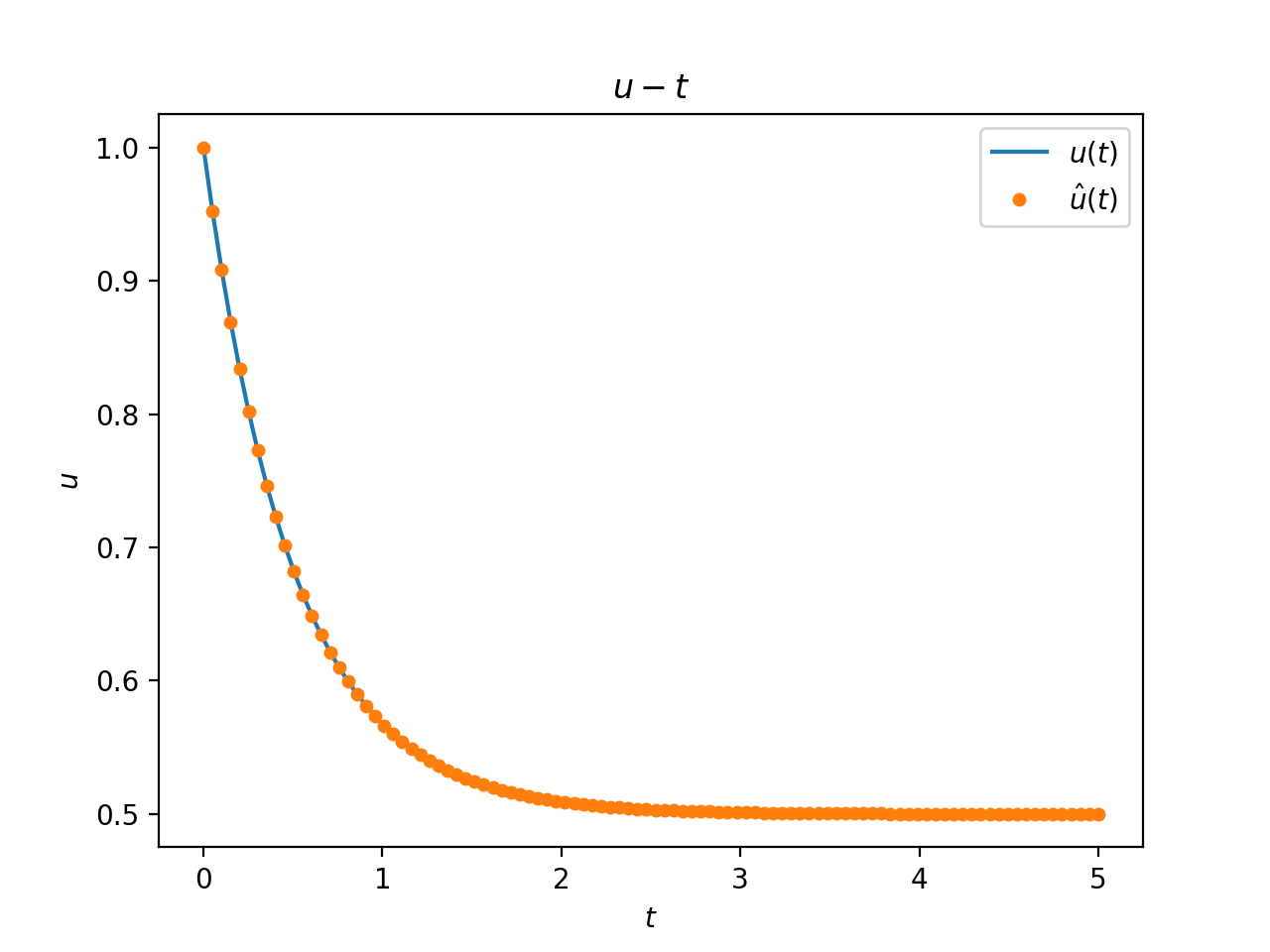
After the model training is completed, we can manually construct 100 points uniformly in the 0 ~ 5 interval as the integration upper limit t for evaluation to predict and visualize the results.
# Copyright (c) 2023 PaddlePaddle Authors. All Rights Reserved.## Licensed under the Apache License, Version 2.0 (the "License");# you may not use this file except in compliance with the License.# You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.# Reference: https://github.com/lululxvi/deepxde/blob/master/examples/pinn_forward/Volterra_IDE.pyfromosimportpathasospfromtypingimportDictfromtypingimportTupleimporthydraimportnumpyasnpimportpaddlefrommatplotlibimportpyplotaspltfromomegaconfimportDictConfigimportppscifromppsci.autodiffimportjacobianfromppsci.utilsimportloggerdeftrain(cfg:DictConfig):# set random seed for reproducibilityppsci.utils.misc.set_random_seed(cfg.seed)# set output directorylogger.init_logger("ppsci",osp.join(cfg.output_dir,"train.log"),"info")# set modelmodel=ppsci.arch.MLP(**cfg.MODEL)# set geometrygeom={"timedomain":ppsci.geometry.TimeDomain(*cfg.BOUNDS)}# set equationdefkernel_func(x,s):returnnp.exp(s-x)deffunc(out):x,u=out["x"],out["u"]returnjacobian(u,x)+uequation={"volterra":ppsci.equation.Volterra(cfg.BOUNDS[0],cfg.TRAIN.npoint_interior,cfg.TRAIN.quad_deg,kernel_func,func,)}# set constraint# set transform for input datadefinput_data_quad_transform(input:Dict[str,np.ndarray],weight:Dict[str,np.ndarray],label:Dict[str,np.ndarray],)->Tuple[Dict[str,paddle.Tensor],Dict[str,paddle.Tensor],Dict[str,paddle.Tensor]]:"""Get sampling points for integral. Args: input (Dict[str, paddle.Tensor]): Raw input dict. weight (Dict[str, paddle.Tensor]): Raw weight dict. label (Dict[str, paddle.Tensor]): Raw label dict. Returns: Tuple[ Dict[str, paddle.Tensor], Dict[str, paddle.Tensor], Dict[str, paddle.Tensor] ]: Input dict contained sampling points, weight dict and label dict. """x=input["x"]# N points.x_quad=equation["volterra"].get_quad_points(x).reshape([-1,1])# NxQx_quad=paddle.concat((x,x_quad),axis=0)# M+MxQ: [M|Q1|Q2,...,QM|]return({**input,"x":x_quad,},weight,label,)# interior constraintide_constraint=ppsci.constraint.InteriorConstraint(equation["volterra"].equations,{"volterra":0},geom["timedomain"],{"dataset":{"name":"IterableNamedArrayDataset","transforms":({"FunctionalTransform":{"transform_func":input_data_quad_transform,},},),},"batch_size":cfg.TRAIN.npoint_interior,"iters_per_epoch":cfg.TRAIN.iters_per_epoch,},ppsci.loss.MSELoss("mean"),evenly=True,name="EQ",)# initial conditiondefu_solution_func(in_):ifisinstance(in_["x"],paddle.Tensor):returnpaddle.exp(-in_["x"])*paddle.cosh(in_["x"])returnnp.exp(-in_["x"])*np.cosh(in_["x"])ic=ppsci.constraint.BoundaryConstraint({"u":lambdaout:out["u"]},{"u":u_solution_func},geom["timedomain"],{"dataset":{"name":"IterableNamedArrayDataset"},"batch_size":cfg.TRAIN.npoint_ic,"iters_per_epoch":cfg.TRAIN.iters_per_epoch,},ppsci.loss.MSELoss("mean"),criteria=geom["timedomain"].on_initial,name="IC",)# wrap constraints togetherconstraint={ide_constraint.name:ide_constraint,ic.name:ic,}# set optimizeroptimizer=ppsci.optimizer.LBFGS(**cfg.TRAIN.optimizer)(model)# set validatorl2rel_validator=ppsci.validate.GeometryValidator({"u":lambdaout:out["u"]},{"u":u_solution_func},geom["timedomain"],{"dataset":"IterableNamedArrayDataset","total_size":cfg.EVAL.npoint_eval,},ppsci.loss.L2RelLoss(),evenly=True,metric={"L2Rel":ppsci.metric.L2Rel()},name="L2Rel_Validator",)validator={l2rel_validator.name:l2rel_validator}# initialize solversolver=ppsci.solver.Solver(model,constraint,cfg.output_dir,optimizer,epochs=cfg.TRAIN.epochs,iters_per_epoch=cfg.TRAIN.iters_per_epoch,eval_during_train=cfg.TRAIN.eval_during_train,eval_freq=cfg.TRAIN.eval_freq,equation=equation,geom=geom,validator=validator,pretrained_model_path=cfg.TRAIN.pretrained_model_path,checkpoint_path=cfg.TRAIN.checkpoint_path,eval_with_no_grad=cfg.EVAL.eval_with_no_grad,)# train modelsolver.train()# visualize prediction after finished traininginput_data=geom["timedomain"].uniform_points(100)label_data=u_solution_func({"x":input_data})output_data=solver.predict({"x":input_data},return_numpy=True)["u"]plt.plot(input_data,label_data,"-",label=r"$u(t)$")plt.plot(input_data,output_data,"o",label=r"$\hat{u}(t)$",markersize=4.0)plt.legend()plt.xlabel(r"$t$")plt.ylabel(r"$u$")plt.title(r"$u-t$")plt.savefig(osp.join(cfg.output_dir,"./Volterra_IDE.png"),dpi=200)defevaluate(cfg:DictConfig):# set random seed for reproducibilityppsci.utils.misc.set_random_seed(cfg.seed)# set output directorylogger.init_logger("ppsci",osp.join(cfg.output_dir,"eval.log"),"info")# set modelmodel=ppsci.arch.MLP(**cfg.MODEL)# set geometrygeom={"timedomain":ppsci.geometry.TimeDomain(*cfg.BOUNDS)}# set validatordefu_solution_func(in_)->np.ndarray:ifisinstance(in_["x"],paddle.Tensor):returnpaddle.exp(-in_["x"])*paddle.cosh(in_["x"])returnnp.exp(-in_["x"])*np.cosh(in_["x"])l2rel_validator=ppsci.validate.GeometryValidator({"u":lambdaout:out["u"]},{"u":u_solution_func},geom["timedomain"],{"dataset":"IterableNamedArrayDataset","total_size":cfg.EVAL.npoint_eval,},ppsci.loss.L2RelLoss(),evenly=True,metric={"L2Rel":ppsci.metric.L2Rel()},name="L2Rel_Validator",)validator={l2rel_validator.name:l2rel_validator}# initialize solversolver=ppsci.solver.Solver(model,output_dir=cfg.output_dir,geom=geom,validator=validator,pretrained_model_path=cfg.EVAL.pretrained_model_path,eval_with_no_grad=cfg.EVAL.eval_with_no_grad,)# evaluate modelsolver.eval()# visualize predictioninput_data=geom["timedomain"].uniform_points(cfg.EVAL.npoint_eval)label_data=u_solution_func({"x":input_data})output_data=solver.predict({"x":input_data},return_numpy=True)["u"]plt.plot(input_data,label_data,"-",label=r"$u(t)$")plt.plot(input_data,output_data,"o",label=r"$\hat{u}(t)$",markersize=4.0)plt.legend()plt.xlabel(r"$t$")plt.ylabel(r"$u$")plt.title(r"$u-t$")plt.savefig(osp.join(cfg.output_dir,"./Volterra_IDE.png"),dpi=200)defexport(cfg:DictConfig):# set modelmodel=ppsci.arch.MLP(**cfg.MODEL)# initialize solversolver=ppsci.solver.Solver(model,pretrained_model_path=cfg.INFER.pretrained_model_path,)# export modelfrompaddle.staticimportInputSpecinput_spec=[{key:InputSpec([None,1],"float32",name=key)forkeyincfg.MODEL.input_keys},]solver.export(input_spec,cfg.INFER.export_path)definference(cfg:DictConfig):fromdeploy.python_inferimportpinn_predictorpredictor=pinn_predictor.PINNPredictor(cfg)# set geometrygeom={"timedomain":ppsci.geometry.TimeDomain(*cfg.BOUNDS)}input_data=geom["timedomain"].uniform_points(cfg.EVAL.npoint_eval)input_dict={"x":input_data}output_dict=predictor.predict({key:input_dict[key]forkeyincfg.MODEL.input_keys},cfg.INFER.batch_size)# mapping data to cfg.INFER.output_keysoutput_dict={store_key:output_dict[infer_key]forstore_key,infer_keyinzip(cfg.MODEL.output_keys,output_dict.keys())}defu_solution_func(in_)->np.ndarray:ifisinstance(in_["x"],paddle.Tensor):returnpaddle.exp(-in_["x"])*paddle.cosh(in_["x"])returnnp.exp(-in_["x"])*np.cosh(in_["x"])label_data=u_solution_func({"x":input_data})output_data=output_dict["u"]# save resultplt.plot(input_data,label_data,"-",label=r"$u(t)$")plt.plot(input_data,output_data,"o",label=r"$\hat{u}(t)$",markersize=4.0)plt.legend()plt.xlabel(r"$t$")plt.ylabel(r"$u$")plt.title(r"$u-t$")plt.savefig("./Volterra_IDE_pred.png",dpi=200)@hydra.main(version_base=None,config_path="./conf",config_name="volterra_ide.yaml")defmain(cfg:DictConfig):ifcfg.mode=="train":train(cfg)elifcfg.mode=="eval":evaluate(cfg)elifcfg.mode=="export":export(cfg)elifcfg.mode=="infer":inference(cfg)else:raiseValueError(f"cfg.mode should in ['train', 'eval', 'export', 'infer'], but got '{cfg.mode}'")if__name__=="__main__":main()
The model prediction results are shown below. \(t\) is the independent variable, \(u(t)\) is the standard solution function of the integral equation, and \(\hat{u}(t)\) is the model predicted integral equation solution function
Model solution result (orange scatter) and reference result (blue curve)
It can be seen that the model's prediction result \(\hat{u}(t)\) for the integral equation in the \([0,5]\) interval is basically consistent with the standard solution result \(u(t)\).