Combining Differentiable PDE Solvers and Graph Neural Networks for Fluid Flow Prediction¶
# only linux
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/CFDGCN/data.zip
unzip data.zip
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/CFDGCN/meshes.tar
tar -xvf meshes.tar
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/CFDGCN/SU2Bin.tgz
tar -zxvf SU2Bin.tgz
# set BATCH_SIZE = number of cpu cores
export BATCH_SIZE=4
# prediction experiments
mpirun -np $((BATCH_SIZE+1)) python cfdgcn.py \
TRAIN.batch_size=$((BATCH_SIZE)) > /dev/null
# generalization experiments
mpirun -np $((BATCH_SIZE+1)) python cfdgcn.py \
TRAIN.batch_size=$((BATCH_SIZE)) \
TRAIN_DATA_DIR="./data/NACA0012_machsplit_noshock/outputs_train" \
TRAIN_MESH_GRAPH_PATH="./data/NACA0012_machsplit_noshock/mesh_fine. su2" \
EVAL_DATA_DIR="./data/NACA0012_machsplit_noshock/outputs_test" \
EVAL_MESH_GRAPH_PATH="./data/NACA0012_machsplit_noshock/mesh_fine.su2" \
> /dev/null
1. Background Introduction¶
In recent years, the successful application of deep learning in computer vision and natural language processing has prompted people to explore the application of artificial intelligence in the field of scientific computing, especially in the field of Computational Fluid Dynamics (CFD).
Fluid is a very complex physical system, and the behavior of fluid is governed by the Navier-Stokes equations. Grid-based finite volume or finite element simulation methods are widely used numerical methods in CFD. The physical problems studied by computational fluid dynamics are often very complex and usually require a lot of computing resources to find the solution to the problem, so a trade-off between solution accuracy and computational cost is needed. In order to perform numerical simulation, the computational domain is usually discretized by grids. Since the grid has good geometric and physical problem representation capabilities and is compatible with the graph structure, the authors of this article use graph neural networks to construct a data-driven model for flow field prediction by training CFD simulation data.
2. Problem Definition¶
The authors propose a graph neural network-based CFD calculation model called CFD-GCN (Computational fluid dynamics - Graph convolution network). This model is a hybrid graph neural network that combines traditional graph convolution networks with coarse-resolution CFD simulators. It can not only greatly accelerate CFD prediction but also generalize well to new scenarios. At the same time, the prediction effect of the model is far better than the simulation effect of coarse-resolution CFD alone.
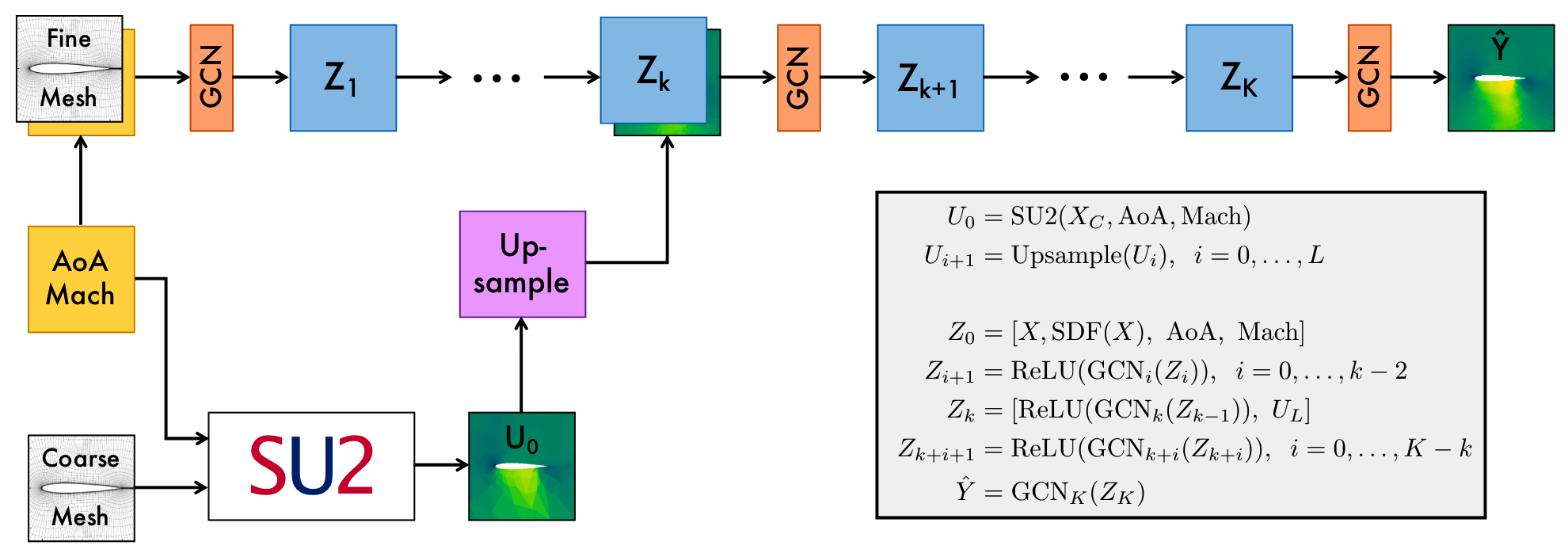
The figure below shows the network structure of this method. The network has two main components: GCN graph neural network and SU2 fluid simulator. The network operates on two different graphs, which are the graph of the fine grid and the graph of the coarse grid. The network first runs a CFD simulation on the coarse grid while processing the graph of the fine grid using GCN. Then, the simulation results are upsampled and concatenated with the intermediate output of GCN. Finally, the model applies additional GCN layers to these concatenated features to predict the desired output values.
3. Problem Solving¶
Next, we will explain how to convert the problem into PaddleScience code step by step and solve the problem using deep learning methods. In order to quickly understand PaddleScience, only key steps such as model construction, equation construction, and computational domain construction are described below, while other details please refer to API Documentation.
Note
Before running this case, you need to install Paddle Graph Learning graph learning tool and Mpi4py MPI python interface library via pip install pgl==2.2.6 mpi4py command.
Since the new version of Paddle relies on a higher python version, the installation of pgl and mpi4py may have problems. It is recommended to use AI Studio Quick Experience, where the running environment has been configured in the project.
3.1 Dataset Download¶
The airfoil dataset used in this case comes from de Avila Belbute-Peres et al., where the airfoil dataset uses NACA0012 airfoil, including train, test and corresponding grid data mesh_fine; the cylinder dataset is a CFD calculation example calculated by the original author using software.
Execute the following command to download and unzip the dataset.
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/CFDGCN/data.zip
unzip data.zip
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/CFDGCN/meshes.tar
tar -xvf meshes.tar
3.2 SU2 Precompiled Library Installation¶
The SU2 version of this case is too low (v6.2.0), so specific versions of openmpi and mpi4py need to be installed (openmpi 1.10.2 and mpi4py 3.1.4).
The SU2 fluid simulator is embedded in the network in the form of a precompiled library. We need to download and set environment variables.
Execute the following command to download and unzip the precompiled library.
wget -c -P https://paddle-org.bj.bcebos.com/paddlescience/datasets/CFDGCN/SU2Bin.tgz
tar -zxvf SU2Bin.tgz
After the precompiled library is downloaded, set the environment variables of SU2.
export SU2_RUN=/absolute_path/to/SU2Bin/
export SU2_HOME=/absolute_path/to/SU2Bin/
export PATH=$PATH:$SU2_RUN
export PYTHONPATH=$PYTHONPATH:$SU2_RUN
3.3 Model Construction¶
In this problem, we use the neural network CFDGCN as the model, which receives graph structure data and outputs prediction results.
In order to access the value of specific variables accurately and quickly during calculation, we specify the input variable name of the network model as ("input", ) and the output variable name as ("pred", ), these names are consistent with the subsequent code.
3.4 Constraint Construction¶
In this case, we use supervised datasets to train the model, so we need to build supervised constraints.
Before defining constraints, we need to specify the path of the dataset and other related configurations, and store this information in the corresponding YAML file, as shown below.
Then define the calculation process of training loss function, as shown below.
Finally construct supervised constraints, as shown below.
3.5 Hyperparameter Setting¶
Set parameters such as training rounds, as shown below.
3.6 Optimizer Construction¶
The training process will call the optimizer to update model parameters. Here, the Adam optimizer is selected, and a fixed 5e-4 is used as the learning rate.
3.7 Validator Construction¶
Usually during the training process, the training status of the current model is evaluated using the validation set (test set) at a certain epoch interval, so ppsci.validate.SupervisedValidator is used to construct the validator. The construction process is similar to Constraint Construction, just change the data directory to the directory of the test set, and set EVAL.batch_size=1 in the configuration file.
The evaluation metric is the RMSE value of the predicted result and the real result, so a custom metric calculation function needs to be defined, as shown below.
The evaluation metric is the RMSE value of the predicted result and the real result, so a custom metric calculation function needs to be defined, as shown below.
3.8 Model Training¶
After completing the above settings, you only need to pass the instantiated objects to ppsci.solver.Solver in order, and then start training.
3.9 Result Visualization¶
After training, the program will predict the data in the test set and visualize the results in the form of images, as shown below.
4. Complete Code¶
| cfdgcn.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 | |
5. Result Display¶
The following shows the prediction results and reference results of the model for pressure \(p(x,y)\), x (horizontal) direction velocity \(u(x,y)\), and y (vertical) direction velocity \(v(x,y)\) at each point in the computational domain.
It can be seen that the model prediction results are basically consistent with the real results, and the model generalization effect is good.