FengWu¶
None
None
None
# Download sample input data
wget -c https://paddle-org.bj.bcebos.com/paddlescience/models/Fengwu/input1.npy -P ./data
wget -c https://paddle-org.bj.bcebos.com/paddlescience/models/Fengwu/input2.npy -P ./data
# Download pretrain model weight
wget -c https://paddle-org.bj.bcebos.com/paddlescience/models/Fengwu/fengwu_v2.onnx -P ./inference
# inference
python predict.py
1. Background Introduction¶
With the intensification of global climate change and the frequent occurrence of extreme weather in recent years, the expectations of all sectors for the timeliness and accuracy of weather forecasts are increasing day by day. How to improve the timeliness and accuracy of weather forecasts has always been a key topic in the industry. The AI large model "FengWu" is built based on multi-modal and multi-task deep learning methods, achieving effective forecasting of core atmospheric variables for more than 10 days at high resolution, and surpassing GraphCast, a model released by DeepMind, on 80% of the evaluation indicators. At the same time, "FengWu" can generate high-precision global forecast results for the next 10 days in just 30 seconds, which is significantly better than traditional models in efficiency.
2. Model Principle¶
This chapter only briefly introduces the principle of the FengWu meteorological large model. For detailed theoretical derivation, please read FengWu: Pushing the Skillful Global Medium-range Weather Forecast beyond 10 Days Lead.
The overall structure of the model is shown in the figure:
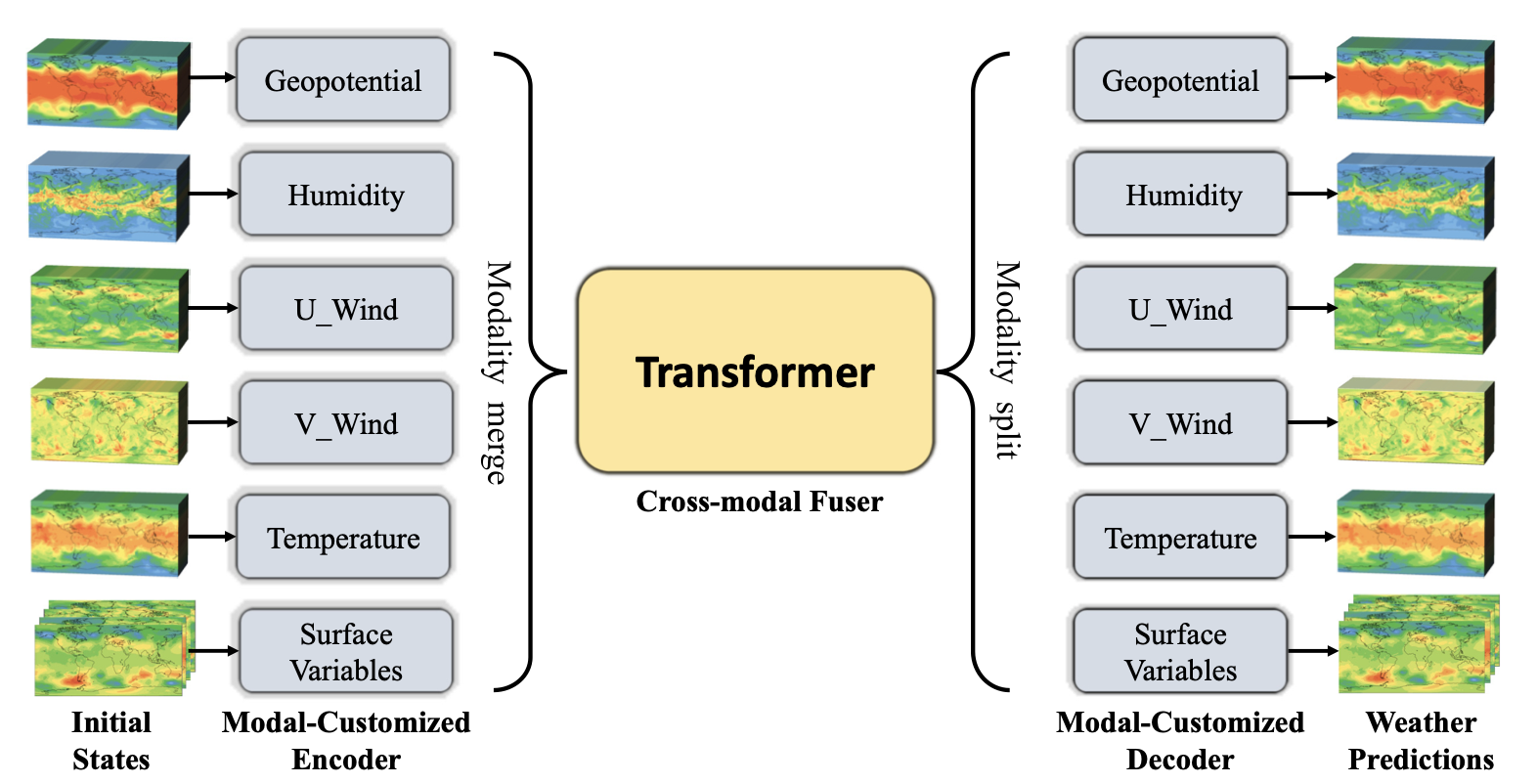
The model takes climate variables as multi-modal inputs. The features of multiple modalities are encoded in the Modal-Customized Encoder, and the encoded features are fused using the Transformer-based Cross-modal Fuser to obtain a joint representation. Finally, climate variables are predicted separately from the joint representation in the Modal-Customized Decoder.
The model uses pre-trained weights for inference. Next, the inference process of the model will be introduced.
3. Model Construction¶
In this case, FengWuPredictor is implemented for inference of the ONNX model:
Among them, input_file and input_next_file represent the meteorological data at the start time and the meteorological data 6 hours later input to the network model respectively.
4. Result Visualization¶
The model inference result contains 56 npy files, representing meteorological data every 6 hours for the next 14 days starting from the prediction time point. Result visualization requires first converting the data from npy to NetCDF format, and then using ncvue for viewing.
-
Install dependencies
-
Use script for data conversion
-
Use ncvue to open the converted NetCDF file. For detailed instructions on ncvue, see ncvue official documentation
5. Complete Code¶
| examples/fengwu/predict.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 | |
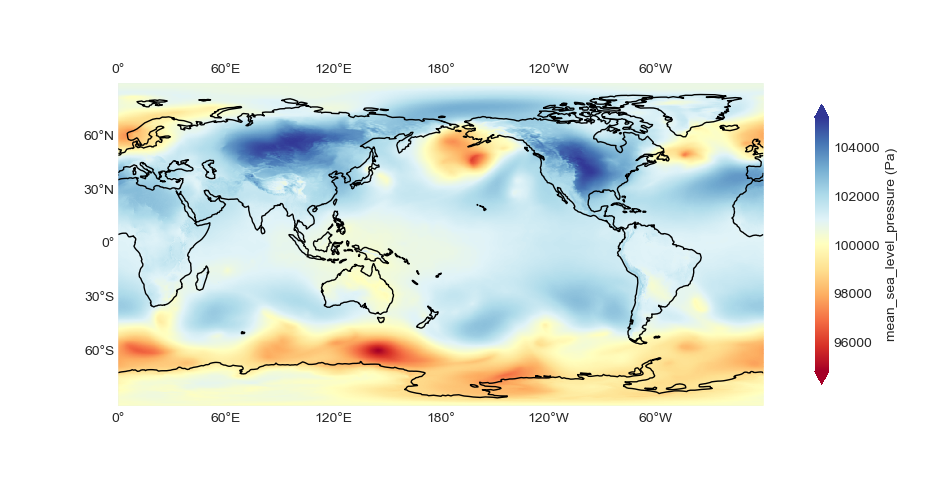
6. Result Display¶
The figure below shows the model's prediction result of the average sea level pressure for the next 6 hours. More indicators can be viewed using ncvue.